AgentCore:代理内存服务
AgentCore Memory 是 AWS 提供的一项服务,允许您为代理应用程序创建和管理短期和长期记忆。

在构建代理应用程序时,上下文是关键。我之前曾写过关于各种代理框架(例如 LangGraph、CrewAI、Strands Agents 等)只是构造一个带有足够上下文的增强提示,以从模型中获得良好的响应。如果我将这个提示序列化为一个简单的 JSON 对象,那么它可能看起来像这样:
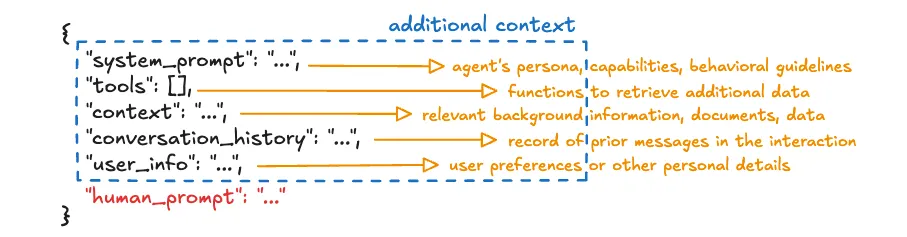
提示中的每个元素都是通过不同方式由框架添加的。系统提示可能是作为代理的一部分硬编码的,或者可能从配置存储中检索。工具可能通过调用 MCP 服务器的客户端调用来获取。上下文元素可能使用检索增强生成(RAG),其中代理在向量数据库中进行语义相似性搜索以找到相关的数据块。对话历史和用户信息可能从代理内存系统中检索。
所有这些元素都是提供给模型的上下文,有助于它生成适当、可能准确,并且必然在预期行为范围内的响应。
在这篇博客文章中,我将介绍一些上下文元素如何存储在代理内存中,以增强模型可能处理的提示。让我们从定义代理应用程序中的内存开始。
1、什么是内存?
让我们从教学的角度来看内存系统。有许多白皮书、博客文章和产品描述定义了内存系统。它们对内存的定义都有细微差别和细节。但它们都同意有两种类型的内存:短期记忆和长期记忆。
对于短期记忆,主要是关于当前对话或会话的相关交互和信息。它也可能包括多步骤执行的一些状态。
对于长期记忆,我倾向于采用 LangMem 的指 南中对代理应用程序内存类型的分类。需要说明的是,我不一定认为这更正确,但可能是因为这是我读过的第一个并消化过的。
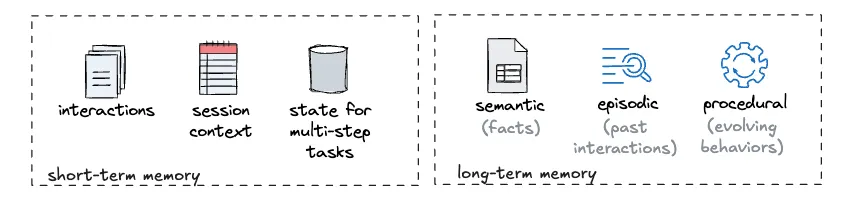
语义记忆 — 存储事实和知识,使代理的响应有基础,例如用户偏好、领域特定的事实、交互历史摘要
情景记忆 — 保留成功的交互作为学习示例,即捕捉交互的完整上下文,如情况、思考过程以及为什么某种方法有效
程序性记忆 — 编码代理应该如何行为和回应,例如演化响应模式,增强系统提示
所以这些都是有用的信息,可以增强提示,最终让模型针对手头的任务产生有用的回答。现在让我们看看这些系统是如何工作的。
2、代理内存系统是如何工作的?
