LLM推理服务器基准测试
基准测试LLM推理系统却出乎意料地复杂。有许多可调节的设置,而且不同的基准测试甚至可能相互矛盾。

基准测试应该是黄金标准。它们应该是可重复的、易于理解的,并且最终是用于驱动决策的数据。有趣的是,基准测试LLM推理系统却出乎意料地复杂。有许多可调节的设置,而且不同的基准测试甚至可能相互矛盾。
我们希望让别人很容易看到推理引擎的速度。为此,我正在开源我们在Luminal的基准测试工具。虽然它肯定不是完美的(我们会随着时间的推移继续改进),但希望它能成为团队使用的一种更简单、更容易理解的工具。
这些是我尝试理解LLM推理服务器基准测试时的一些实战笔记。我没有声称拥有答案——只是分享我尝试过的内容以及让我感到惊讶的地方。这篇博客文章将解释我在整理这些内容时所做的关键决定。
1、视角
我们的基准测试脚本从客户端和服务器的角度跟踪指标。一般的想法是覆盖基准测试期间的整个体验,以便我们宣布的指标与用户实际体验的指标之间的差异尽可能小。
在测量这一点时,实际上有两个视角需要考虑:服务器和客户端。
1.1 服务器视角
服务器在模型的前向传递过程中直接计算每秒令牌数。现代推理引擎使用某种形式的分页注意力来批量处理请求,从而同时生成许多令牌。每秒可以生成的令牌数量称为吞吐量,通常来说,吞吐量越高,您的业务成本越低。当批处理大小更大时,我们一次处理的令牌更多,从而产生更高的吞吐量。
1.2 客户端视角
客户端根据从服务器获取响应的时间计算每秒令牌数。因此,这会考虑到网络延迟、标记化时间以及服务器上可能发生的任何预处理和后处理。对于我们Luminal来说,这种延迟是最关键的,因为它直接影响客户体验。
服务器等待处理更大的批次的时间越长,客户的延迟就越差。因此,我们需要意识到我们在两者之间做出的平衡。
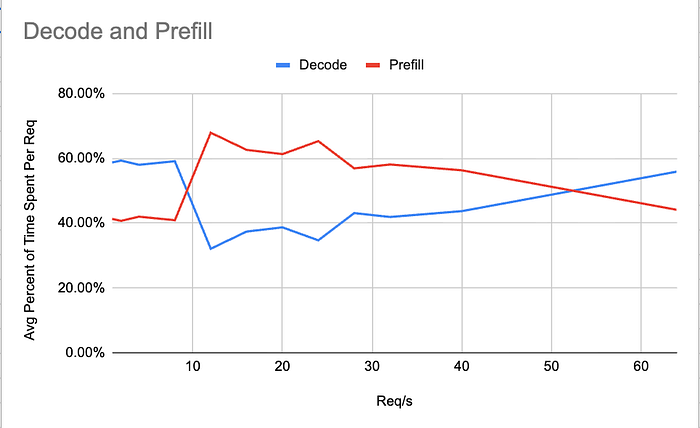
1.3 首个令牌时间(TTFT)和令牌间延迟(ITL)
LLM推理有两个不同的阶段:预填充和解码。关键的是,预填充是计算密集型的,而解码是内存密集型的。每个阶段受益于不同的内核优化。为了查看预填充阶段的表现,我们使用TTFT指标,因为预填充阶段的输出是第一个令牌。另一方面,我们的解码阶段最好通过ITL来跟踪。
虽然这两个指标都可以在服务器端进行跟踪,但我决定通过启用“流式传输”在客户端进行跟踪。这个测量再次关注于优先跟踪实际的客户体验。当您的客户正在流式传输令牌时,他们不会满意,直到他们真正获得自己的令牌。
2、尽可能贴近现实世界
