构建代理化对象检测流程
Andrew NG 几个月前发布了一篇帖子,介绍了“代理化对象检测”——一种系统,它从用户那里获取文本描述,并以代理的方式检测对象。

Andrew NG 几个月前发布了一篇帖子,介绍了“代理化对象检测”——一种系统,它从用户那里获取文本描述,并以代理的方式检测对象。
这标志着一个非常有趣的时代。我们正进入一个代理工作流迅速发展的时代,这由多种因素推动。视觉语言模型(VLM)不仅在快速改进,而且变得更加普及,达到了可以高度可靠地用于代理工作流的水平。
1、简介
传统上,计算机视觉任务如图像分类、对象检测和语义分割被构造成封闭集问题,模型只能识别它们训练时的类别。即使随着卷积神经网络(CNN)的深度学习推动了性能的提升,适应新的领域或识别未见过的对象仍然需要重新训练或微调。
随着基于transformer的架构的出现,特别是 CLIP(对比语言-图像预训练)[1],发生了重大转变。通过在数亿张带注释的图片上联合训练文本和图像编码器,CLIP 学习了图像和文本的共享表示空间。由于两种模态存在于相同的嵌入空间中,您可以向模型提示任意文本,例如新的类别标签或描述短语,CLIP 可以将其与相关的视觉特征相关联,即使该模型在训练期间从未遇到过该特定对象或短语。
CLIP 的图像-文本预训练实现了开放词汇检测和分割。像 DINO [2] 和 OWL-ViT [3] 这样的模型可以在不重新训练的情况下定位诸如“蓝色回收箱”或“有涂鸦的停止标志”之类的短语。后续的努力将感知与文本结合。多模态 LLM(GPT-4V [4] , Gemini [5] , Claude-Sonnet [6])采用了类似 CLIP 的图像编码器,并用文本解码器对其进行训练,以实现多模态能力。从固定类别的 CV 模型到可调整的 VLM 基础系统的转变正在推动代理框架的发展。不再需要手动标签工程或重新训练,开发人员可以通过简单的语言命令处理各种任务。代理可以在实时中被指导检测对象、分割区域或解释场景,超出其训练数据。这种方法消除了传统基于标签方法的限制,使视觉任务能够在实时中组合和调整。
OpenAI 最近发布的 o3 模型 [7](可通过 UI 使用)实现了这一范式,作为一个完全代理的视觉系统。除了直接生成边界框外,o3 可以自主调用外部工具,例如编写 Python 代码来缩放、旋转或调整图像的对比度,启动网络搜索以获取更多上下文,将结果反馈给自己的推理,并迭代。这种能力是迈向真正自主的计算机视觉代理的重要一步,这些代理混合了感知、工具使用和迭代自我批评在一个推理过程中。
2、实现代理对象检测
在这篇博客文章中,我们描述了如何利用开放词汇对象检测器和 VLM 作为批评和验证来构建一个代理对象检测框架。
2.1 高层次设计
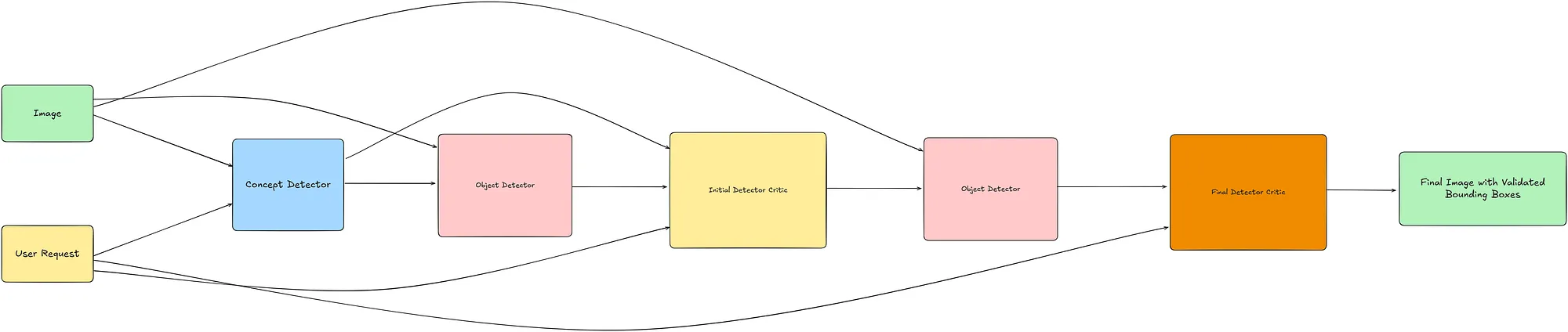
我们从一个开放集对象检测器开始,该检测器接受一张图像和用户提供的描述要识别的对象的文本提示。
- 概念推断: 给定用户上传的图像和请求,我们首先使用 VLM(GPT-4o [8])推断相关的对象概念。如果请求中提到了特定的对象,这些对象会被直接提取出来。否则,VLM 会识别图像中所有显著的对象。
- 初始检测: 推断出的对象概念被传递给一个开放集对象检测器(Grounding DINO [9])以生成边界框。
- 可视化: 在图像上标注检测到的对象,用箭头和唯一的数字标签,加上白色边框以提高清晰度。
- 查询批评和优化: 这个带有提取的概念和原始用户请求的标注图像由一个 VLM 评估器(OpenAI 的 o1 [10])分析,使用思维链推理。如果发现误分类或低级标签,模型会将对象类别细化为更高级的抽象(例如,“poodle” → “dog”,“cricketers” → “people”,“bats” → “bat”)。
- 细化检测: 这些修订后的概念与原始图像一起提供给对象检测器,以生成更新的边界框。
- 最终过滤: 更新的检测再次被标注。此最终图像由一个 VLM(GPT-4o)使用思维链推理进行审查,以过滤掉无关的检测,只保留符合用户意图的检测。
- 输出: 结果是一张最终标注的图像,其中的验证边界框精确对应于用户的请求。
2.2 验证和推理时间计算
LLM 和 VLM 可以作为批评者来检查和验证主要模型的输出,这些模型通常能力较弱,从而提高整体结果的质量。此外,研究人员探索了允许模型在推理时间获得更多计算资源的方法,称为推理时间计算或测试时间计算,使它们能够通过多步骤的思维链推理和自一致性采样“思考更久”。推理时间计算的一个重要特点是它不涉及对模型权重的任何更新。
我们的流程整合了这两个想法。在第一次开放集检测后,我们进行了两次由 VLM 评估器驱动的验证步骤和一次检测步骤:
验证与抽象(第4步): VLM 会检查标注图像上的每个边界框及其标签。当发现误分类或过于具体的类别时,它会建议更高层次的抽象(poodle → dog,cricketers → people*),并改进原始查询。这是完整的推理一次通过。
细化检测(第5步): 在获得修正的概念列表后,系统在原始图像上重新运行检测器。第二次定位过程消耗更多的计算资源,但可能由于开放词汇模型在识别更粗略类别方面的优势而产生更好的召回率。
最终过滤(第6步): 利用 VLM 的最终推理步骤交叉检查更新的检测,丢弃仍然无关的框。
2.3 为什么需要额外计算
- 模型无关收益: 由于验证仅在推理时发生,新的检测器或推理者可以无需重新训练或额外数据收集就插入其中。改进纯粹来自于额外的计算。
- 可解释性和可调试性: 思维链日志揭示了预测被拒绝的原因,为开发人员和利益相关者提供了见解。
