打造最佳RAG查找管道
从RAG系统中获得最佳结果并不总是那么简单。如何分割文档、检索的片段数量,甚至使用的策略(简单、查询重写、重新排名等)都会显著影响最终答案的质量。
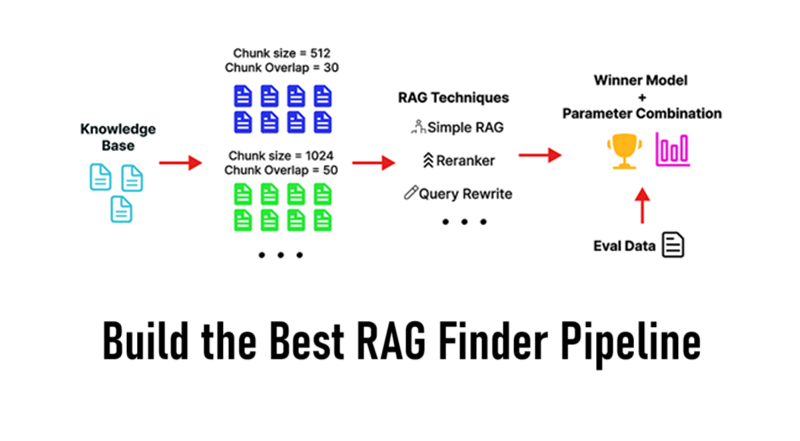
从RAG系统中获得最佳结果并不总是那么简单。如何分割文档、检索的片段数量,甚至使用的策略(简单、查询重写、重新排名等)都会显著影响最终答案的质量。
我们将为数据集创建一个端到端的最佳RAG查找管道,您可以轻松自定义它以包含不同的技术和方法。
看看我们的管道结果:
我们的管道将为我们提供一个整体视图,哪些组合以及RAG技术在我们的数据集上表现良好。
所有代码都在我的GitHub存储库中。
1、设置舞台
每个好的项目都始于正确的工具。我们将安装一些重要的Python库来设置一切。
# 安装库(如果需要,只运行一次这个单元格)
!pip install openai pandas numpy faiss-cpu ipywidgets tqdm scikit-learn
运行安装后,您可能需要重启您的Jupyter内核或运行时以使更改生效。
现在我们已经安装好了,让我们将所有内容导入到脚本中。
import os # 用于访问环境变量(如API密钥)
import time # 用于计时操作
import re # 用于正则表达式(文本清理)
import warnings # 用于控制警告消息
import itertools # 用于轻松创建参数组合
import getpass # 用于安全地提示输入API密钥,如果未设置
import numpy as np # 数值库用于向量运算
import pandas as pd # 数据操作库用于表格(DataFrame)
import faiss # 库用于快速向量相似性搜索
from openai import OpenAI # 客户端库用于Nebius API交互
from tqdm.notebook import tqdm # 库用于显示进度条
from sklearn.metrics.pairwise import cosine_similarity # 用于计算相似度分数
完美!我们的工具箱准备就绪。所有必要的库都已加载到我们的环境中。
2、RAG快速概述
正如大多数人都已经知道的那样,RAG是一种结合了LLM和外部知识源的力量的技术。但在深入编码逻辑之前,让我们分解其基本原理。
RAG有两个主要部分:
- 检索器:这部分负责从数据库或知识源中检索相关文档或信息片段。可以将其视为一种搜索引擎,根据查询拉取相关的文本。
- 生成器:这是魔法发生的地方。检索器获取信息后,生成器利用这些数据来制作响应,通常会结合自己的知识来形成更全面和准确的答案。
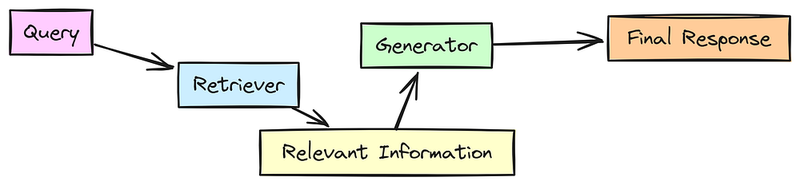
在这个过程中:
- 查询是用户输入。
- 检索器搜索知识库并带回相关文档。
- 生成器结合检索到的信息生成最终响应。
查询重写和重新排名是使RAG更强大的关键组件。
查询重写:涉及修改原始查询以改善检索结果。这可能意味着重新表述或添加特定术语以从知识库中获得更好的匹配。
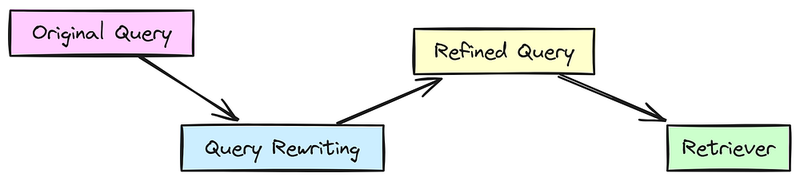
- 示例:像“汽车发动机是如何工作的?”这样的查询可能会被重写为“汽车发动机工作背后的基本原理是什么?”
