AI视频生成技术栈深度剖析
本文将探索最新、最强大的生成视频模型的 API、云和自托管选项。从基本的 API 调用到在无服务器 GPU 上运行最新模型,应有尽有。
如果您像我一样全身心投入 AI,那么您可能也会被各种视频生成器的广告所淹没,这些生成器可以执行各种不同的任务。这些工具涵盖从基本的视频调整到高级创作的各种功能。生成视频正在迅速进入房地产、酒店、广告等众多行业。如果您考虑将生成视频集成到您的应用中,请继续关注。我们将探索最新、最强大的生成视频模型的 API、云和自托管选项。从基本的 API 调用到在无服务器 GPU 上运行最新模型,应有尽有。
目前最流行的生成视频模型是 Google Veo 3、Kling AI 和 WAN 2.2。这些模型支持文本转视频 (T2V) 和图像转视频 (I2V)。这些模型的 T2V 工作流程支持提示,指示模型视频应显示哪些活动。生成视频并非神奇的黑匣子,而是所有 NVIDIA H100 GPU 在数据中心执行这些模型。简单来说,这些模型本身就是具有复杂帧预测的图像生成器。运行这些视频模型的关键在于您将使用哪种 GPU、谁的 GPU 以及在哪里运行。让我们深入探讨这个问题。
1、公共 API
最常见的方法是使用模型供应商的 API。对于 Google Veo 3,这也是目前唯一的选择,因为模型源、权重和二进制文件均未由 Google 发布。您必须使用 Gemini API 来运行 Veo 3。目前的价格为每秒 0.40 美元,这意味着一段 10 秒的视频将花费高达 4 美元。以下适用于 Node.js 的 GoogleGenAI 库与 REST 端点一样简单易用。
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({});
const prompt = `Panning wide shot of a calico
kitten sleeping in the sunshine`;
// Step 1: Generate an image with Imagen.
const imagenResponse = await ai.models.generateImages({
model: "imagen-4.0-generate-001",
prompt: prompt,
});
// Step 2: Generate video with Veo 3 using the image.
let operation = await ai.models.generateVideos({
model: "veo-3.0-generate-001",
prompt: prompt,
image: {
imageBytes: imagenResponse.generatedImages[0].image.imageBytes,
mimeType: "image/png",
},
});
// Poll the operation status until the video is ready.
while (!operation.done) {
console.log("Waiting for video generation to complete...")
await new Promise((resolve) => setTimeout(resolve, 10000));
operation = await ai.operations.getVideosOperation({
operation: operation,
});
}
// Download the video.
ai.files.download({
file: operation.response.generatedVideos[0].video,
downloadPath: "veo3_with_image_input.mp4",
});
console.log(`Generated video saved to veo3_with_image_input.mp4`);来自中国快手科技的 Kling AI 也不是开源的,需要通过其 Kling AI API 获取。Kling AI 的定价与包含积分的订阅套餐绑定。这在将模型嵌入到软件中时并不一定能很好地发挥作用。幸运的是,WAN 和 Kling 都可以在 Runpod Hub 上使用。除了 Hub 之外,Runpod 还提供各种 GPU 服务,包括无服务器服务,稍后会详细介绍。