通过明确分配推理时间计算用于验证和批评,该流程将原始的开放集检测转化为一个旨在实现用户对齐、高精度结果的代理系统,而无需收集新数据或重新训练模型。
3、流程实现
本文中使用的所有代码和资源均可在github 中找到 ,并且在我的原始 博客相关仓库中有一个镜像。
为了实现流程,我们首先开始实现一个功能,以提取用户提供的图像中包含的高层概念或对象。
3.1 VLM 工具
为了通过 API 将图像发送到 OpenAI 的 VLM,我们需要将它们编码为 base64 字符串。我们实现了一个辅助函数:
import base64
def encode_image(image_path):
"""
将图像文件编码为 base64 编码的字符串。
参数:
image_path (str): 要编码的图像文件的路径。
返回:
str: 图像内容的 base64 编码字符串。
None: 如果编码过程中发生错误。
异常:
Exception: 如果无法打开或编码文件。
"""
try:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
except Exception as e:
print(f"编码图像时出错: {e}")
return None
我们首先实现 VLMTool,作为 OpenAI API 的轻量级包装器以与 VLM 交互。
import base64
import json
from openai import OpenAI
from utils.image_utils import encode_image
class VLMTool:
def __init__(self, api_key):
pass
def chat_completion(self, messages, model="o1", max_tokens=300, temperature=0.1, response_format=None):
pass
def extract_objects_from_request(self, image_path, user_text, model="gpt-4o"):
pass
我们实现了一个核心方法 chat_completion,它将消息列表转发给选定的模型——如 gpt-4o 或 o1——并返回助手的文本响应。
def chat_completion(
self,
messages,
model="o1",
max_tokens=300,
temperature=0.1,
response_format=None
):
"""调用 GPT 进行聊天完成。"""
try:
if model in ["gpt-4o", "gpt-4o-mini"]:
response = self.client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens,
temperature=temperature,
response_format=response_format if response_format else {"type": "text"}
)
elif model in ["o1"]:
response = self.client.chat.completions.create(
model=model,
messages=messages,
response_format=response_format if response_format else {"type": "text"}
)
else:
raise NotImplementedError("此模型不受支持")
return response.choices[0].message.content
except Exception as e:
print(f"调用 LLM 时出错: {e}")
return None
提取所提供图像中的概念的主要功能是在 extract_objects_from_request 中实现的:它将用户的图像转换为 base-64,将该编码图像与用户的文本配对,并让 VLM 发出逗号分隔的对象列表。
- 如果请求明确指定了目标(“请检测所有杯子”),模型会返回这些名称。
- 如果请求是开放式的(“检测你看到的一切”),模型会列出图片中可见的物品。该方法返回这些名称。
def extract_objects_from_request(self, image_path, user_text, model="gpt-4o"):
"""
让 LLM 解析用户的请求以检测/分割对象。
返回纯文本形式的对象列表。
"""
base64_image = encode_image(image_path)
if not base64_image:
return None
prompt = (
"你是一个 AI 视觉助手,负责从用户的请求中提取要识别的对象。"
"如果用户想要检测或语义分割图像中的所有对象,请返回你看到的物体的逗号分隔列表。 "
"如果用户想要检测或语义分割特定对象,请仅提取他们请求中明确提到的对象。 "
"仅以逗号分隔的对象列表回应,不要其他内容。"
"这里的目标仅仅是理解可以从图像和用户的请求中提取的兴趣对象。"
"你不需要实际执行或执行用户的请求。"
)
messages = [
{"role": "system", "content": prompt},
{
"role": "user",
"content": [