在考虑代理内存如何工作时,我从一个轶事开始,说明代理内存是什么不是,以及我最初误解了如何使用它。
几个月前,我第一次尝试使用代理内存时,mem0 是我尝试的第一个。几分钟内,我就能够设置我的项目,创建 API 密钥,并将我的代理与记忆连接起来。然而,因为这是一个“hello world”项目,我只是有一个基本的“hello world”提示。有了这个提示,我没有看到任何记忆出现在仪表板上。我继续尝试排查,也许我的项目没有正确设置,或者也许我错误地使用了 API 密钥。
最终,我意识到我需要在提示中有更有意义的内容,以便 mem0 实际上添加一个记忆。这时我意识到,代理内存系统并不是像 redis 或 memcached 这样的简单键值缓存。作为一名 API 开发人员,我期望它像缓存一样运行,但我了解到代理内存系统可以而且确实要复杂得多。
那么它们实际上是如何工作的呢?这是我认为代理内存系统的工作原理:

代理应用程序使用生命周期钩子将有关终端用户交互、会话上下文和任务状态的信息传递给内存系统。该落地区是一个短期记忆子系统,在其中信息以原始数据的形式存储,尽管在用户和会话级别的命名空间中组织。
然后定期地,内存系统将最近摄入的数据发送到长期记忆子系统。长期记忆子系统使用具有预定义提示的模型,即策略,将原始数据转换为有用的记忆。该策略可以告诉模型总结对话并只存储相关信息,例如包含基本用户信息、所涉产品、客户遇到的问题、提出的建议等的客户服务对话。这些长期记忆可以被代理检索,用于增强提示。
好的,让我们实际看看另一个代理内存服务是如何工作的。
3、AgentCore Memory 如何工作?
AgentCore Memory 是 AWS 提供的一项服务,允许您为代理应用程序创建和管理短期和长期记忆。它在两个层面上运行,与上面描述的类别相一致。
短期记忆 — 用于即时对话上下文和会话信息,提供单个交互或紧密相关会话内的连续性
长期记忆 — 用于从多个对话中提取和存储的信息,包括事实、偏好和摘要,从而随时间实现个性化体验
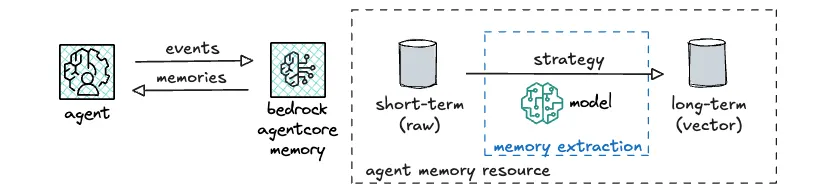
使用 AgentCore Memory 时,首先创建一个内存资源,就像创建任何其他数据持久化层一样只需一次。内存资源充当短期和长期记忆的容器,并可用于多个用户在许多不同会话中。
与内存资源交互时,每次交互都表示为一个事件,您有三个核心操作可供使用,与这些事件相关:创建、删除和获取|列出。这些操作始终以 memoryId 开始,它是内存资源的字符串标识符。创建事件时,当然需要包括 payload,它可以包含对话数据作为字典对象或二进制内容作为 blob 对象。所有事件和操作都在 actorId 和 sessionId 下作用域,这允许您按角色和会话组织事件。用户的每个问题和代理的每个回答都会保存为内存资源的短期记忆中的一个事件。
create_event(memoryId, actorId, sessionId, eventTimestamp, payload=[], ...)
delete_event(memoryId, actorId, sessionId, eventId)
get_event(memoryId, actorId, sessionId, eventId)
为了启用长期记忆,您必须配置一个策略。截至撰写本文时,AgentCore Memory 支持三种内置策略和一种自定义策略:
语义 — 存储事实信息
摘要 — 摘要对话以保持上下文
用户偏好 — 跟踪用户偏好和设置
自定义 — 允许自定义提取和整合
内置策略似乎使用了一些底层模型,具有预定义的系统提示,以实现所选策略的目标。而自定义策略则允许您提供自己的指令附加到系统提示中,并选择适合您自定义策略用例的模型。
有趣的是,这会对使用 AgentCore Memory 的定价产生影响。虽然 AgentCore 定价目前仅处于预览阶段,但在撰写本文时,使用内置策略存储每千条记忆每月收费 0.75 美元,而使用自定义记忆策略存储每千条记忆每月收费 0.25 美元。这是因为内置策略包含了底层模型推理的成本,而自定义策略不包含。该模型使用的成本会单独计费。
好了,这就是这个服务的工作方式的一点点。让我们深入了解如何将其构建到您的代理中。
4、为代理创建记忆
我有一个完整的实现,所以我只涵盖我在第一次做这个时学到的相关经验。
正如我在关于 AgentCore Runtime 的帖子中提到的,目前 AgentCore 控制平面操作是通过 AWS Python SDK (boto3) 完成的。通常,内存资源是通过基础设施即代码提前创建的,然后代理会引用它,通常是通过环境变量配置。然而,在我的 hello world 示例中,我创建了内存资源,或者如果该名称的内存资源已经存在,则获取引用。
这段代码在编写生产部署的代理代码时不应包含在内。这是因为这会在运行时执行期间引入控制平面操作。请记住,控制平面操作的配额远低于数据平面操作。如果内存不存在,那每次代理调用就是一个控制平面操作。如果内存存在,那每次代理调用就是两个控制平面操作——一个用于列表,另一个用于获取。随着应用程序扩展,你可能会陷入因控制平面配额而出现的限制错误的困境。
5、通过最小权限策略保护内存
此外,提前创建内存资源允许您为代理应用程序创建一个 IAM 角色和策略,该策略设置了最小权限策略。例如,在我的 hello world 示例中,我配置了我的内存策略,允许代理应用程序有效地访问任何内存。这对于生产部署来说是不可接受的。相反,适当的策略应该是这样的:
- PolicyName: bedrock-agentcore
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- bedrock-agentcore:CreateEvent
- bedrock-agentcore:DeleteEvent
- bedrock-agentcore:GetEvent
- bedrock-agentcore:ListEvents
- bedrock-agentcore:RetrieveMemoryRecords
Resource:
- !Sub 'arn:aws:bedrock-agentcore:${AWS::Region}:${AWS::AccountId}:memory/${MemoryName}-*'
因此,我的代理现在可以访问内存资源。它是如何实际发送事件的呢?
