构建代码优先的AI智能体
为什么你的 LLM 应该编写代码,而不是调用工具

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
大多数 AI 智能体框架今天使用工具调用:LLM 输出结构化 JSON,描述调用哪个函数以及使用什么参数。你的应用程序解析此 JSON 并执行函数。
这种方法有效,但它违背了自然的趋势。LLM 是在数十亿行代码上训练的。工具调用是一种返工。
本指南解释了为什么代码生成对于智能体通常是一种更好的架构、何时使用它以及如何安全地实现它。
1、使用工具调用的核心问题
工具调用将每个行动视为单独的对话回合。模式看起来像这样:
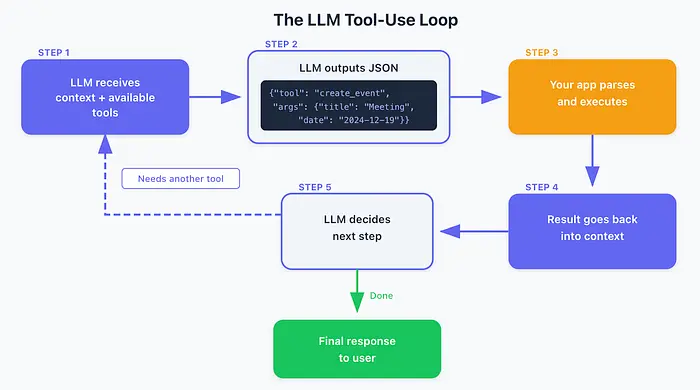
- LLM 接收上下文和可用工具
- LLM 输出 JSON:
{"tool": "create_event", "args": {"title": "Meeting", "date": "2024-12-19"}} - 你的应用程序解析并执行
- 结果返回到上下文中
- LLM 决定下一步
- 重复
对于多步骤任务,这会产生复合成本。每个步骤都需要对整个对话历史进行一次完整的推理传递。Hugging Face 关于 GAIA 基准的研究发现,使用代码操作的智能体需要比基于 JSON 的工具调用少 30% 的步骤,直接转换为少 30% 的 token 和更低的成本。
差距随着复杂性的扩大而扩大。Cloudflare 的 Code Mode 演示显示,在简单的单步骤任务上节省了 32% 的 token,但在复杂的多步骤任务上节省了 81%(创建 31 个日历事件)。步骤越多,对话性开销累积得越多。
2、为什么代码是更好的操作格式
Hugging Face smolagents 库清楚地阐明了这一点:
"我们专门制作了我们的编程语言,以擅长表达由计算机执行的操作。如果 JSON 片段是更好的方式,这个包本应以 JSON 片段编写。"
代码相比工具调用提供了三个结构性优势:
2.1 控制流
工具调用是单拍的。代码具有循环、条件和错误处理。
工具调用方法(31 个单独的 LLM 回合):
{"tool": "create_event", "args": {"title": "Tech Meetup Day 1", "date": "2026-01-01"}}
{"tool": "create_event", "args": {"title": "Tech Meetup Day 2", "date": "2026-01-02"}}
// ... 29 个更多的回合
代码生成方法(1 个 LLM 回合):
const topics = ["AI Fundamentals", "MCP Deep Dive", "Data Pipelines", ...];
for (let day = 1; day <= 31; day++) {
const date = new Date(2026, 0, day);
await createEvent({
title: `Tech Meetup: ${topics[day % topics.length]}`,
date: date.toISOString()
});
}
2.2 运行时访问
工具调用参数在生成时是静态的,在生成时定义。代码可以访问运行时信息。
这就是为什么 Cloudflare 的 Code Mode 演示使用工具调用失败但使用代码生成成功。提示是"为今晚创建一个事件"。工具调用智能体产生了一个日期。代码生成智能体调用了 new Date() 并获得了实际当前日期。
2.3 组合
代码自然地组合。函数调用函数。变量存储中间结果。工具调用强迫 LLM 通过对话在每一步手动编排每一步。
# Code 可以定义可重用逻辑
def process_user(user_id):
profile = fetch_profile(user_id)
if profile.needs_update:
enriched = enrich_with_external_data(profile)
save_profile(enriched)
return profile
# And组合它
for user_id in active_users:
process_user(user_id)
使用工具调用时,这些操作中的每一个都需要单独的 LLM 回合,并且模型必须在其上下文窗口中跨回合跟踪状态。