{"type": "text", "text": user_text},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail": "high"
}
}
]
}
]
result = self.chat_completion(messages, model=model)
if result:
detected_objects = [
obj.strip().lower()
for obj in result.split(",")
if obj.strip()
]
return detected_objects
return []
实际上,VLMTool 执行所有初始规划——决定应该检测什么,然后继续其他步骤。在这个阶段,我们已经实现了第一个关键部分,即在查询中识别感兴趣的物体,以标准化并准备最优格式用于使用开放词汇对象检测器的检测。(参见 此链接 获取完整实现)
3.2 代理对象检测流程
我们现在实现 ObjectDetectionTool,它将我们的整个代理对象检测工作流程组合在一起。在高层次上,我们首先实现这个类的构造函数:
class ObjectDetectionTool:
"""
使用 GroundingDINO 或 OWL-ViT 进行对象检测,
加上一个可选的 'critique'(精炼)步骤,通过 VLM
以产生一组精炼的对象进行检测。
"""
def __init__(self, model_id, device, vlm_tool, confidence_threshold=0.2, concept_detection_model="gpt-4o", initial_critique_model="o1", final_critique_model="gpt-4o"):
self.model_id = model_id
self.processor = AutoProcessor.from_pretrained(model_id)
self.model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
self.device = device
self.vlm_tool = vlm_tool # 可以处理视觉(GPT-4V)或类似的 LLMTool
self.confidence_threshold = confidence_threshold
self.concept_detection_model = concept_detection_model
self.initial_critique_model = initial_critique_model
self.final_critique_model = final_critique_model
# 我们存储边界框以供以后使用(例如,用于 SAM)。
self.last_detection_bboxes = []
self.last_filtered_objects = []
这个模块设置视觉语言处理的核心组件。它加载检测器权重——无论是 Grounding-DINO 还是 OWL-ViT——加载到 CPU 或 GPU 上(我们在本博客中所有情况下都使用 Grounding-DINO)。它初始化语言模型权重,存储共享的 VLMTool 实例以及指定的用于初始和最终验证阶段的 LLM。它还配置边界框的置信度阈值,并分配缓存以存储最近的检测结果。
3.3 运行对象检测器
我们实现了一个方法 _run_detector 来使用开放词汇对象检测器进行第一次前向传递。流程首先将提示适配到目标模型——OWL-VIT 需要像 [“一张猫的图片”, …] 这样的列表,而 DINO 更喜欢用句点分隔的字符串如“猫。狗。”。接下来,在 torch.no_grad() 下通过变压器执行前向传递。然后将原始、归一化的边界框转换为像素坐标,并丢弃低于置信度阈值的内容。最后,在图像上绘制箭头和数字,以便语言模型以后可以无歧义地引用对象,例如“框 #3。”。我们实现了一个实用函数来绘制箭头和框:
def draw_arrows_and_numbers(image_path, detected_objects):
"""
在图像上绘制箭头和数字以标记检测到的对象。
此函数动态地在边界附近放置数字,箭头指向对象中心。
箭头是虚线,以提高清晰度,编号在可能的情况下避免重叠。
参数:
image_path (str): 输入图像的路径。
detected_objects (list): 包含对象信息的元组列表,格式为 (number, object_name, bounding_box),其中 bounding_box 是 (x1, y1, x2, y2)。
返回:
str: 保存的标记图像路径 ('labeled_objects_optimized.jpg')。
注意:
- 箭头从对象中心指向最近的边界。
- 数字以半透明背景显示以提高可读性。
"""
img = cv2.imread(image_path)
font = cv2.FONT_HERSHEY_SIMPLEX
used_positions = []
# 在图像周围添加白色边框
top, bottom, left, right = 50, 50, 50, 50
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=[255, 255, 255])
height, width, _ = img.shape
for i, (num, obj, box) in enumerate(detected_objects):
