AI代理的5个难度级别
本文介绍将代理设计分解为五个实用的难度级别,每个级别都提供可运行的代码。

大约两周前,在一个重要产品截止日期之前,我的原型代理以最糟糕的方式崩溃了。
看起来一切正常。它获取数据、调用工具,甚至解释了它的步骤。但在幕后,它在吹牛。没有真实的状态,没有记忆,也没有推理能力。只是假装聪明地循环提示。
我只注意到当一个边缘情况完全让它不知所措时。那时我才意识到:我没有构建一个代理。我构建了一个花哨的提示链。
修复它意味着重新设计整个东西——不仅仅是串联调用,而是管理状态、决策和长期流程。一旦明白了这一点,一切都变得简单了。代码、逻辑、结果都变得更好了。
这就是本指南的内容:将代理设计分解为五个实用的难度级别——每个级别都有可运行的代码。
无论你是刚刚起步还是试图扩展现实世界中的任务,这都会帮助你避免我掉入的陷阱,并构建真正有效的代理。
这些级别是:
- 第1级:带有工具和指令的代理
- 第2级:带有知识和记忆的代理
- 第3级:带有长期记忆和推理能力的代理
- 第4级:多代理团队
- 第5级:代理系统
好了,让我们开始吧。
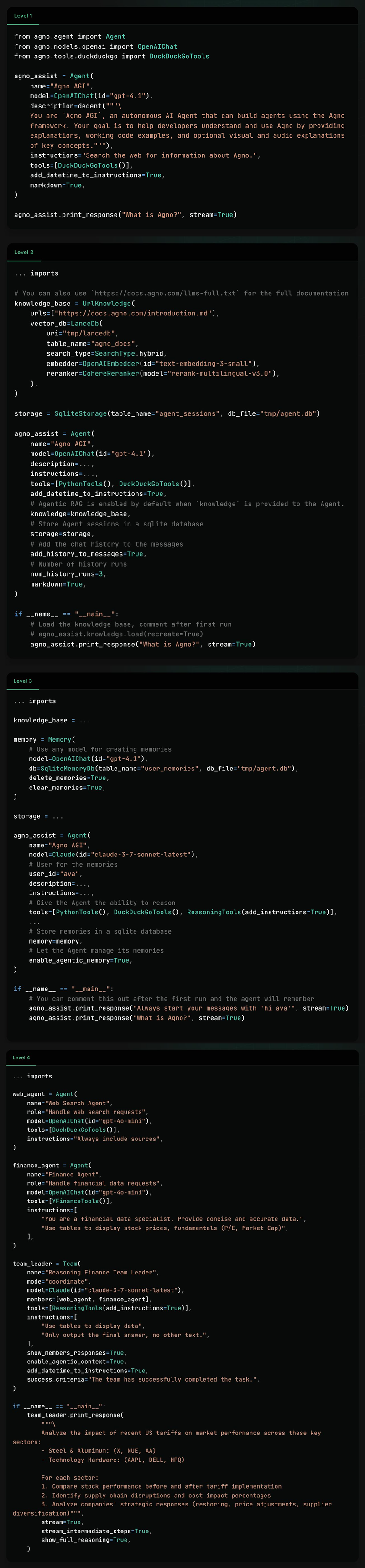
1、带有工具和指令的代理
这是基本设置——一个遵循指令并循环调用工具的LLM。当人们说“代理只是LLM加上工具使用”时,他们谈论的就是这个级别(以及他们探索的程度)。
指令告诉代理该做什么。工具让它采取行动——获取数据、调用API或触发工作流。虽然简单,但已经强大到可以自动完成一些任务。
2、带有知识和记忆的代理
大多数任务需要模型不具备的信息。你不能把所有内容都塞进上下文,所以代理需要一种在运行时获取知识的方法——这就是代理检索增强(agentic RAG)或动态少量样本提示登场的地方。
搜索应该是混合的(全文+语义),并且重排序是必不可少的。结合起来,混合搜索+重排序是代理检索的最佳即插即用设置。
存储给代理提供记忆。LLMs默认是无状态的;存储过去的动作、消息和观察使代理具有状态性——能够引用已经发生的事情并做出更好的决策。
... 导入
# 你也可以使用 https://docs.agno.com/llms-full.txt 获取完整的文档
knowledge_base = UrlKnowledge(
urls=["https://docs.agno.com/introduction.md"],
vector_db=LanceDb(
uri="tmp/lancedb",
table_name="agno_docs",
search_type=SearchType.hybrid,
embedder=OpenAIEmbedder(id="text-embedding-3-small"),
reranker=CohereReranker(model="rerank-multilingual-v3.0"),
),
)
storage = SqliteStorage(table_name="agent_sessions", db_file="tmp/agent.db")
agno_assist = Agent(
name="Agno AGI",
model=OpenAIChat(id="gpt-4.1"),
description=...,
instructions=...,
tools=[PythonTools(), DuckDuckGoTools()],
add_datetime_to_instructions=True,
# 提供‘知识’时,代理检索会自动启用
knowledge=knowledge_base,
# 将代理会话存储在sqlite数据库中
storage=storage,
# 将聊天历史添加到消息中
add_history_to_messages=True,
# 历史记录数量
num_history_runs=3,
markdown=True,
)
if __name_ == "__main__":
# 加载知识库,第一次运行后可以注释掉
# agno_assist.knowledge.load(recreate=True)
agno_assist.print_response("What is Agno?", stream=True)
3、带有长期记忆和推理能力的代理
记忆让代理能够在跨会话中回忆细节——比如用户偏好、过去的行为或失败尝试——并在时间中适应。这开启了个性化和连续性。我们才刚刚开始触及表面,但最让我兴奋的是自我学习:基于过去经验改进行为的代理。
推理更进一步。
它帮助代理分解问题,做出更好的决策,并更可靠地遵循多步指令。这不是简单的理解——而是提高每一步成功几率。每个认真的代理构建者都需要知道何时以及如何应用它。
... 导入
knowledge_base = ...