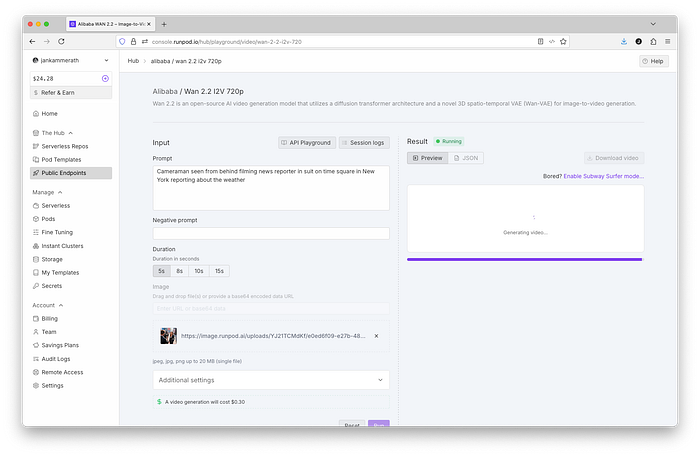
我发现 Runpod Hub API 对于多模态实现特别有用,因为您可以访问各种模型,而不仅仅是视频生成器。遗憾的是,在撰写本文时,Runpod 还没有 Veo 3。如果您还想使用 Veo 3,则必须使用 Google Gemini API 或其他服务,例如 Segmind 或 Civitai。
// sample Go code for the Runpod API
package main
import (
"bytes"
"encoding/json"
"fmt"
"net/http"
)
func main() {
client := &http.Client{}
url := "https://api.runpod.ai/v2/wan-2-2-i2v-720/run"
data := map[string]interface{}{
"input": {
"prompt":"myprompt",
"image":"myimageurl.jpg",
"num_inference_steps":30,
"guidance":5,
"negative_prompt":"",
"size":"1280*720",
"duration":5,
"flow_shift":5,
"seed":-1,
"enable_prompt_optimization":false,
"enable_safety_checker":true
}
}
jsonData, err := json.Marshal(data)
if err != nil {
fmt.Printf("Error marshaling JSON: %v\n", err)
return
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonData))
if err != nil {
fmt.Printf("Error creating request: %v\n", err)
return
}
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Authorization", "Bearer YOUR_API_KEY")
resp, err := client.Do(req)
if err != nil {
fmt.Printf("Error making request: %v\n", err)
return
}
defer resp.Body.Close()
}执行后,该 API 将提供最终输出视频文件的 URL。您可以根据需要使用提供的 mp4 视频。由于 WAN 和 Kling 不会降低画质,您可以使用最后一帧将视频延长至 10 秒以上。这种方法通常用于生成长视频。
使用 API 是将生成视频集成到您的应用程序中最经济、最简单、最快捷的方式。您无需管理和运行自己的 H100 或 L40S GPU 实例,这将为您节省大量成本。尤其是小型应用程序开发者,由于成本和工作量原因,往往不愿运行自己的 GPU 基础架构。但即使是经验丰富的多模式应用程序开发者,也经常会在工作流程中混合使用公共 API 和自托管模型。这并没有绝对的黑白,因为一切都取决于应用程序的用例和工作流程。
2、云和自托管
您迟早会遇到这样的问题:您想使用一些无法通过现成服务和 API 获取的模型。有时,您可能还想使用 ComfyUI 等工具运行复杂的 AI 工作流程。最显而易见的方法是自托管服务器或从 AWS、Azure、Google 或 Scaleway 等云提供商处租用服务器。
2.1 云和自托管 GPU 服务器
在之前的一篇文章中,我概述了如何在 AWS 上使用 ComfyUI 运行稳定的 Diffusion。如果您想灵活地运行各种工作流程或开发多模式解决方案,这种方法非常实用。AWS 上的 EC2 实例也可以在您不需要时关闭,从而节省成本。 ComfyUI 对于在开始编写数千行 Python 代码之前开发和测试复杂的 AI 工作流程非常有帮助。