6、在代理中集成内存
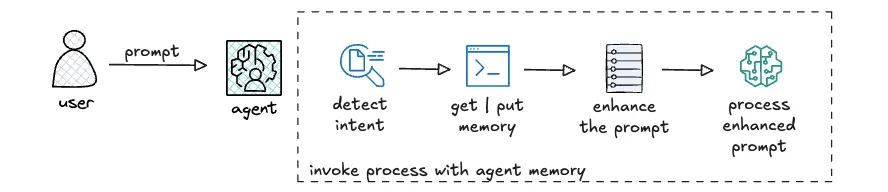
将内存集成到代理中有两种方法:1/ 通过工具或 2/ 通过生命周期钩子。在两种情况下,都需要编写与内存系统交互的函数,例如 get_memory()、put_memory() 等。然后通过上述方法使用这些函数。
当通过工具使用内存时,这些函数可以被注释并作为工具传递给模型。代理的系统提示可以指导模型何时应该获取或放置内存事件。在某些场景中,您可能希望更确定地执行一些这些内存操作,比如在 Strands 示例 中使用 mem0。下面是该流程的样子。
当通过生命周期钩子使用内存时,这些函数则注册到代理的生命周期事件中。Strands 有四个钩子来处理代理执行的不同阶段。
AgentInitializedEvent — 在代理初始化完成后BeforeInvocationEvent — 在新代理请求的开始AfterInvocationEvent — 在代理请求的结束MessageAddedEvent — 当消息被添加到对话历史记录时
这些生命周期钩子与各种内存选项很好地匹配。例如,在 AgentInitializedEvent 上,您可能会加载与代理整个生命周期相关的核心语义知识。在 BeforeInvocationEvent 上,您可能会加载对话历史记录中的最后 N 条消息。在 AfterInvocationEvent 上,您可能会保存当前会话的相关工作或输出。在 MessageAddedEvent 上,如果消息与当前任务相关,您会保存该消息。
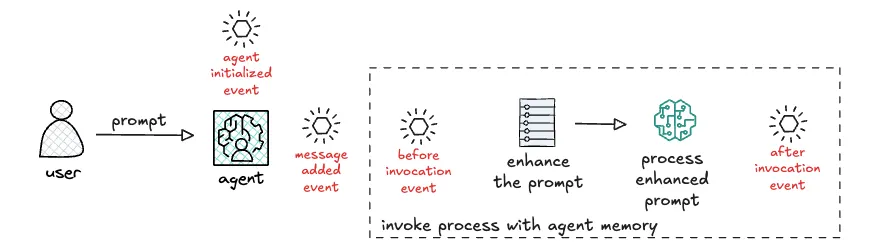
我认为一开始可能会觉得通过工具与内存系统进行交互更容易,因为命令式风格是人们通常编写代码的方式。然而,我更喜欢生命周期钩子的方法,因为它使用事件驱动的回调,使开发人员无需考虑如何协调内存操作。当然,这假设您首选的代理框架支持这种生命周期钩子方法。
好了,我涵盖了上下文对从模型中获得有效响应的重要性。短期记忆和长期记忆是获取上下文以构建增强提示的多种方式之一。
但是……是否有可能有太多上下文?