3、关键要点
在深入实施之前,这里是核心原则:
工具调用最佳用于 简单、单步操作
- 高安全环境,需要严格约束
- 当每个步骤的可观察性至关重要时
- 使用工具调用:** 多步骤工作流,需要迭代或条件逻辑
- 当需要运行时信息时
- 大规模的高成本应用
代码生成最佳用于 多步骤工作流
- 需要迭代或条件逻辑的任务
- 当需要运行时信息时
在实施之前,这里是核心原则:
工具调用最佳用于 简单、单步操作(单个 API 调用)
- 高安全环境,需要严格约束
- 当每个步骤的可观察性至关重要时
代码生成最佳用于 多步骤工作流
- 需要迭代或条件逻辑的任务
- 当需要运行时信息时
- 大规模的高成本应用
使用工具调用时:
- 简单、原子操作(单个 API 调用)*
- 高安全环境,需要严格约束
- 当每个步骤的可观察性至关重要时*
- 使用工具调用:** 多步骤工作流,需要迭代或条件逻辑*
- 当需要运行时信息时*
- 成本敏感应用,需要规模
使用代码生成时:
- 多步骤工作流*
- 需要迭代或条件逻辑的任务
- 当需要运行时信息时*
4、实施架构
代码优先的智能体具有三个组件:
┌─────────────┐ ┌──────────────┐ ┌─────────────┐
│ LLM │────▶│ Sandbox │────▶│ APIs/ │
│ (generates │ │ (executes │ │ code) │ │ │
│ code) │ │ code) │ │ │
└─────────────┘ └──────────────┘ └─────────────┘
- LLM 基于任务和可用 API 生成代码
- 沙箱 在隔离环境中执行该代码
- API/服务 由执行的代码调用
关键部分是沙箱。你正在执行 LLM 生成的代码,这本质上是冒险的。沙箱提供隔离。
4.1 沙箱选项
存在几种生产就绪的选项:
E2B(基于云)
E2B 提供在 Firecracker 微型 VM 上构建的云沙箱。每个沙箱在大约 150 毫秒内启动,具有硬件级隔离。
import { Sandbox } from '@e2b/code-interpreter';
const sandbox = await Sandbox.create();
const result = await sandbox.runCode(`
import pandas as pd
df = pd.read_csv('data.csv')
df.describe()
`);
关键特征:
- ~150 毫秒冷启动
- 完整 Linux 环境
- 默认网络隔离
- Python 和 Node.js 支持
Cloudflare Workers(基于边缘)
Cloudflare 的 Dynamic Worker Loader 在 V8 隔离环境中运行代码。比容器更轻,具有毫秒启动时间。
// Parent worker 加载并运行生成的代码
const worker = await env.WORKER_LOADER.get(executionId, {
code: generatedTypeScript,
globalOutbound: null // 网络完全禁用
});
const result = await worker.fetch(request);
关键特征:
- 毫秒冷启动
- V8 隔离隔离(不是容器)
- 网络可以完全禁用
- 目前仅 TypeScript/JavaScript
- 目前处于封闭测试版
本地执行(开发)
对于开发和测试,smolagents 提供受限的 Python 解释器:
from smolagents import CodeAgent, LocalPythonExecutor
executor = LocalPythonExecutor(
allowed_imports=["pandas", "numpy"], # 白名单导入
max_execution_time=30
)
agent = CodeAgent(tools=[], executor=executor)
这使用 AST 解析来限制操作。不像真正的隔离那样安全,但对开发有用。
4.2 安全模型
关键洞察:代码生成并不意味着安全性降低。它意味着不同的安全模型。
工具调用安全性:信任外部端点,每个端点都有自己的身份验证、权限和攻击面。
