构建大规模金融数据代理
本文提供构建一个AI量化助手的蓝图,它可以回答问题、生成图表,并对TB级别的时序数据进行推理——使用你实际的生产数据。

如果你处理过金融数据,你会知道这种痛苦:处理千兆字节的逐笔数据、缓慢的分析以及笨拙的界面。在处理真实市场数据时,大多数“金融AI代理”更像是玩具——它们无法达到大多数量化分析师的工作规模。但如果你真的可以与你的kdb+数据库进行对话——几秒钟内查询、图表和分析数十亿行数据,而不是几个小时呢?
当你结合PyKX(Python原生桥接到kdb+,即世界上最快的时序数据库)和Agno(一个以工具为中心、模型无关的代理框架,专为实际工程设计,而不仅仅是聊天机器人)时,你就能实现这一点。kdb+已经是量化世界中逐笔数据分析的标准,但瓶颈往往在于人类:有人想要一张图表或一份报告,这时就需要量化开发人员编写代码并进行分析。这个栈不会取代量化分析师,但它确实自动化并加速了工作流程——让你可以问,“AAPL本月的波动性是多少?”或者“给我展示TSLA的蜡烛图”,并以你需要的速度获得基于实际kdb+数据的答案和图表。
PyKX为你提供了从Python直接且高效访问kdb+的功能。你可以使用向量化分析、列式存储,并且运行查询的速度比pandas快几个数量级。Agno是一个现代代理框架,实际上是为了工具和性能而构建的。它是模型无关的(OpenAI、Groq、Anthropic、本地模型等),并且允许你连接自定义的Python工具——因此你的代理可以运行真实的代码,而不仅仅是聊天。Agno以其清晰的代码、速度和庞大的开源社区(截至本文撰写时约有27k星)脱颖而出。
在这个例子中,我只加载了大约30MB的数据以便于操作,但这段代码同样可以扩展到TB级别的逐笔数据。这篇文章的其余部分是构建一个量化助手的蓝图,它可以回答问题、生成图表,并对TB级别的时序数据进行推理——使用你实际的生产数据。
0、限制
Agno的一个主要限制是,据我所知,它无法理解工具生成的图像。我已经打开了一个新的问题,并认为这个问题很快就会解决,但在那之前我们将利用一个小技巧来让我们的研究代理“活”起来。这也是其他代理框架中的一个问题,比如OpenAI Agents SDK。
1、设置:安装所有内容
!pip install agno openai mplfinance pykx
安装Agno(代理框架)、OpenAI(用于GPT-4o或其他LLM)、mplfinance(用于图表)和PyKX(Python <-> kdb+桥接)。
注意mplfinance的性能比matplotlib要好得多!
2、使用PyKX加载真实逐笔数据
在这里我们加载了3,336,876行分钟级数据到我们的kdb+表中。如果你想尝试1亿行以上的数据,请尝试这个数据集,应该可以用相同的方式加载——与图表生成和LLM推理相比,延迟增加可以忽略不计:<https://huggingface.co/datasets/AYUSHKHAIRE/real-time-stocks-data>
import pykx as kx
import pandas as pd
pandas_tbl = pd.read_csv('https://huggingface.co/datasets/opensporks/stocks/resolve/main/stocks.csv', parse_dates=['timestamp'])
pandas_tbl.head()
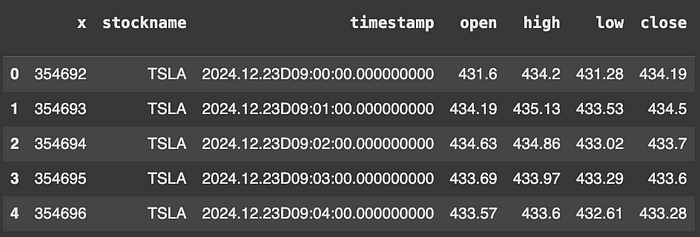
import pykx as kx
tbl = kx.toq(pandas_tbl)
tbl.head()
3、创建过滤函数
虽然在Pandas中快速查询/过滤TB级别的数据很慢,但在PyKX中却非常快。所以我们所做的就是创建一个过滤函数,我们可以传递关心的股票/时间窗口,并得到一个过滤后的pandas表作为结果。这个技巧让我们能够轻松扩展!
