5个顶级视觉语言模型的简单测试
聊天模型正在以惊人的速度发展,它们的能力每天都在提高。然而,基于视觉的任务仍然是许多AI模型的重大挑战。

聊天模型正在以惊人的速度发展,它们的能力每天都在提高,在某些情况下,甚至超越了人类在各种基于文本的任务上的表现。然而,基于视觉的任务仍然是许多AI模型的重大挑战。尽管如此,我们在图像理解和生成方面看到了令人印象深刻的结果。
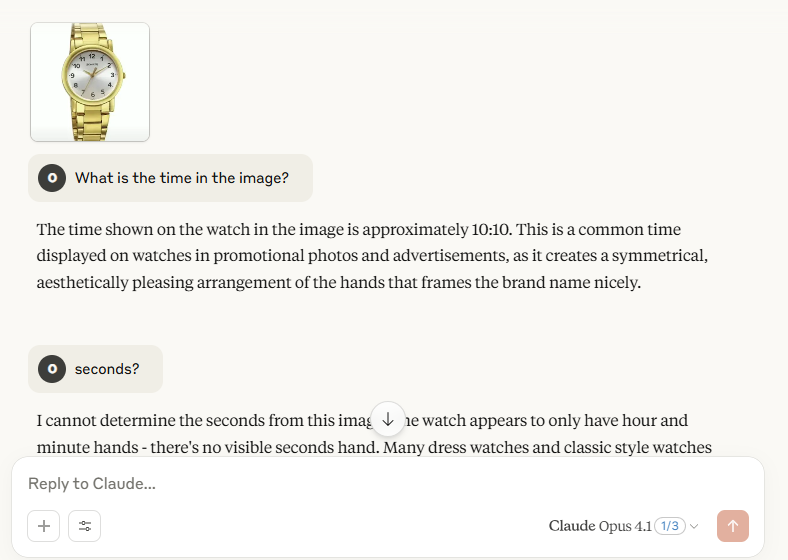
我最近看了一段彼得·罗比切克斯在AI工程师世界博览会的演讲,他在演讲中讨论了大型语言模型(包括封闭和开源模型)的视觉能力及其局限性。他进行了一项小实验来测试它们的图像理解能力:他向它们展示了一张手表显示时间为10:10的图片。这是广告中手表显示的默认和最常见时间,因此可以合理地认为LLM会熟悉这张特定的图片。
这是图片:

在他的视频中,彼得测试了GPT-4.1和Claude的Sonnet-4。我立刻想到,虽然这两个模型很强大,但还有其他一些有能力的模型值得测试。
因此,我扩展了彼得的小实验,测试了五个不同的模型(GPT、Claude Sonnet、Gemini、Qwen和Grok),以下是结果。
1、GPT-5和Sonnet-4:起步不错
也许一位智者曾经说过,“不要相信你听到的一切。”遵循这个智慧,我重新测试了这些模型。虽然我相信视频是准确的,但我认为或许我可以获得新的见解。
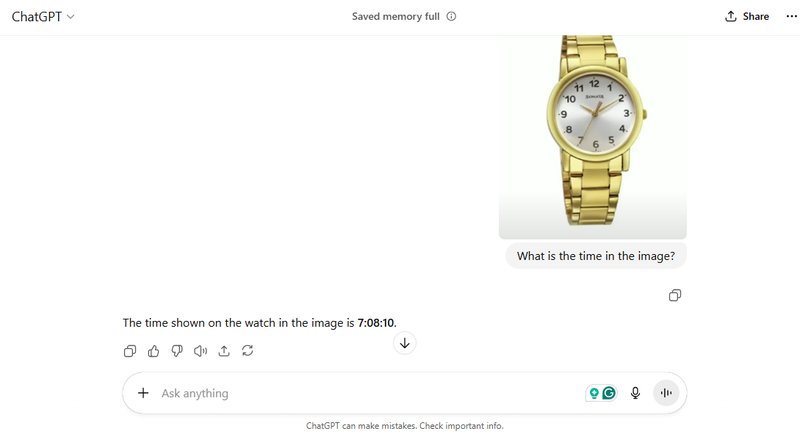
首先,我测试了GPT-5。正如视频所建议的那样,GPT模型未能识别正确的时间。视频可能是在GPT-5发布前几天发布的,所以它可能使用的是4.1版本,但结果是一样的。
有趣的是,GPT-5提供了数字7、08和10。这表明该模型能够识别手表的三根指针,但未能区分它们或理解它们的功能。
与视频不同,Claude的Sonnet 4实际上成功地确定了时间(10:10),并正确将其与广告中常见的手表时间联系起来。然而,它完全忽略了秒针——这对大多数模型来说是一个具有挑战性的任务。
2、Qwen和Grok:接近但未完全达到
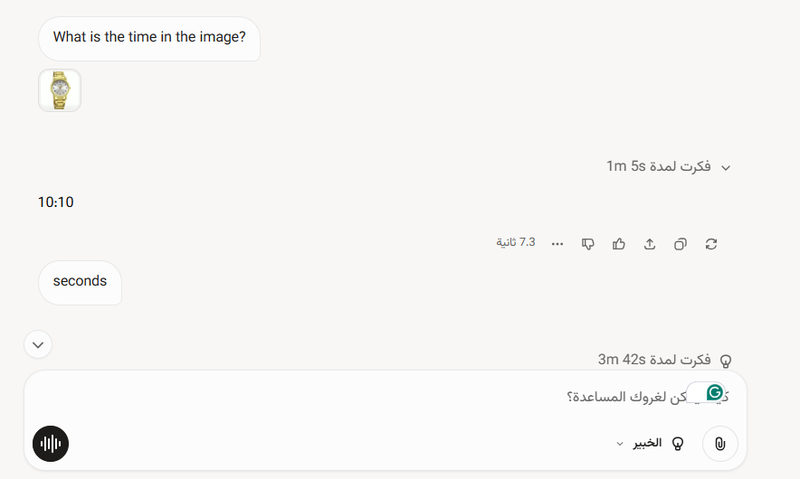
接下来,我测试了Qwen-3和Grok-4。这两个模型的结果与Sonnet相同:它们在小时和分钟上成功,但在识别秒数上失败。
深入研究Grok的思维链过程可以解释为什么会这样。以下是它的推理过程:
