构建视频处理多智能体AI系统
本文介绍多智能体视频处理的概念基础、架构、关键的实现细节、面临的挑战以及从中获得的经验教训。
在快速发展的人工智能领域,多智能体系统 (MAS) 正成为处理复杂、多步骤任务的强大工具。在这些系统中,多个 AI 智能体像专家团队一样协作,可以处理从数据收集到创意输出的所有工作。作为一名拥有机器学习和计算机视觉背景的软件工程师,过去几年我一直在尝试 AI 驱动的自动化。我最有成就感的项目之一是构建一个多智能体系统,旨在通过全自动流程处理视频——从抓取原始数据源一直到生成精美的视频。
这不仅仅是一个理论练习,它源于现实世界的需求。我当时正在做一个业余项目,旨在创建关于新兴科技趋势的教育内容,但手动获取信息、分析信息、编写叙述脚本和剪辑视频非常耗时。我不禁思考:我能否组织一个 AI 智能体团队来完成端到端的这项工作?答案是肯定的,但这需要大量的反复试验、深夜调试,以及对智能体如何有效“沟通”的深入理解。
在本文中,我将分享我构建这个系统的个人历程。我们将介绍其概念基础、架构、关键的实现细节、我面临的挑战以及从中获得的经验教训。我的目标是为开发者和 AI 爱好者揭开多智能体系统的神秘面纱,展示如何将其应用于视频制作等创意工作流程。如果您对基于代理的人工智能 (AI) 感兴趣,或者正在寻求构建类似的东西,本文应该能为您提供一份实用的路线图。让我们开始吧!
1、理解人工智能中的多智能体系统
在深入探讨我的项目细节之前,值得快速了解一下多智能体系统。在人工智能中,多智能体系统 (MAS) 由自主的智能体组成,它们相互交互以实现共同目标。每个智能体都有各自的职责、决策能力以及与其他智能体沟通的方式——就像一个人类团队,研究人员收集信息,分析师处理数据,作者撰写文案,编辑润色最终产品。
这个概念并不新鲜;它借鉴了机器人技术和分布式计算等领域的经验。在现代人工智能中,像 LangChain、CrewAI 这样的框架,甚至使用 LLM(大型语言模型)的自定义设置,都使得个人开发者能够构建多智能体系统。智能体可以由 GPT-4、Claude 或其他开源替代方案驱动,它们通过 API、共享内存或消息队列进行“交流”。
MAS 用于视频处理最让我兴奋的是它的模块化设计。视频处理包含一系列连续的步骤:数据采集、内容分析、叙事生成、素材创建(例如图像或画外音)以及组装。通过将每个步骤分配给专门的代理,我可以创建一个可扩展、容错且比单片 AI 模型更易于调试的流水线。
在我的设置中,我使用 Python 作为主干,并利用 LangChain 等库进行代理编排,使用 BeautifulSoup 进行网页爬取,使用 OpenCV 进行图像/视频处理,以及使用 MoviePy 进行视频编辑。整个系统在本地机器上运行,并配备 GPU 加速以实现更快的处理速度,但它可以轻松扩展到 AWS 或 Google Cloud 等云服务。
2、问题:为什么要使用多代理视频流水线?