x1, y1, x2, y2 = map(int, box)
cx, cy = (x1 + x2) // 2, (y1 + y2) // 2 # 边界框的中心
# 调整坐标以适应加边的图像
x1 += left
y1 += top
x2 += left
y2 += top
cx += left
cy += top
# 确定指向最近边界的箭头方向
distances = {'top': cy, 'bottom': height - cy, 'left': cx, 'right': width - cx}
direction = min(distances, key=distances.get)
if direction == 'top':
arrow_end = (cx, top)
text_position = (cx - 10, top - 10)
elif direction == 'bottom':
arrow_end = (cx, height - bottom)
text_position = (cx - 10, height - 5)
elif direction == 'left':
arrow_end = (left, cy)
text_position = (left - 30, cy + 5)
else:
arrow_end = (width - right, cy)
text_position = (width - 30, cy + 5)
# 从对象中心到边界的虚线箭头
color = (0, 0, 0) # 所有箭头的黑色颜色
line_type = cv2.LINE_4
cv2.arrowedLine(img, (cx, cy), arrow_end, color, 2, tipLength=0.3)
# 在文本后面绘制半透明矩形
overlay = img.copy()
cv2.rectangle(overlay, (text_position[0] - 5, text_position[1] - 20), (text_position[0] + 30, text_position[1] + 5), (0, 0, 0), -1)
alpha = 0.5
cv2.addWeighted(overlay, alpha, img, 1 - alpha, 0, img)
# 在边界上用黑色文本绘制数字
cv2.putText(img, str(num), text_position, font, 0.8, color, 2)
labeled_image_path = "labeled_objects_optimized.jpg"
cv2.imwrite(labeled_image_path, img)
return labeled_image_path
def _run_detector(self, image_path, query_list):
"""
低级例程,用于在 `query_list` 上运行检测模型。
返回: (detected_objects_final, labeled_image_path)
其中 `detected_objects_final` = [(num, label, [x1,y1,x2,y2]), ...]。
"""
from PIL import ImageFont
# 格式化查询以供模型使用
if INV_MODEL_TYPES[self.model_id] == "owlvit":
formatted_queries = [f"An image of {q}" for q in query_list]
elif INV_MODEL_TYPES[self.model_id] == "grounding_dino":
formatted_queries = " ".join([f"{q}." for q in list(set(query_list))])
else:
raise NotImplementedError("模型不支持")
# 加载图像
img = Image.open(image_path).convert("RGB")
inputs = self.processor(
text=formatted_queries,
images=img,
return_tensors="pt",
padding=True,
truncation=True
).to(self.device)
self.model.eval()
with torch.no_grad():
outputs = self.model(**inputs)
# 后处理边界框
if INV_MODEL_TYPES[self.model_id] == "grounding_dino":
results = self.processor.post_process_grounded_object_detection(
outputs,
inputs.input_ids,
box_threshold=0.4,
text_threshold=0.3,
target_sizes=[img.size[::-1]]
)
boxes = results[0]["boxes"]
scores = results[0]["scores"]
labels = results[0]["labels"]
elif INV_MODEL_TYPES[self.model_id] == "owlvit": # OWL-ViT
logits = torch.max(outputs["logits"][0], dim=-1)