def filter_tickers_dates(
tbl: kx.Table,
tickers: list[str],
start_date: str | date,
end_date: str | date,
) -> pd.DataFrame:
# 辅助函数 -------------------------------------------------------------
def to_ts(d, end_of_day=False):
ts = pd.to_datetime(d)
if end_of_day:
ts = ts.replace(hour=23, minute=59, second=59, microsecond=999_999)
return kx.TimestampAtom(ts.to_datetime64())
lo, hi = to_ts(start_date), to_ts(end_date, True)
# 掩码 ---------------------------------------------------------------
col_sym = kx.Column("stockname")
tick_mask = col_sym.isin([kx.SymbolAtom(t) for t in tickers])
col_ts = kx.Column("timestamp")
time_mask = (col_ts >= lo) & (col_ts <= hi)
# 查询 ---------------------------------------------------------------
sub = tbl.select(where=tick_mask & time_mask)
return sub.pd() if not sub.empty else pd.DataFrame(columns=tbl.column_names())
# 测试 filter_tickers_dates
filter_tickers_dates(tbl, ['AAPL', 'TSLA'], '2025-02-17', '2025-02-22')
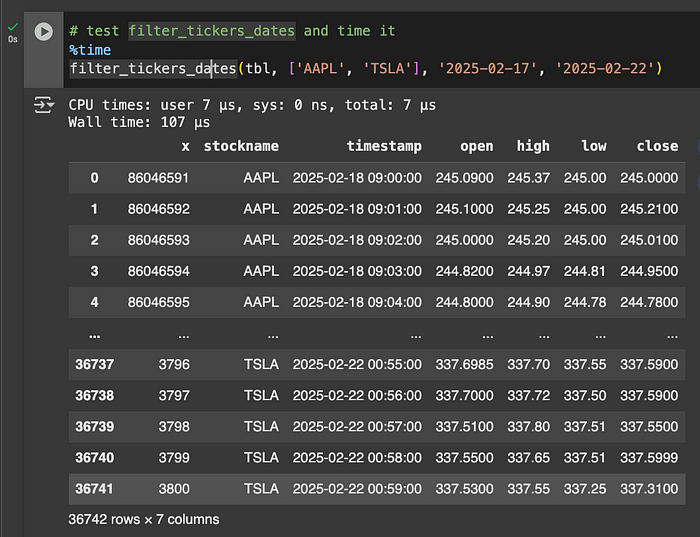
即使没有优化,这个查询也非常快。
4、构建工具:查询、图表、分析
现在我们有了过滤函数,我们可以定义一些Agno工具。这就是我们的代理将如何与表交互。你还可以为它创建工具来进行联结、运行SQL(或者是qSQL,即kdb+的SQL式接口),或者以任何你喜欢的方式与你的表交互。
要尝试完整的代码或查看更多的完整代理输出,请查看这个Colab笔记本。它还包括我们完整的工具定义。
# ─── 工具定义 ─────────────────────────────────────────────
# 设置你的OpenAI API密钥
os.environ["OPENAI_API_KEY"] = 'YOUR_OPENAI_API_KEY'
@tool(
name="CandlestickTool",
description="为某个股票生成[开始,结束]期间的OHLC蜡烛图。",
show_result=True,
)
def candlestick_tool(ticker: str, start: str, end: str) -> str:
df = filter_tickers_dates(tbl, [ticker], start, end)
if df.empty:
return f"{ticker}在{start}和{end}之间没有数据。"
df['timestamp'] = pd.to_datetime(df['timestamp'])
df2 = df.set_index('timestamp')[['open','high','low','close']]
mpf.plot(df2, type='candle', style='yahoo', mav=(20,),
volume=False, savefig=dict(fname=f"candlestick_{ticker}.png"))
return f""