我的动机源于手动创建内容的挫败感。作为一个运营小型科技博客的人,我经常需要制作一些简短的讲解视频(比如 2-5 分钟),主题包括人工智能伦理或量子计算。寻找可靠的信息意味着要花费数小时在网上搜索、阅读文章和做笔记。然后还要编写脚本、查找视觉素材、录制音频和编辑。这效率低下,尤其是在趋势瞬息万变的情况下。
我设想了一个自动化流程,只需输入一个主题(例如“人工智能对医疗保健的影响”),系统就会输出一个可上传的视频。关键要求:
- 准确性:内容必须真实可靠,并引用自可靠来源。
- 创意:视频不应机械化;它需要引人入胜的叙事和视觉效果。
- 效率:每个视频的制作时间应少于一小时。
- 自定义:允许用户自定义,例如自定义样式或长度。
单个AI模型可以处理部分工作,但MAS擅长将其分解。代理可以进行专业化处理,从而减少错误,并在可能的情况下实现并行处理。
3、架构设计
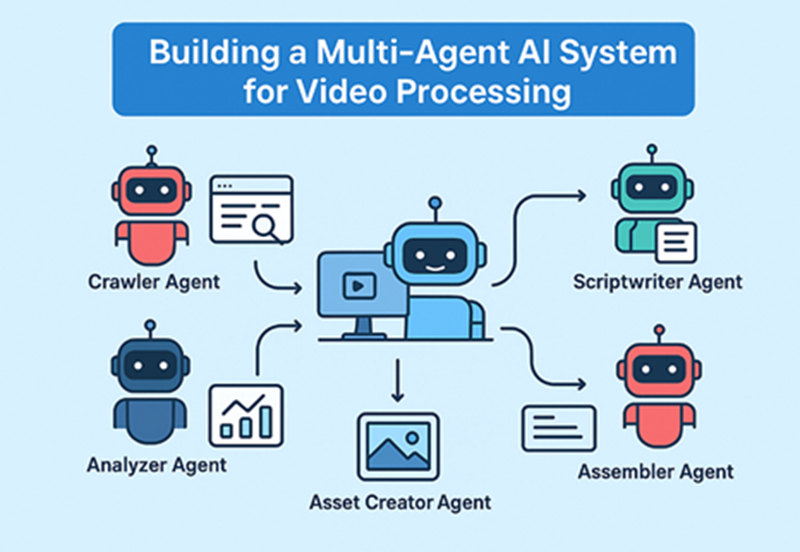
我首先进行了一个高层设计:一个带有反馈回路的线性流程,用于纠错。该系统包含五个主要代理,每个代理都定义了角色、输入、输出和交互协议。
a) 爬虫代理:负责数据收集。
- 输入:主题查询。
- 操作:网页抓取,调用 API 访问维基百科、新闻网站或学术数据库等来源。
- 输出:原始数据包(文本、URL、图片)。
- 工具:BeautifulSoup、Selenium(用于动态网站),并遵循道德抓取原则(尊重 robots.txt 文件)。
b) 分析器代理:处理和合成数据。
- 输入:来自爬虫的原始数据。
- 操作:提取关键事实,进行总结,并使用 TF-IDF 或基于 BERT 的嵌入等 NLP 技术识别主题。
- 输出:包含事实、引言和视觉效果的结构化知识图谱或 JSON。
- 工具:SpaCy(用于实体识别),Gensim(用于主题建模)。
c) 编剧代理:生成叙事。
- 输入:来自分析器的结构化数据。
- 操作:编写包含引言、正文和结论的脚本。融入叙事元素。
- 输出:脚本文本,用于视觉效果的时间戳。
- 工具:LLM提示工程(例如,“用 500 字写一篇关于 [主题] 的引人入胜的脚本”)。
d) 素材创建代理:处理多媒体。
- 输入:脚本。
- 操作:生成或获取图片、创建画外音、制作动画转场。
- 输出:包含音频、图片和字幕的素材文件夹。
- 工具:ElevenLabs 或 Google TTS 用于音频,Stable Diffusion 用于图片(如有需要),或常用 API。
e) 组装代理:构建最终视频。
- 输入:脚本和素材。
- 操作:将音频与视频同步、添加特效、导出。
- 输出:MP4 文件。
- 工具:MoviePy、FFmpeg。
代理通过共享的 Redis 队列进行消息通信,并通过 MongoDB 进行持久化状态存储。协调器(一个中央脚本)负责路由任务,并在代理失败(例如由于 API 速率限制)时处理重试。
4、实现
实施过程大约耗时两个月,从原型开始。
4.1 爬虫代理
爬虫是切入点。我构建它是为了以合乎道德的方式获取各种来源。对于像“医疗保健中的人工智能”这样的主题,它会:
- 查询 Google Search API 获取前 10 个结果。
- 使用 BeautifulSoup 从网站抓取文本,提取段落和标题。
- 下载带有替代文本的图片以获取上下文。
基本爬虫代码片段(简化):
import requests
from bs4 import BeautifulSoup
def crawl_url(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
text = ' '.join([p.text for p in soup.find_all('p')])
images = [img['src'] for img in soup.find_all('img') if 'src' in img.attrs]
return {'text': text, 'images': images}
# Example usage
data = crawl_url('https://example.com/ai-healthcare')我添加了速率限制和用户代理标头以避免阻塞。实际上,该代理每次运行收集 5-10 个来源,并使用嵌入的余弦相似度来过滤相关性。
4.2 分析器:将数据转化为洞察
该代理使用 Hugging Face 的 Transformers 进行摘要。它对文本进行分块,提取实体(例如,“IBM Watson”作为 AI 工具),并构建一个简单的图:节点表示概念,边表示关系。
例如,输入文本可能产生:
- 关键事实:“AI 检测癌症的准确率高达 95%。”
- 来源:NIH 研究。