scores = torch.sigmoid(logits.values).cpu().numpy()
labels = logits.indices.cpu().numpy()
boxes = outputs["pred_boxes"][0].cpu().numpy()
else:
raise NotImplementedError("模型不支持")
detected_objects_final = []
idx = 1
for score, box, label_idx in zip(scores, boxes, labels):
if score < self.confidence_threshold:
continue
detected_objects_final.append((idx, label_idx, box.tolist()))
idx += 1
# 绘制数字
labeled_image_path = draw_arrows_and_numbers(image_path, detected_objects_final)
return detected_objects_final, labeled_image_path
3.4 为什么使用编号批处理进行推理
验证检测最简单的方法是将每个边界框视为独立的任务。检测器触发后,管道会遍历它产生的n个框,并对每个框执行以下序列:
- 隔离裁剪: 提取由框定义的矩形区域和/或在候选对象周围绘制边界框。
- 将该裁剪进行 base-64 编码: 对新图像进行编码并将其作为其自己的
data:image/jpeg;base64,…字符串发送。 - 组成专用提示: 编写一个嵌入图像并询问 VLM 的提示,比如:“图像中的边界框是否包含杯子?回答‘是’或‘否’。”
- 将提示发送到 VLM: 模型运行一次完整的前向传递——解析提示、解码图像并生成文本判断。
- 解析并处理结果: 如果模型回答“否”,则丢弃该框;否则保留它。
循环重复直到每个框都被检查。在一个繁忙的场景中,检测器可能会返回几十个框,因此验证器必须运行几十次。
这种方法的缺点是处理、成本和延迟开销。每次裁剪都会触发一次新的 API 调用、图像上传和模型前向传递。25 个检测意味着 25 次调用,这导致 25 倍的延迟和令牌/图像计费成本。
编号箭头注释绕过了所有这些缺点,将验证阶段转换为一次上下文丰富的 VLM 传递。在每个检测上叠加箭头和数字,然后将一个复合图像交给语言模型,带来了三个相互关联的好处——速度、成本和推理质量。
1. 更快的处理和扩展: 通过在单个画布上叠加箭头和数字,该流程只发送一张图像和一个提示,大幅降低验证费用和总体处理时间。这作为一种批量处理机制。 在高对象场景中,即使检测数量增加,验证时间也保持大致恒定。唯一的小成本是绘制几个额外的箭头,这与额外的检测器或 LLM 传递相比是微不足道的。
2. 确定性的、易于参考的 ID: 带有稳定数字的箭头作为主键在整个流程中使用。语言模型可以说“盒子 3 和 6 不相关”,代码可以过滤精确的整数,人类也可以查看图片并看到这些数字。如果你依赖文本描述 alone (“勺子下的蓝色杯子”),你会面临脆弱的字符串匹配或容易出错的启发式方法。数字 ID 使得视觉代码和语言模型之间的交接无损。
3. 更好地利用 VLM 的视觉 token 预算: VLM 有有限的分辨率预算——通常是单个图像加上几千个文本 token。箭头几乎覆盖任何区域,因此它们保留了原始细节,同时仍给模型明确的指针。
简而言之,暴力裁剪循环虽然简单,但计算和财务效率低下,而箭头批量处理通过高效利用 VLM 的上下文窗口实现了更快和更便宜的处理。
3.5 批评和优化查询
LLM 看到当前的检测以及用户的文本,并被问及概念是否太狭窄。如果是,它会建议更广泛的术语(“狗”而不是“茶杯贵宾犬”)作为逗号分隔列表。这一步通过计算换取稳健性:它使用另一个 LLM 传递并在列表更改时重新运行检测器,故意在验证器标记初始尝试不足时花费更多计算。
def _critique_and_refine_query(self, user_request, original_concepts, labeled_image_path, objects_detected, model="o1"):
"""
向 VLM/LLM 提问:“我们尝试检测 <objects_detected> 以满足用户的请求,
但可能我们需要一组经过优化的对象。
返回一个新的对象或概念列表以进行检测。”
"""
base64_labeled_image = encode_image(labeled_image_path)
# 为了清晰起见,我们将原始用户请求和
# 当前检测到的对象列表传递给 LLM。
# LLM 可以提出一个经过优化的对象检测列表。
refine_messages = [
{
"role": "system",
"content": """
你是一个 AI 系统,用于优化检测查询。
你将获得对象检测模型的输出,以及用户的请求和从用户的请求中提取并提供给对象检测模型的对象。
你的任务是分析对象检测器是否正确地提取了用户的请求的结果,如果不是,则通过尽可能通用的概念进行优化。
重要指南:
1. 如果检测结果良好,不需要优化。
- 在这种情况下,提供说明不需要优化的推理并返回相同列表。
2. 如果检测结果差或为空,提出同义词或更通用的类别并解释原因。尽可能保留概念的单数形式。
3. 以包含两个字段的 JSON 对象返回最终答案: "reasoning" 和 "refined_list".