如果您需要持续的 GPU 性能,那么保持 AWS、Google、Azure、Scaleway 或 Runpod 的固定实例处于活动状态是一个不错的解决方案。但请记住,NVIDIA H100 的成本约为每小时 3 美元,每月超过 2,000 美元。这是一个不小的开销。购买一台在家运行可能会花费超过 10,000 美元。AI 的运行成本仍然很高,而生成视频是最昂贵的工作之一。
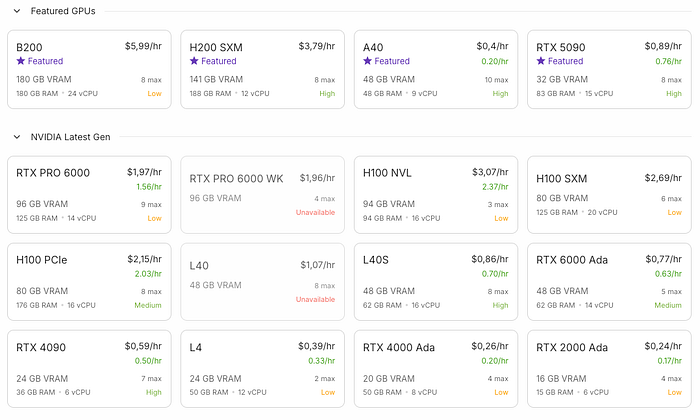
正如我在文章“在您的计算机上进行聊天和图像生成”中概述的那样,您可以在 Mac 或 NVIDA 驱动的 PC 上本地运行许多模型,尤其是 SDXL。然而,视频生成很容易突破家用 GPU 和人们钱包的极限。尤其是在 24/7 全天候运行 GPU 服务器的情况下,就像我在那篇关于将 ComfyUI 作为 systemd 服务或 Linux 守护进程运行的文章中描述的那样。
[Unit]
Description=ComfyUI Service
After=network.target
[Service]
Type=simple
User=ec2-user
WorkingDirectory=/opt/StableDiffusion/ComfyUI
ExecStart=/bin/bash -c 'source activate pytorch; python3 main.py --listen --highvram'
Restart=always
[Install]
WantedBy=multi-user.target在运行自定义模型或训练自己的模型时,有效的成本监控和控制至关重要。如果您的初创公司规模较小或您是独立开发者,并且您的应用只有几个用户,那么您实际上无法投入数千美元来购买 GPU 容量。此外,排队和多模态请求的处理需要手动实现。大多数应用只有在达到一定用户群后才会管理自己的模型农场。
2.2 Runpod 上的无服务器 GPU
小型初创公司或独立开发者开发的应用需要外部计算和远程 API,通常有两种部署方式:要么部署在某个小型 Linux 机器上,要么部署在无服务器环境中,并使用 AWS Lambda、API Gateway 和 DynamoDB 等服务。文章 在 AWS 上使用 Vapor 的无服务器 Swift以 Swift 开发者为例,解释了使用 Lambda 的无服务器方法。对于 GPU 和生成视频来说,5 美元的“小机器”是不存在的,无服务器是您唯一的选择。幸运的是,Runpod 正好提供了这样的服务。
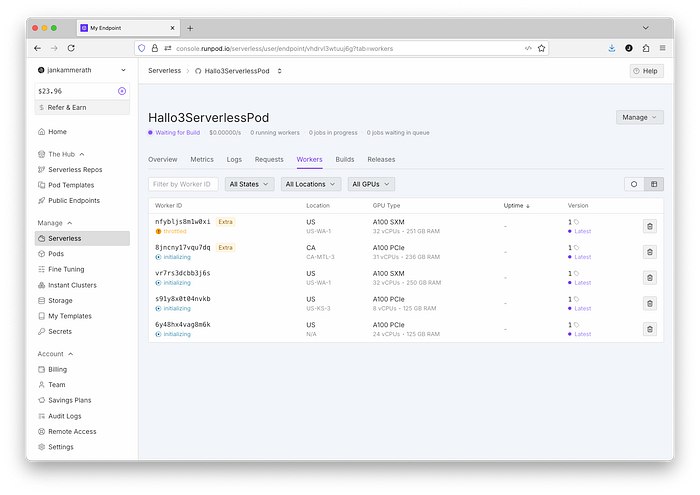
虚拟 AI 角色应用是目前最受欢迎的应用之一,这是一个概述此类应用实际实现的良好示例。这些虚拟形象应用允许用户生成虚拟形象、虚拟形象需要朗读的文字,并生成相应的视频。Qwen 模型可以生成此类图像,Minimax 模型(也在 RunPod Hub 上)可以负责语音部分,而 Hallo3 模型是最新推出的模型之一,它可以将所有这些功能融合到视频中,并使虚拟形象的动作和唇语同步。
虽然 Minimax 和 Qwen 可以通过 RunPod Hub 使用,但 Hallo3 模型只能作为昂贵的持续运行 Pod 或无服务器 Pod 运行。我将引导您完成具体实现。Hallo3 模型的介绍,让您深入了解如何运行无服务器 GPU。RunPod 上的无服务器 Pod 本质上是一个带有 GPU 加速的 Docker 容器,可以直接从提供的 GitHub 代码库构建。
handler.py 脚本是模型执行的入口点。无服务器 Pod 的结构在 RunPod Serverless 上的“Hello World”中进行了概述。基础容器已自带 PyTorch 环境,并且与其静态 Pod 完全相同,从而实现了可移植性,您可以在其静态 Pod 上进行开发和测试,之后再在无服务器 Pod 上部署生产环境。
import runpod
def handler(job):
"""
This is a simple handler that takes a name and returns a greeting.