输出为 JSON 格式,方便传递。
4.3 编剧:注入创造力
在这里,我主要依靠 OpenAI API 的提示工程。示例提示:“基于此数据 [JSON],编写一个关于医疗保健领域 AI 的 3 分钟视频脚本。使其引人入胜,以引人入胜的开头,以行动号召结尾。包含视觉提示。”
如果脚本过于枯燥,代理会进行迭代,并进行自我批评:“这是否引人入胜?提出改进建议。”
4.4 素材创建者:Multimedia Magic
音频部分,我使用 TTS API 生成自然语音的旁白。图片则通过抓取或 DALL-E 生成(如果匹配不上)。字幕则来自脚本,并带有时间线。
挑战:同步情感基调——例如,积极向上的用乐观的,风险低沉的用忧郁的。
4.5 组装器:最后的润色
MoviePy 简化了这个过程:
from moviepy.editor import TextClip, concatenate_videoclips, AudioFileClip, ImageClip
def assemble_video(script, assets):
clips = []
for segment in script['segments']:
img_clip = ImageClip(assets['images'][segment['visual']]).set_duration(segment['duration'])
text_clip = TextClip(segment['text'], fontsize=24).set_position('bottom').set_duration(segment['duration'])
clip = concatenate_videoclips([img_clip, text_clip])
clips.append(clip)
audio = AudioFileClip(assets['audio'])
final = concatenate_videoclips(clips).set_audio(audio)
final.write_videofile('output.mp4')这生成了一个基本的幻灯片式视频,我后来添加了转场效果。
整个流程循环运行:
编排器 -> 爬虫 -> 分析器 -> 脚本编写器 -> 素材创建器 -> 汇编器。总时长:每个视频 20-45 分钟。
5、挑战
没有一个项目是一帆风顺的。以下是一些主要障碍:
- 数据质量和伦理:爬虫可能会抓取过时或有偏见的信息。解决方案:优先选择信誉良好的网站(例如 .gov、.edu),并添加验证步骤,让分析器根据多个来源交叉核对事实。
- 代理协调:代理有时会“沟通不畅”——例如,脚本编写器会忽略分析器提供的事实。我使用 LangChain 的 Memory 模块实现了共享内存,允许代理查询过去的输出。
- 成本和可扩展性:API 调用量增加。我切换到 Llama 2 等本地模型来处理非关键任务,从而降低了 70% 的成本。
- 创造力 vs. 一致性:早期的视频比较平淡。我根据 TED 演讲中的例子对提示进行了微调,增加了语言的多样性。
- 错误处理:如果代理失败(例如网络错误),则管道会停止。添加了 try-except 块和重试,并使用 ELK 堆栈记录日志以进行调试。
测试涉及 50 多次运行,主题包括“气候变化 AI 解决方案”。经过多次迭代,成功率从 60% 提高到 95%。
6、经验及未来计划
该系统制作了不错的视频——即使没有好莱坞级别的质量,也内容丰富。
关键经验:
- 专业化带来回报:专注于特定领域的代理会脱颖而出;而专注于广泛领域的代理则表现不佳。
- 人工监督至关重要:务必检查输出结果是否存在幻觉或偏差。
- 迭代提示:小调整带来大改进。
- 开源力量:像 LangChain 这样的工具使多智能体系统 (MAS) 更加大众化,与 AI 的可访问性保持一致。
展望未来,我会将实时代理(例如用于直播)或协作式 MAS 与人工输入相结合。我还在探索符合伦理道德的 AI 准则,例如为生成的内容添加水印。
这个项目强化了我对 MAS 将成为自动化领域颠覆者这一信念。如果您刚刚起步,请从小处着手——构建一个双智能体系统,然后逐步扩展。LangChain 文档或基于智能体建模的书籍等资源是很好的入门选择。
7、结束语
构建这个多智能体视频处理流程是一次变革性的体验,将技术技能与创造性的问题解决能力融为一体。从简单的爬虫程序抓取数据到汇编程序输出视频,每个智能体都在将混乱转化为连贯的过程中发挥了至关重要的作用。随着人工智能的进步,这样的系统将赋能创作者、教育工作者和企业,使其能够大规模地创作内容。
原文链接:Building a Multi-Agent AI System for Video Processing
汇智网翻译整理,转载请标明出处