分析请求
- 问题询问图片中显示的时间。
- 图片中有一块金色的手表,白色表面和标准钟表数字。
- 数字似乎旋转了,12在顶部,11在左边。
- 考虑到不寻常的数字位置,这很可能是一块谜题手表。
- 小时指针指向左下角,可能在8和9之间。 确定手表指针
- 短指针指向“10”,位于10点位置,左上方。
- 长指针指向“2”,位于2点位置,右上方。
- 手表很可能设置为10:10,这是一个常见的促销时间。
- “Sonata”品牌可见,表明它是一张标准的促销图片。
如你所见,该模型实际上看到了秒针(“可能在8和9之间”),但错误地将其识别为时针。然后它正确识别了其他两根指针,并且基于它看到的品牌名称,利用其关于手表广告的知识假设时间为10:10。Sonnet可能遵循了类似的基于启发式的过程。
虽然并不完美,但考虑到模型正确识别了所有三根指针的存在,这仍然是一个很好的结果。
3、Gemini 2.5 Pro:明显的赢家
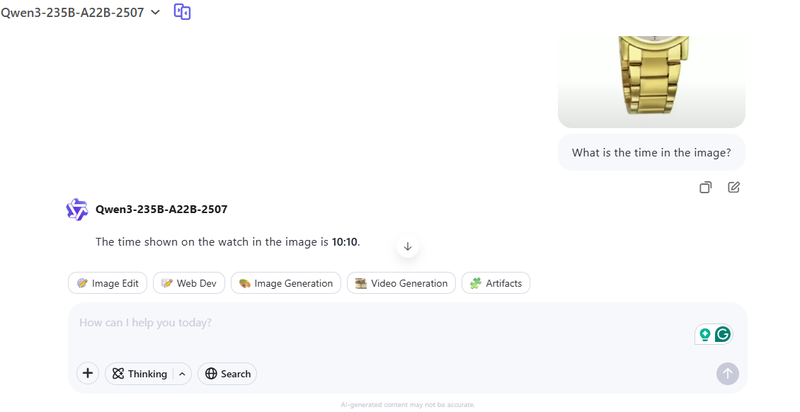
然后我们有这个小挑战的赢家:Gemini-2.5 Pro。这个模型完美地回答了问题,最重要的是,它正确识别了秒数。
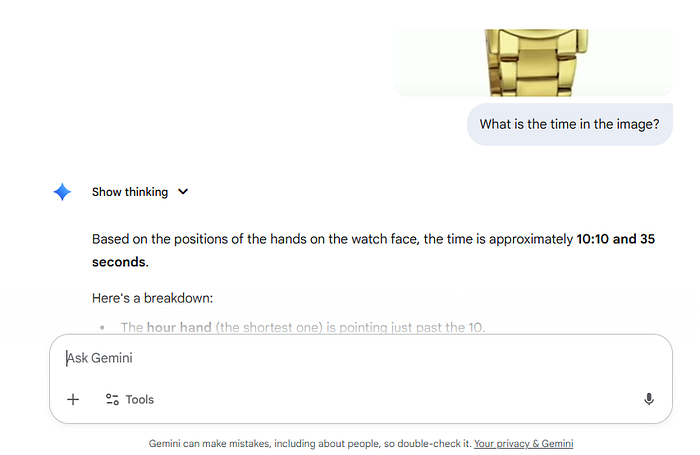
这是它的完整答案:
这里是一个分解:
- 时针(最短的那根)指向10之后一点。
- 分针(较长的那根)指向2,表示整点后的10分钟。
- 秒针(最细的那根)指向7,表示35秒。
4、为什么Gemini成功了?
Gemini模型从零开始构建为原生多模态系统,这意味着它们可以直接处理视觉数据,而不是首先将其转换为文本。它们的统一transformer架构同时处理多种输入类型,每一层都有跨模态注意力。这使得模型能够深入连接视觉和文本信息,以高精度捕捉空间关系、颜色和视觉语义。
通过这种设计,Gemini在图像描述、分类、视觉问答和多模态推理方面表现出色。它将世界知识与视觉输入相结合的能力使其在解释复杂上下文时具有优势。
Gemini还训练于大规模的对齐多模态数据集,这些数据集将图像、文本和视频联系在一起。这种广泛的训练使模型能够在不依赖专门的OCR或任务特定工具的情况下在基准测试中表现出色,使其在复杂的视觉和推理任务中非常多功能。
原文链接:I Gave 5 Top AI Models a Simple Vision Test. Only One Passed.
汇智网翻译整理,转载请标明出处