7、通过上下文工程解决大上下文问题
OpenAI 的 GPT-4.1 支持 1m 个 token 的上下文窗口,Claude Sonnet 4 也 支持 1m 个 token 的上下文窗口(公开测试版)。越大越好,对吗?也许……或者也许不是?我经常这样说,但在这里再次重复是有价值的。
仅仅因为你可以,并不意味着你应该应该。
一篇题为《迷失在中间:语言模型如何使用长上下文》的白皮书讨论了大上下文的挑战。简而言之,模型往往会表现出 U 型性能曲线,在开头(首因偏差)和结尾(近因偏差)的信息表现最好。基本上,中间的信息会被丢失。
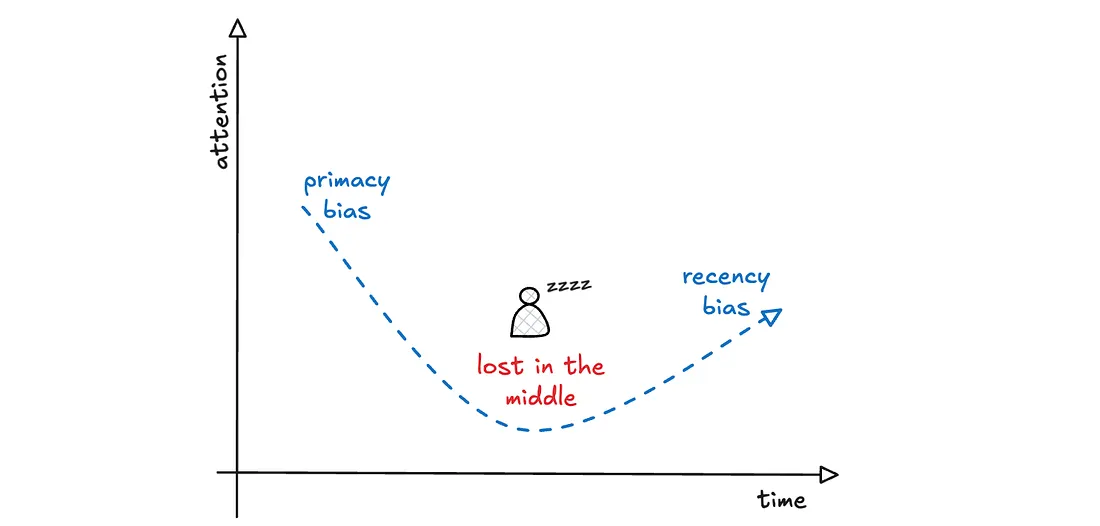
这很合理。在任何情况下,比如当你在听一个演讲时,最容易在开始时注意(首因偏差),因为你可能对演讲感到兴奋。然而,随着演讲的进行,很容易分心,你开始多任务处理或查看手机(迷失在中间)。然而,当演讲接近尾声时,你会听到一个呼吁行动,让你重新集中注意力(近因偏差)。这可能是一个愚蠢的例子,但在现代注意力经济中这是一个挑战。这导致了 140(现在是 280)字符的推文或 1-2 分钟的短视频的流行。
同样,代理应用程序需要一种智能的方法来增强与模型一起使用的提示。以下所有建议最终旨在通过适量的上下文来增强提示——不多不少。
1/ 删除不必要的内容以减少模型需要考虑的内容,而不是把整个厨房洗碗机扔进增强提示中。
2/ 过滤与您的代理关联的工具数量,因为这可能导致工具选择的挑战并导致意外或未处理的输出。
3/ 通过总结或提取最相关或重要信息来压缩对话历史中的信息量。
4/ 将不再需要但以后可能有用的超出上下文的信息卸载出去。
5/ 通过 RAG 数据存储中的语义搜索或通过从现有数据库或已知 API 数据提供商拉取数据的工具来拉入并验证来自可信数据源的上下文
8、结束语
在构建和运营您的代理应用程序时,获得正确的信息填充的正确数量的上下文,受到适当的行为指南引导,并通过最小权限安全护栏加以保护,是至关重要的。
在这篇博客文章中,我涵盖了代理应用程序中的记忆概念和更广泛的上下文工程,以帮助您思考如何构建适用于您用例并符合合理行为范围的代理。我还提供了一些如何使用 AgentCore Memory 实现记忆的指导,特别是生命周期钩子如何使将记忆集成到您的应用程序中变得容易。
原文链接:Adding memory to your agentic applications using AgentCore Memory
汇智网翻译整理,转载请标明出处