# ...同样为:
# @tool(name="BollingerBandsTool", ...)
# def bollinger_tool(...) {...}
# @tool(name="VolatilityTool", ...)
# def volatility_tool(...) {...}
# 等等。
蜡烛图工具获取OHLC数据并生成图表。你可以添加更多:波动性、相关性等。我总共添加了大约5个分析工具
5、图像工具的替代方案
我之前提到过,我不知道如何直接将图像传递给模型。这是理想的情况,因为代理可以直接在其上下文中拥有这些图像。
相反,我们将使用一个小技巧——我们将添加一个额外的工具来分析图像。这个工具接受图像并返回该图像的描述/回答模型可能有的任何问题。这远非理想,但这是我能做的最好的方法。
@tool(
name="DescribeImageTool",
description="用问题描述一张图片。基本上就是与图片聊天。image_path总是./something.png",
show_result=True,
)
def describe_image_tool(image_path: str, question: str) -> str:
if not os.path.exists(image_path):
print(f"文件未找到: {image_path}")
return f"文件未找到: {image_path}"
b64 = _b64(image_path)
client = OpenAI()
resp = client.responses.create(
model='gpt-4o',
input=[{
"role": "user",
"content": [
{"type": "input_text", "text": question},
{"type": "input_image", "image_url": f"data:image/png;base64,{b64}"},
],
}],
)
return resp.output_text
6、创建代理
现在让我们使用gpt-4o创建一个代理来与我们的工具交互:
agent = Agent(
model=OpenAIChat(id="gpt-4o"),
description=(
"一个股票分析助理。始终调用正确的工具 "
"明确指定股票、开始和结束日期(YYYY-MM-DD)。"
),
tools=[
ReasoningTools(add_instructions=True),
candlestick_tool,
bollinger_tool,
performance_tool,
correlation_tool,
return_histogram_tool,
describe_image_tool,
],
instructions=[
"你是一个金融代理。你的工作是使用数据回答金融问题。",
"你的数据范围是2024-12-14 00:00:00到2025-02-22 00:59:59。",
"{'GOOGL', 'META', 'MSFT', 'TSLA', 'AAPL', 'AMZN'}是你唯一可以访问的股票",
"像量化分析师一样智能思考",
"只调用你需要回答问题的工具",
"只调用工具的股票和日期范围在数据集中",
"使用工具时,考虑什么日期范围会使它们更易读。例如,对于蜡烛图,最多一周是可读的"
],
show_tool_calls=True,
markdown=True,
)
代理通过你的工具和角色设置连接起来。它可以调用工具、查看其输出,并使用LLM推理来回答问题。
当工具返回图像文件名(如“candlestick.png”)时,Agno将图像传递给LLM(例如,GPT-4o)进行分析。代理现在可以“看到”图表并评论趋势、波动性或异常点——就像一个人类量化分析师一样。
我们可以轻松地添加Agno的其他工具——这里可能是框架中最让我喜欢的部分!
我们可以用几行代码为我们的代理添加搜索、推理或YFinance工具。我只是添加了推理工具,似乎提高了性能。
tools=[
ReasoningTools(add_instructions=True),
...
]
7、运行代理!