The job parameter contains the input data in job["input"]
"""
job_input = job["input"]
# Get the name from the input, default to "World" if not provided
name = job_input.get("name", "World")
# Return a greeting message
return f"Hello, {name}! Welcome to RunPod Serverless!"
# Start the serverless function
runpod.serverless.start({"handler": handler})最复杂的部分是让模型在无服务器环境中运行,并正确设置所有依赖项。所有无服务器环境都只是围绕实际模型进行的封装。构建和部署无服务器 Pod 可能非常耗时。因此,最好先在静态 Pod 上测试并运行模型。我强烈建议使用北美或欧洲地区“安全云”池中的 H100,以确保 HuggingFace 和 GitHub 获得最大带宽。我的经验是,其他地区的服务器面临着巨大的带宽挑战。以下命令可从 HuggingFace 和 GitHub 源设置 Hallo3 模型。
# clone the GitHub repository with the model inference
git clone https://github.com/fudan-generative-vision/hallo3
cd hallo3
# update the package manager and get all dependencies
apt update
apt-get update && apt-get install -y ffmpeg libavcodec-dev \
libavformat-dev libswscale-dev
pip install -r requirements.txt
pip install av einops imageio wandb pytorch_lightning \
kornia icecream scipy librosa audio_separator \
onnxruntime opencv-python mediapipe insightface`
pip install moviepy==1.0.3
pip install SwissArmyTransformer
pip install huggingface_hub
# this is downloading all the pretrained model data (circa 50GB)
huggingface-cli download fudan-generative-ai/hallo3 \
--local-dir ./pretrained_models`我在堪萨斯城的一台机器上运行了 HuggingFace 下载,该机器能够从 HuggingFace 获得 800 Mbps 的网速。您需要将所有模型文件放置在靠近 GPU 的位置,否则,在网络和 CPU 获取数据时,GPU 会处于空闲状态,从而浪费大量宝贵的资源。
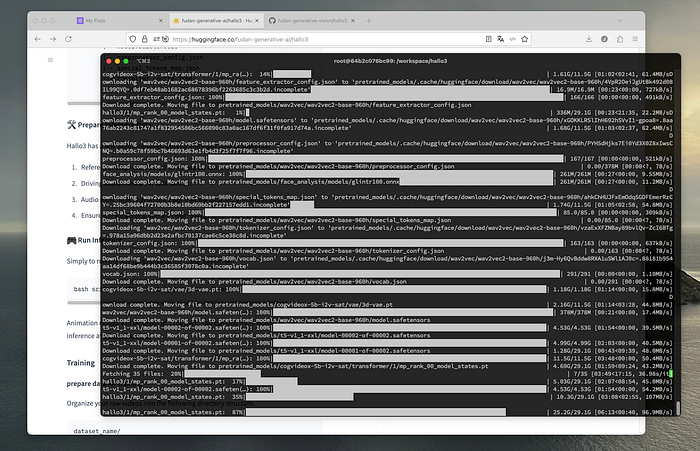