memory = Memory(
# 使用任何模型创建记忆
model=OpenAIChat(id="gpt-4.1"),
db=SqliteMemoryDb(table_name="user_memories", db_file="tmp/agent.db"),
delete_memories=True,
clear_memories=True,
)
storage =
agno_assist = Agent(
name="Agno AGI",
model=Claude(id="claude-3-7-sonnet-latest"),
# 用户ID用于记忆
user_id="ava",
description=...,
instructions=...,
# 给代理推理能力
tools=[PythonTools(), DuckDuckGoTools(),
ReasoningTools(add_instructions=True)],
...
# 在sqlite数据库中存储记忆
memory=memory,
# 让代理管理自己的记忆
enable_agentic_memory=True,
)
if __name__ == "__main__":
# 第一次运行后可以注释掉,代理会记住
agno_assist.print_response("Always start your messages with 'hi ava'", stream=True)
agno_assist.print_response("What is Agno?", stream=True)
4、多代理团队
代理在专注时最有效——专注于一个领域,工具集紧凑(理想情况下不超过10个)。为了处理更复杂或广泛的任务,我们将它们组合成团队。每个代理处理问题的一部分,一起覆盖更多领域。
但有一个问题:如果没有强大的推理能力,团队领导者在处理微妙的问题时会崩溃。根据我迄今为止看到的一切,自主多代理系统仍然不可靠。成功率不到一半——这还不够好。
话虽如此,有些架构让协调更容易。例如,Agno支持三种执行模式——协调、路由和协作——以及内置的记忆和上下文管理。你仍然需要仔细设计,但这些构建块让严肃的多代理工作更加可行。
... 导入
web_agent = Agent(
name="Web Search Agent",
role="Handle web search requests",
model=OpenAIChat(id="gpt-4o-mini"),
tools=[DuckDuckGoTools()],
instructions="Always include sources",
)
finance_agent = Agent(
name="Finance Agent",
role="Handle financial data requests",
model=OpenAIChat(id="gpt-4o-mini"),
tools=[YFinanceTools()],
instructions=[
"You are a financial data specialist. Provide concise and accurate data.",
"Use tables to display stock prices, fundamentals (P/E, Market Cap)",
],
)
team_leader = Team(
name="Reasoning Finance Team Leader",
mode="coordinate",
model=Claude(id="claude-3-7-sonnet-latest"),
members=[web_agent, finance_agent],
tools=[ReasoningTools(add_instructions=True)],
instructions=[
"Use tables to display data",
"Only output the final answer, no other text.",
],
show_members_responses=True,
enable_agentic_context=True,
add_datetime_to_instructions=True,
success_criteria="The team has successfully completed the task.",
)
if __name__ == "__main__":
team_leader.print_response(
"""\
Analyze the impact of recent US tariffs on market performance across
these key sectors:
- Steel & Aluminum: (X, NUE, AA)
- Technology Hardware: (AAPL, DELL, HPQ)
For each sector:
1. Compare stock performance before and after tariff implementation
2. Identify supply chain disruptions and cost impact percentages
3. Analyze companies' strategic responses (reshoring, price adjustments, supplier
diversification)""",
stream=True,
stream_intermediate_steps=True,
show_full_reasoning=True,
)
5、代理系统
这就是代理从工具转变为基础设施的地方。代理系统是完整的API——系统接收用户请求,启动异步工作流,并在结果可用时流式传输回来。
理论上听起来很干净。实际上,非常困难。
你需要在请求进来时持久化状态,启动后台作业,跟踪进度,并在生成时流式传输输出。WebSocket可以帮助,但它们很难扩展和维护。大多数团队低估了这里的后端复杂性。
这就是将代理变成实际产品的必要条件。在这个级别上,你不是在构建一个功能——而是在构建一个系统。
6、从演示失败到实际胜利:代理设计的关键教训
构建AI代理不是追逐潮流或堆砌功能的问题——而是正确掌握基础知识的问题。从基本的工具使用到完全异步的代理系统,每一级只有在底层架构坚实的情况下才会增加力量。
大多数失败并不是因为缺少最新的框架。它们来自忽视基础知识:明确的界限、扎实的推理、有效的记忆,以及知道何时让人类接管。
如果你从简单开始,有目的地逐步构建,不提前过度复杂化,并且只在解决实际问题时添加复杂性,你不仅会构建一些酷的东西——还会构建一些真正有用的东西。
原文连接:AI Agents in 5 Levels of Difficulty (With Full Code Implementation)
汇智网翻译整理,转载请标明出处