让我们用一个研究问题运行代理:
agent.print_response(
"比较2025-02-17到2025-02-22之间的TSLA和AAPL。当你得到图像时,确保使用描述图像工具来弄清楚发生了什么。",
stream=True,
show_full_reasoning=True,
show_tool_calls=True,
stream_intermediate_steps=True,
)
代理将获取数据、生成图表,并使用LLM描述它看到的内容。你会同时得到图表和自然语言摘要。
结果:
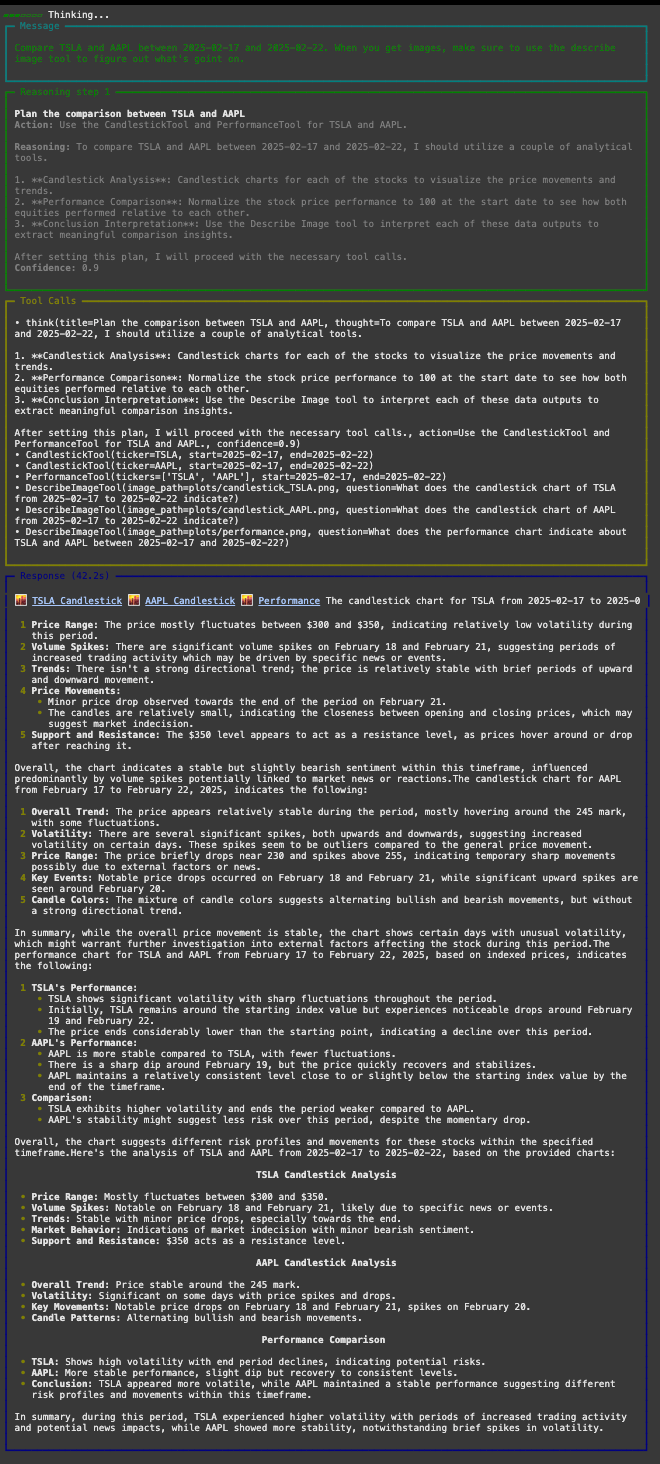
以下是生成的一些图表之一:
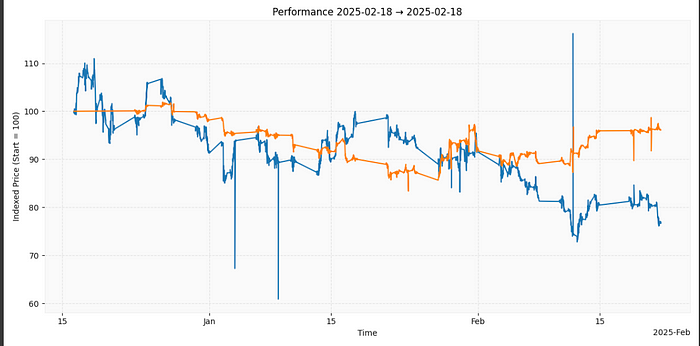
8、结束语
这个例子远远不是Agno所能实现的极限——量化交易员会制作的工具很可能非常不同且更加复杂,专注于VWAP、夏普比率,并创建自定义图表而非预构建的图表。
但我对Agno的直观体验感到非常满意。
关键要点:
- LLMs + kdb+ = 实际、可扩展、交互式的分析。
- Agno使代理在真实数据上变得实用,而不仅仅是玩具演示。
- 你可以今天就构建一个真正有用的量化助手。
如果你厌倦了缓慢的分析并想为金融数据构建一个真正的代理,这个堆栈可能就是你的选择。更多信息请查看PyKX和Agno的文档。
原文链接:Chat with Terabytes: Building a Scalable Financial Data Agent
汇智网翻译整理,转载请标明出处