完成所有设置后,audio_processor.py 文件中仍然存在一个小问题,需要手动修复,否则模型将失败。示例推理最初使用了 scaled_dot_product_attention,这是 PyTorch 的默认机制,已针对速度进行了优化。Eager 是标准机制,速度稍慢。我在测试中别无选择,因为 sdpa 会在推理过程中失败,导致推理中止。这正是您在构建生产容器之前需要涵盖的测试场景。
# Line 49 has the following instanciation of the Wav2VecModel
self.audio_encoder = Wav2VecModel.from_pretrained
(wav2vec_model_path, local_files_only=True).to(device=device)
# And needs to be changed to the "eager" attention implementation
self.audio_encoder = Wav2VecModel.from_pretrained
(wav2vec_model_path, attn_implementation="eager",
local_files_only=True).to(device=device)完成此更改后,我们就可以执行推理(模型执行)了。我上传了一个用 Qwen 生成的示例图像文件。Hallo3 模型要求图像的宽高比为 3:2 或 1:1。如果不是,模型将裁剪源图像。我决定和一位善良的年轻人一起去中世纪的德国村庄。

除了静态图像外,该模型还需要一个波形文件作为动画的基础。我使用 RunPod Hub 中的 Minimax 模型生成了一些示例语音输出,然后使用 ffmpeg 将其转换为波形文件。
可以使用 Hallo3 代码库中的 sample_video.py 脚本进行推理,该脚本接受一个文本文件作为输入。该文本文件使用基本的分隔符将提示、输入图像和波形文件分隔开来。我只是用它来进行了一些简单的测试。在无服务器环境中,我稍后会更改输入和输出的处理方式,以便根据我的应用程序的实际使用工作流程调整无服务器部署。
A boy talking in a medieval village@@/workspace/testdata/talk.jpeg@@/workspace/testdata/talk.wav现在,在 Hallo3 工作目录中,我通过执行代码库中的以下 shell 脚本来启动推理。此 bash 脚本是一个辅助程序,除了执行 sample_video.py 脚本外不执行任何其他操作。
bash scripts/inference_long_batch.sh \
/workspace/testdata/talk.txt \
/workspace/output执行后,该脚本将开始使用 CogVideo 模型库构建 SATVideoDiffusionEngine 模型。这是 Hallo3 内置的功能,可能需要进一步研究,以便将该过程从推理阶段转移到构建阶段,这将显著减少无服务器容器的冷启动时间。在部署无服务器容器之前测试模型有助于您了解其工作原理以及如何对其进行优化,以实现快速推理的无服务器部署。
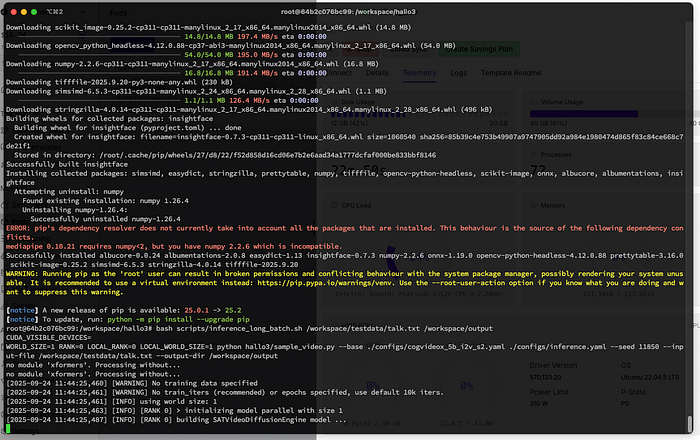