- "reasoning" 是为什么您进行了优化或没有优化的简短解释。
- "refined_list" 是应重新尝试检测的对象名称的逗号分隔列表。
4. 仅输出 JSON,不要其他文本。
以下是一些示例:
示例 1
用户的请求:检测茶杯贵宾犬
原始概念: "Teacup poodle"
最终输出:
{
"reasoning": "提供的图像中没有针对茶杯贵宾犬的检测。概念 'teacup poodle' 可能是模型检测的非常具体的概念。这可以优化为更高级和通用的概念,如 'Dog',
"refined_list": "dog"
}
示例 2
用户的请求:检测闪亮的细高跟鞋
原始概念: "Sparkly stiletto shoe"
最终输出:
{
"reasoning": "提供的图像中没有对应于 'Sparkly stiletto shoe' 的具体检测。'Sparkly stiletto shoe' 可能对模型来说太具体了。优化为 'shoe' 这个更通用的概念可能会提高检测的可能性。",
"refined_list": "shoe"
}
示例 3
用户的请求:检测绣球花
原始概念: "Hydrangea"
最终输出:
{
"reasoning": "没有发现 'hydrangea' 的检测。模型可能难以识别特定类型的花。优化为更通用的概念 'flower' 可能会得到更好的结果。",
"refined_list": "flower"
}
示例 4
用户的请求:检测美食汉堡包
原始概念: "Gourmet cheeseburger"
最终输出:
{
"reasoning": "没有观察到 'Gourmet cheeseburger' 的检测。'Gourmet cheeseburger' 可能太具体了。优化为 'hamburger',因为它与检测到的对象相吻合。",
"refined_list": "hamburger"
}
示例 5
用户的请求:检测红色运动汽车
原始概念: "Red sports car"
最终输出:
{
"reasoning": "提供的图像中没有 'red sports car' 的可靠检测。基于颜色的检测可能具有挑战性。优化为更通用的概念 'car' 可能会提高检测效果。",
"refined_list": "car"
}
记住:
• 如果不需要优化(概念被很好地识别),在推理中解释这一点并返回相同的概念。
• 当需要优化时,优先考虑更通用或抽象的类别,这些类别可能更容易被模型检测到。
• 仅提供 JSON。
• 没有额外的评论。
"""
},
{"role": "user", "content": [
{"type": "text", "text": f"用户的请求: {user_request}\n 原始检测概念: {original_concepts}"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_labeled_image}", "detail": "high"}}
]}
]
refine_response = self.vlm_tool.chat_completion(refine_messages, model=model, response_format={"type": "json_object"})
refined_response_objects = json.loads(refine_response)["refined_list"].split(",")
if not refined_response_objects:
return []
refined_list = [r.strip().lower() for r in refined_response_objects if r.strip()]
return refined_list
一般来说,开放词汇检测器可以识别只有几百个粗粒度类别——“狗”、“车”、“花”——但用户经常要求更细粒度的目标:茶杯贵宾犬、闪亮的细高跟鞋等。当请求的标签超出检测器的舒适区时,模型可能返回空或一系列低置信度的框。
在批评和优化阶段,LLM 同时接收三件事:用户的原始文本、箭头标注的图像和传递给检测器的精确概念列表。然后它推理:“在这些标签下,检测器是否找到了有意义的东西?如果没有,这些标签是否只是太具体?”每当这种情况发生时,LLM 会特意向上抽象每个概念到下一个更高层次的概念,例如子品种变为品种(茶杯贵宾犬 → 狗),复杂的颜色概念被剥离(明亮的红色复古跑车 → 车)。模型返回这些更高层次的类别作为逗号分隔的字符串。
只有当精炼列表不同于原始列表时,流程才会支付第二次检测器传递的费用,其中我们使用精炼的类别再次运行对象检测器。这意味着额外的推理时间计算仅在必要时选择性地花费,精确地当第一次尝试未能弥合用户意图和检测器词汇之间的差距时。简而言之,LLM 将用户的请求映射到检测器更熟悉的类别,通过再次调用对象检测器来获得输出的另一次机会。
3.6 利用 VLM 验证边界框预测
箭头标注的图像被编码并传递给语言模型,该模型根据用户的请求接受或拒绝每个编号的框。输出必须是严格的 JSON(例如,{“3”: “cup”, “5”: “teapot”})以确保确定性解析。这标志着下一步验证,利用 VLM 过滤检测器的输出**。**
def _validate_bboxes_with_llm(self, user_request, labeled_image_path, model="o1"):
"""
将标注的图像传递给 LLM 以根据用户请求过滤边界框
返回 'valid_numbers' 列表。
"""