基准测试的价值取决于其预测真实情况的能力。为了确保我们的基准测试准确衡量客户应期望的情况,我在基准测试期间做了两件事,以使我们更接近现实世界的负载。
首先,我选择使用聊天端点进行基准测试,以包括真实聊天请求所产生的任何开销(例如系统/用户提示格式化、图像预处理等)。这样,我们的数据反映了聊天API用户的实际看到的内容。其他一些基准测试调用较低级别的generate函数以隔离模型吞吐量;这对于内部指标是有用的,但对于终端用户体验的测量可能会有些乐观。
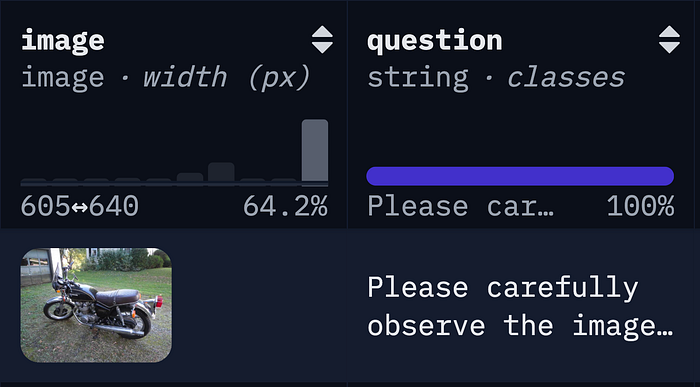
其次,我让我们的请求数据具有现实世界的代表性。对于我们的视觉语言模型,我使用了lmms-lab/COCO-Caption2017数据集,因为它的多样性和质量。然后我通过泊松分布发送请求,因为在现实中请求永远不会均匀到来。
3、负载测试
我选择每秒请求数作为主要的负载变量。这个指标让我们能够确定哪些负载需要开始扩展,以及当我们同时受到许多不同用户的影响时,客户体验如何变化。
4、服务器端配置
在进行基准测试时,有一些配置我们需要在整个运行过程中保持恒定。如果我们不这样做,那么我们的基准测试将无法提供一致的结果。
除了基准测试之外,队列长度和批处理大小的设置也是我们确保为用户提供最低质量的标准。没有这一点,几乎不可能向用户保证速度。
4.1 批处理大小
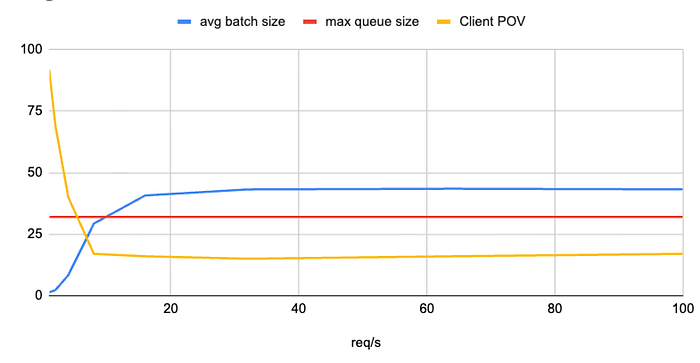
批处理大小是我们分页注意力内核一次可以处理的最大请求数。这个值越大,潜在的吞吐量就越高。通常,您会根据资源设置这个值尽可能高。
4.2 队列长度
进行批处理请求的一个后果是需要队列,而这个队列很快成为延迟的主要来源。在当前批次被处理时到达的任何请求都必须等待它完成。这会引入最大的延迟,因为队列中后面的任何请求基于其在队列中的位置,其延迟将显著高于其他请求。
4.3 队列饱和度
最大的教训是队列饱和度如何强烈影响基准测试的一致性。当队列填满时,延迟自然会上升。如果您用不同的请求数运行相同的测试而不考虑这一点,您的结果将会有所不同。
为了避免这种情况,请保持最大队列长度一致,并测量请求在其中等待的时间。这种方式的测试还可以让您设定最坏体验的底线。
5、结束语
我已经开源了基准测试软件(Github),这样其他人就不必像我一样经历太多麻烦就能得到简单的结果。
原文链接:Benchmarking LLM Inference Servers
汇智网翻译整理,转载请标明出处