代码生成安全性:信任 1 沙箱化环境,以及定义明确的约束。
必要的沙箱约束:
| 约束目的 | 实现 | 网络隔离 |
|---|---|---|
| 防止数据渗漏,阻止出站请求 | 在 Code Mode 中,沙箱默认阻止所有网络访问。生成的代码只能通过受控接口与预定义 API 交互。这消除了整个类别的漏洞(凭据泄露、SSRF、数据渗漏)。 文件系统限制 | 仅读或作用域写入访问 |
| 沙箱限制文件系统访问。读取文件、创建临时文件、访问受控目录。 资源限制 | CPU、内存、执行时间上限 | 沙箱强制执行资源限制。这可以防止无限循环或资源耗尽。 导入限制 |
| 沙箱限制可以导入的库。这防止代码导入不受信任的包或使用危险函数。 无 shell 访问 | 防止任意命令执行 | 沙箱不支持 bash 或 shell 命令。这可以防止任意命令执行或 shell 注入攻击。 |
Cloudflare 的方法是指令性的:在 Code Mode 中,沙箱默认阻止所有网络访问。生成的代码只能通过受控接口与预定义 API 交互。这消除了整个类别的漏洞(凭据泄露、SSRF、数据渗漏)。
4.3 实用实现模式
这里是一个最小化的代码优先智能体模式:
import openai
from e2b_code_interpreter import Sandbox
SYSTEM_PROMPT = """你是一个代码生成智能体。
给定一个任务,编写 Python 代码来完成它。
你可以访问这些函数:
- fetch_user(user_id) -> dict
- send_email(to, subject, body) -> bool
- query_database(sql) -> list
编写使用这些函数的代码。仅输出代码,不要解释。"""
def run_agent(task: str) -> str:
# 1. 生成代码
response = openai.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": task}
]
)
generated_code = response.choices[0].message.content
# 2. 在沙箱中执行
with Sandbox() as sandbox:
# 注入可用的函数
sandbox.run_code(FUNCTION_DEFINITIONS)
# 运行生成的代码
result = sandbox.run_code(generated_code)
return result.text
# 用法
result = run_agent("Send 本周内登录的所有用户摘要电子邮件")
LLM 生成一次。沙箱执行。
5、何时不使用代码生成
代码生成并不总是正确的选择:
简单的单步操作:如果你只是调用一个 API,工具调用更简单且足够。
需要人工审查的高风险操作:当每个操作都需要人工审查时,单个工具调用的可观察性很有价值。某些合规框架明确要求对每个操作的审计跟踪。工具调用自然地提供了这一点。
严格受监管的环境:一些合规框架要求明确的每项操作的审计跟踪。工具调用自然地提供了这一点。
当沙箱基础设施不可用时:代码生成需要执行基础设施。如果你无法运行 E2B、Cloudflare Workers 或类似的工具调用,那么它对简单操作有效。
混合方法:保持工具调用以进行简单操作,为复杂工作流使用代码生成。测量 token 使用量、延迟和可靠性。
比较:测量 token 使用量、延迟和可靠性。
6、结束语
行业正在向代码优先的架构移动:
- OpenAI 的高级数据分析(前身为 Code Interpreter)生成并执行 Python
- GitHub Copilot Workspace 生成代码以完成任务
- Anthropic 的 Claude 擅长代码生成并用于像 Devin 这样的编码智能体
- Hugging Face smolagents 默认为 JSON 操作选择代码操作
基础设施正在成熟。E2B 提供云沙箱。Cloudflare 正在为 AI 生成的代码构建边缘执行。代码优先智能体所需的执行层正在现在构建中。
工具调用是必要的桥梁。它证明了 LLM 可以与外部系统交互。但 LLM 首先是编码者。最有效和最有能力的智能体将让它们在自己的本机语言中工作。
原文链接: Building Code-First AI Agents
汇智网翻译整理,转载请标明出处