base64_labeled_image = encode_image(labeled_image_path)
messages = [
{"role": "system", "content": "你是一个审查对象检测输出的 AI。\n"
"所有检测到的对象都用箭头映射到相应的数字。\n"
"图像包含指向特定对象的数字箭头。\n"
"你的任务是识别这些箭头指示的对象并确定每个检测到的对象是否与用户的查询相关。\n"
"对于每个编号的箭头:\n"
"1. 识别被指向的对象。\n"
"2. 提供对象的简要描述(例如,'左上角的蓝色叶子杯子','右下角的西瓜图案杯子',或'背景鸟笼')。\n"
"3. 分析对象是否符合上下文和用户的指示。\n"
"4. 为每个对象的有效性决策提供清晰、逐步的解释。\n"
"返回一个包含推理和与用户请求匹配的有效数字列表的 JSON 对象。\n"
"示例输出:\n"
"{ \"reasoning\": <reasoning> , \"valid_numbers\": {object_num :\"object_name\"} }"
},
{"role": "user", "content": [
{"type": "text", "text": f"用户的原始请求是: {user_request}"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_labeled_image}", "detail": "high"}}
]
}
]
valid_numbers_json = self.vlm_tool.chat_completion(
messages,
model=model,
response_format={"type": "json_object"}
)
try:
valid_numbers_data = json.loads(valid_numbers_json)
return valid_numbers_data.get("valid_numbers", {})
except json.JSONDecodeError:
return []
在精炼的概念列表通过对象检测器第二次运行后,流程现在移动到检查预测。新的边界框被绘制在原始帧上,每个都带有自己的箭头和索引。而不是分别发送每个裁剪,整个箭头标注的图像被 base-64 编码并作为一个负载传递给语言模型。
验证步骤专注于一个狭窄的任务:框 7,如所示,是否符合用户的请求?提示迫使模型以严格的 JSON 映射如 {“3”: “cup”, “5”: “teapot”} 回答。整数与箭头编号确定性对齐,让代码接受或拒绝框而没有任何歧义或模糊匹配。
简而言之,两个 VLM 步骤是连续进行的:第一步在初始查询的预测不满意时,将用户的查询重写为更符合检测器词汇的形式;第二步审查和过滤模型的预测,以提供最终输出。
从这一步获得的最终预测然后被绘制为边界框回到图像上。将整个流程组合在一起,这就是我们的最终实现:
def run(self, image_path, user_request, do_critique=True):
"""
完整流程:
1. 从用户请求中提取对象(LLM)。
2. 使用该查询检测边界框。
3. LLM 基于验证步骤 => 过滤边界框。
4. (可选)批评步骤 => 如果需要,优化查询。
5. 使用优化的查询重新运行检测。
6. 最终 LLM 验证 => 最终边界框和注释。
"""
# ---------------------------------------------------
# 第 1 步:从请求中提取初始用户查询
# ---------------------------------------------------
objects_to_detect = self.vlm_tool.extract_objects_from_request(image_path, user_request, model=self.concept_detection_model)
if not objects_to_detect:
return None, "⚠️ 没有要检测的对象或无效请求。"
# ---------------------------------------------------
# 第 2 步:使用初始用户查询运行检测
# ---------------------------------------------------
detected_objects_final, labeled_image_path = self._run_detector(image_path, objects_to_detect)
# ------------------------------------------------------
# 第 3 步:初始批评和对象概念优化
# ------------------------------------------------------
if do_critique:
current_labels = ",".join(set([str(lbl) for _, lbl, _ in detected_objects_final]))
refined_query_list = self._critique_and_refine_query(
user_request=user_request,
original_concepts=current_labels,
labeled_image_path=labeled_image_path,
