打造自托管AI会议笔记工具
一个私有、无限且自托管的解决方案,使用Python、Whisper和Ollama实现。

在会议中做笔记是一项繁琐的任务。
试图捕捉每一个细节的同时还要参与讨论几乎是不可能的。自然地,我们很多人转向了AI驱动的转录服务。它们很神奇,但有一个代价:你必须将你的私人、有时是机密的会议录音上传到第三方服务器。
如果你们公司讨论的是未宣布的产品呢?如果你是一个治疗师、律师或记者,处理敏感的客户信息呢?隐私的权衡可能成为一个决定性因素。此外,免费层级通常限制很多,录音时间短,很快就会用完。
我想要一个更好的解决方案:一个拥有AI力量但具有本地优先应用隐私的工具。因此,我创建了一个。在本文中,我将带你了解我是如何创建一个网络应用程序的,它可以转录和总结任何长度的音频文件,就在你自己的机器上。
1、“为什么”:夺回对数据的控制权
目标很简单:创建一个工具,它具备:
- 100% 私人: 所有处理,从转录到总结,都在本地进行。没有任何数据离开机器。
- 无限: 再也不用看时间了。转录一个3小时的讲座或一个10分钟的会议,不会遇到付费墙。
- 易于使用: 一个简单的网页界面,任何人都可以使用,不需要成为命令行专家。
2、技术栈:我们的开源强大工具
这个项目建立在一些令人惊叹的开源工具之上:
- OpenAI的Whisper: 用于转录。Whisper是一个最先进的语音转文本模型,可以在各种口音和语言中提供非常准确的转录。我们将本地运行它以免费使用。
- Ollama: 用于总结。Ollama是一个出色的工具,使下载和在您自己的硬件上运行强大的大型语言模型(LLM)变得非常容易,例如Gemma、Phi-4或其他任何模型。
- Flask & Pydub: 用于后端。Flask是一个轻量级的Python Web框架,将处理文件上传并提供我们的应用程序。Pydub是一个简单而强大的音频操作库,我们将用于将大音频文件分割成可管理的块供Whisper使用。
3、构建后端:Python核心
我们应用程序的核心是一个Flask服务器(app.py),它协调整个过程。让我们分解关键组件。
3.1 处理文件上传
首先,我们需要一个简单的Flask路由来接受一个音频文件。我们将安全地命名文件,将其保存到uploads文件夹,然后在后台线程中启动处理,这样用户界面不会冻结。
# 在 app.py 中
@app.route('/upload', methods=['POST'])
def upload_file():
if 'file' not in request.files:
return jsonify({'error': '没有文件部分'}), 400
file = request.files['file']
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file.save(file_path)
job_id = str(uuid.uuid4())
# 启动后台处理
thread = threading.Thread(target=process_audio_file, args=(file_path, job_id))
thread.daemon = True
thread.start()
return jsonify({'job_id': job_id, 'status': '已开始'})
3.2 音频处理流程
这就是魔法发生的地方。process_audio_file函数是一个多步骤的流程:
步骤 A: 分割音频: Whisper 在较小的音频片段上表现最佳。我们使用 pydub 将源音频分割为 10 分钟的片段。
# 在 app.py 中
from pydub import AudioSegment
import math
def split_audio(audio_path, temp_dir, segment_minutes=10):
segment_ms = segment_minutes * 60 * 1000
audio = AudioSegment.from_file(audio_path)
# ... 分割音频并导出片段的逻辑 ...
return segment_paths
步骤 B: 转录每个片段: 我们遍历我们的音频片段并将每个片段发送到我们本地加载的 Whisper 模型。
# 在 app.py 中
import whisper
WHISPER_MODEL = whisper.load_model("large-v3") # 或 "base.en" 以提高速度
def transcribe_segment(segment_path):
result = WHISPER_MODEL.transcribe(segment_path, language="en")
return result.get("text", "").strip()
步骤 C: 使用 Ollama 进行总结: 一旦我们有了完整的转录文本,我们通过 Ollama 的 API 将其发送到本地 LLM,并给出一个明确的提示。
# 在 app.py 中
import requests
def query_ollama(prompt):
full_url = f"{OLLAMA_BASE_URL}/api/generate"
payload = {
"model": "gemma3:27b", # 或者您拉取的任何模型
"prompt": prompt,
"stream": False
}
response = requests.post(full_url, json=payload)
# ... 错误处理和响应解析 ...
return result.get("response")
# 在处理流程中...
prompt = f"根据以下转录内容,制作一份简洁专业的会议纪要\n\n---\n\n{combined_transcript}"
meeting_minutes = query_ollama(prompt)
4、创建前端:一个简单的用户界面
前端是一个带有少量JavaScript的单个index.html文件。核心逻辑是:
- 上传: 使用
fetchAPI将文件发送到我们的Flask后端。 - 轮询状态: 上传开始后,JavaScript每隔几秒向服务器上的
/status/<job_id>端点发起请求。 - 显示进度: 状态端点返回当前阶段(例如,“正在转录第2/5段...”),我们将其显示给用户。
- 呈现结果: 一旦状态变为“完成”,最终的转录文本和会议纪要将被返回并在页面上渲染。
5、结果:您的个人AI笔记工具
将所有内容整合在一起后,我们得到了一个功能齐全的Web应用程序,可以将任何音频文件转换为整洁的会议纪要,包括完整的转录文本。
最棒的部分?这一切都发生在您的机器上,没有人能看到您的数据。这是现代AI力量与传统隐私的完美结合。
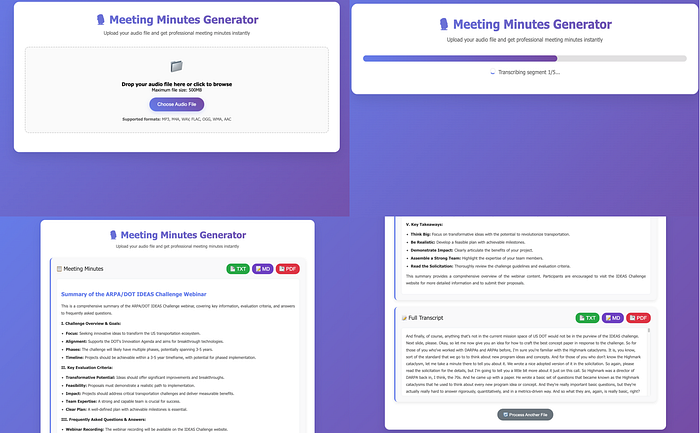
简单的流程:(1) 拖放任何音频文件,(2) 观看实时处理状态,(3) 审查AI生成的会议纪要,(4) 访问完整转录文本。
6、想自己运行它吗?
如果您有兴趣运行这个项目,我已经打包了整个源代码,并以一次性购买的方式提供。它包括详细的设置说明和本文中讨论的所有代码,可以直接运行。
这是一个快速启动强大且私有的AI工具的好方法,并支持独立开发。
您可以通过此链接获取完整项目: 在此链接
感谢阅读,希望这能激发您探索本地优先AI的奇妙世界!
原文链接:I Built a self-hosted AI Meeting Note Taker That Runs 100% Offline
汇智网翻译整理,转载请标明出处