执行过程中的性能测量有助于了解模型的实际资源需求。Hallo3 需要 49 GB 的磁盘空间和 60 GB 的 NVRAM,在 H100 GPU 温度为 53°C 时,最大功耗为 300 瓦。测试执行的遥测数据清楚地证实了该模型无法在小于 H100 的任何处理器上运行。
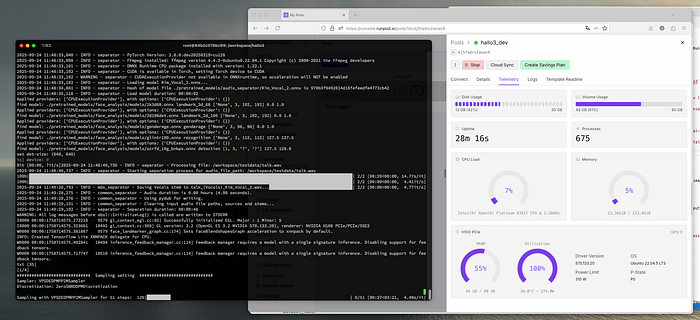
测试输出是参数指定的输出目录中的 000000_with_audio.mp4 文件。奇怪的是,视频不包含任何音频,因此必须在 Python 脚本中添加音频,或者直接在应用程序的后期处理中完成。
根据工作流程或应用用例,现在可以将 Python 脚本和模型数据部署到带有 Docker 容器和网络存储的无服务器 Pod 中,或者部署到可休眠并按需启动的静态 Pod 中。对于无服务器部署,我强烈建议将模型下载与推理分开(请参阅 Pod 的网络卷),否则您将需要付费使用无服务器 H100 实例将模型文件下载到存储中。一旦模型在静态 Pod 上运行,部署到无服务器就变得非常简单。
Hallo3 模型的推理大约需要 25 分钟,而 H100 Pod 的每小时费用为 2.19 美元,可生成一段 5 秒的视频。这意味着一段 5 秒的视频的成本为 0.91 美元。对于无服务器部署,需要优化脚本和模型加载,以将实际推理时间降至最低,大约每次推理需要 10 分钟或 0.36 美元(视频)。此成本与 RunPod 为 Kling AI 等视频生成器收取的费用一致。优化模型的无服务器部署对于您的应用提供具有竞争力的价格至关重要。
在无服务器容器中运行您自己的模型,可以让您访问并完全控制大量现有的模型,包括 Huggingface 上最流行的文本转视频模型。根据您的 AI 应用的目标,相比那些受限于公共 API 端点(例如 Gemini 2.5 Flash Image(俗称 Nano Banana)或 gpt-image-1)背后的模型功能和限制的应用,这可能具有显著的竞争优势。此外,自行在 GPU 上运行模型可以让您获得可移植性,并可以自由切换提供商。当 GPU 价格下降时,您就可以切换,而不必指望公共 API 的价格会降低。
3、结束语
绝大多数视频应用都是基于 Veo 3、Kling AI 或 WAN 2.2 的简单封装。使用公共端点构建工作流已经可以制作出非常令人印象深刻的视频。然而,你会发现公共模型 API 存在局限性。RealVisXL 和 Juggernaut Reborn 是我目前最喜欢的图像生成器,但它们都无法通过公共 API 使用。但结合 WAN、Kling 和 Hallo3,你可以用它们生成令人印象深刻的电影级视频。目前,运行 GPU 实例是组合这些模型的唯一选择。
在本文中,你已经了解了生成视频 AI API 和应用程序只不过是运行在搭载 NVIDIA GPU 的服务器上的模型,并根据需求进行扩展。RunPod 无疑是目前最经济实惠、最灵活的平台之一。正如我在本文中所阐述的那样,开发自己的视频应用程序并非易事,也并非难事。虽然这可能是使用公共 API 的最快方法,但熟悉在 H100 等 NVIDIA GPU 上使用这些模型和 Python 库,将确保你始终保持最新状态,并能够访问最新且不受限制的 AI 模型。
原文链接:Tech Stack Deep Dive Into AI Video Generator APIs, Platforms & Models
汇智网翻译整理,转载请标明出处