objects_detected=current_labels,
model=self.initial_critique_model
)
# 如果精炼列表为空或相同,我们可能跳过重新运行
# 但假设我们只在获得新集合时重新运行。
if refined_query_list and set(refined_query_list) != set(objects_to_detect):
# 使用精炼查询重新运行检测
detected_objects_final, labeled_image_path = self._run_detector(image_path, refined_query_list)
if not detected_objects_final:
return None, "初始查询没有找到对象。"
# ---------------------------------------------------
# 第 4 步:基于 LLM 的批评
# ---------------------------------------------------
valid_numbers = self._validate_bboxes_with_llm(user_request, labeled_image_path, model=self.final_critique_model)
# 过滤边界框
if valid_numbers:
filtered_objects = [(n, valid_numbers[str(n)], box) for (n, lbl, box) in detected_objects_final if str(n) in valid_numbers]
else:
filtered_objects = detected_objects_final
# 存储它们
self.last_detection_bboxes = [x[-1] for x in filtered_objects]
self.last_filtered_objects = filtered_objects
# ---------------------------------------------------
# 第 5 步:生成最终注释图像
# ---------------------------------------------------
final_img = draw_bounding_boxes(image_path, filtered_objects)
final_text = (
f"🔍 验证对象: {', '.join(set(str(lbl) for _, lbl, _ in filtered_objects))}"
)
return final_img, final_text
这个类的完整实现可在 此链接 中找到。
4、结果
我们实现了这个功能并通过 Gradio 应用程序进行了展示。我们借助一张示例图像来演示这个流程。我们使用提示“检测左上角的 iPod 和右下角的 iPhone。”来测试我们的代理的检测能力。该流程提取这两个设备概念,运行检测器,让 LLM 在必要时拓宽或优化,并最终验证每个编号的框。
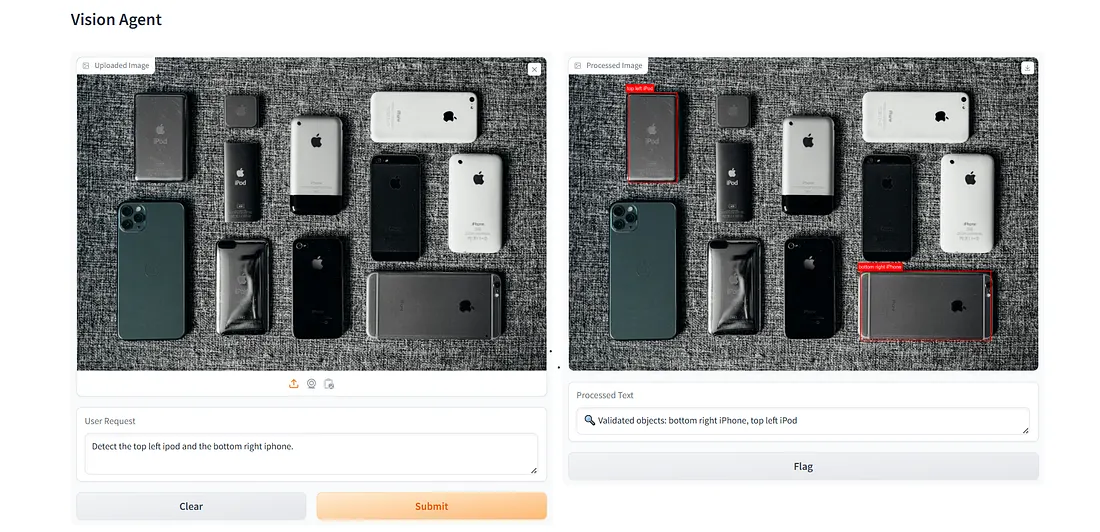
代理对象检测流程的 Gradio 界面。本演示中使用的照片由 Tron Le 在 Unsplash 上拍摄。(整体图像由作者提供)


这个例子突出了该流程的一个关键优势:方向精度。开放词汇检测器已经在识别 iPhone 和 iPod 方面表现出色,提供了很高的召回率。然后 VLM 对整个带有箭头标注的图像进行推理,并仅指出符合用户空间指令的设备。通过这种全局、上下文感知的检查过滤检测,该系统实现了高精度,返回了提示所要求的确切对象。我们还通过第二个例子展示了该流程的优势。我们使用了一张包含两个咖啡杯的图像,每个杯子都有泡沫艺术。我们提示代理系统仅检测带有泡沫艺术“Coffee Chat?”的咖啡杯。



此场景展示了代理流程的另一个优势:识别包含可读文本的对象。在右上方的例子中,检测器正确标记了两个咖啡杯,实现了高召回率。然而,只有其中一个杯子包含用户提示中指定的泡沫艺术。由于VLM会审查整个带有箭头标注的图像,并能理解每个杯子上的文字,它可以排除不相关的杯子并保留符合查询的预测。这种文本感知推理是对象检测器所不具备的,有助于获得有针对性且精确的结果。
5、结束语
代理对象检测提供了一个强大而灵活的框架,用于获取针对性的对象检测结果。在这篇博客文章中,我们展示了如何通过由VLM驱动的代理层来增强像Grounding DINO这样的开放词汇检测器。这个代理不仅能够解释和细化用户的请求,还能在上下文中对检测器的输出进行批判和验证,从而得到更精确、与用户需求一致的结果。通过将检测与推理相结合,该系统超越了简单的物体识别,朝着更加针对性的视觉理解发展。
当前流程的一个关键限制是,它只能检测底层开放词汇检测器已经知道的内容。如果用户请求一个检测器无法识别的类别,例如特定的花朵或新的设备,那么在当前流程中无论多少VLM推理都无法帮助,因为当前流程仅利用VLM来审查和批判初始对象检测器的结果。相比之下,像OpenAI的o3、Google Gemini和其他研究模型这样的VLM可以将其多模态输出的一部分直接生成边界框。而不是依赖于单独处理不同任务的系统,诸如对象检测等能力正在越来越多地被整合到现有VLM的训练阶段中。
原文链接:Building an Agentic Object Detection Pipeline
汇智网翻译整理,转载请标明出处