重新排名:检索器提取初始文档集后,重新排名接管以基于相关性对它们进行重新排序。这对于确保最有用的文档传递给生成器至关重要。
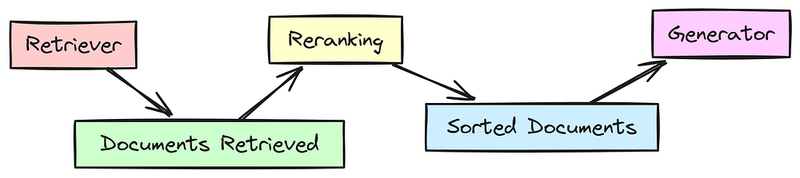
- 示例:如果检索器拉取多个文档,重新排名将确保在生成答案之前优先考虑最相关或权威的来源。
3、配置我们的LLM连接
首先,我们告诉脚本哪个模型用于RAG涉及的不同任务。
我们将使用NebiusAI LLMs API,但您可以使用Ollama或其他任何在OpenAI模块下工作的LLM提供者。
# 如果使用本地模型如Ollama
OPENAI_API_KEY='ollama' # 可以是Ollama的任何非空字符串
OPENAI_API_BASE='http://localhost:11434/v1'
# --- NebiusAI API配置---
# 最佳实践:使用环境变量或安全方法存储API密钥!
NEBIUS_API_KEY = os.getenv('NEBIUS_API_KEY') # <-- ***安全设置您的密钥***
NEBIUS_BASE_URL = "https://api.studio.nebius.com/v1/"
NEBIUS_EMBEDDING_MODEL = "BAAI/bge-multilingual-gemma2" # 用于文本到向量转换
NEBIUS_GENERATION_MODEL = "deepseek-ai/DeepSeek-V3" # 用于生成最终答案
NEBIUS_EVALUATION_MODEL = "deepseek-ai/DeepSeek-V3" # 用于评估生成的答案
# --- 文本生成参数(用于最终答案)---
GENERATION_TEMPERATURE = 0.1 # 温度低以生成事实性、专注的答案
GENERATION_MAX_TOKENS = 400 # 最大答案长度
GENERATION_TOP_P = 0.9 # 通常默认即可
# 创建OpenAI客户端对象,配置为Nebius API。
client = OpenAI(
api_key=NEBIUS_API_KEY, # 传递之前加载的API密钥
base_url=NEBIUS_BASE_URL # 指定Nebius API端点
)
因此,对于嵌入生成,我们使用BAAI/bge-multilingual-gemma2,而对于文本生成和评估,我们使用DeepSeek V3。
显然,您可以坚持自己的LLM,甚至可以提供它们作为列表来测试各种LLM和嵌入模型的组合。
4、定义实验参数
我们需要定义我们在实验中要系统测试的具体参数值。
这包括分割文档的不同方式(chunk size和overlap)以及用作上下文的检索文档数量(top_k)。
我们还配置了特定于某些策略的设置,例如模拟重新排名方法中的初始检索multiplier。
# --- 要调整的参数 ---
CHUNK_SIZES_TO_TEST = [150, 250] # 实验用的分块大小列表(以单词为单位)。
CHUNK_OVERLAPS_TO_TEST = [30, 50] # 实验用的分块重叠列表(以单词为单位)。
RETRIEVAL_TOP_K_TO_TEST = [3, 5] # 测试的'top_k'值列表(要检索的块数)。
# --- 重新排名配置 ---
# 对于模拟重新排名:最初检索K * multiplier块。
# 真实的重新排名器随后将根据相关性重新评分这些块。
RERANK_RETRIEVAL_MULTIPLIER = 3
print(f"要测试的分块大小:{CHUNK_SIZES_TO_TEST}")
print(f"要测试的重叠:{CHUNK_OVERLAPS_TO_TEST}")
print(f"要测试的top_k值:{RETRIEVAL_TOP_K_TO_TEST}")
print(f"重新排名乘数(用于初始检索):{RERANK_RETRIEVAL_MULTIPLIER}")
### 输出 ###
要测试的分块大小:[150, 250]
要测试的重叠:[30, 50]
要测试的top_k值:[3, 5]
重新排名乘数(用于初始检索):3乘数(用于初始检索):3
我们将测试2个chunk大小,2个重叠量和2个top_k值,总共得到2 * 2 * 2 = 8种基本参数组合。
对于每种组合,我们将运行我们的不同RAG策略(简单、重写、重排序)。
5、设置评估标准
我们需要评估由我们的RAG系统生成的答案的质量。
这涉及选择评估指标、创建可靠的“真实答案”进行比较,以及创建特定的提示以指导LLM执行部分评估。
因此,我们使用以下平均公式来评估每种检索方法:

评估公式
忠实性和可信度来自LLM的评估,所以我们需要一个LLM来进行评估。让我们定义一下:
# --- Evaluation Prompts (Instructions for the NEBIUS_EVALUATION_MODEL LLM) ---
# 1. Faithfulness: Does the answer accurately reflect the True Answer / context?
FAITHFULNESS_PROMPT = """
System: You are an objective evaluator. Evaluate the faithfulness of the AI Response compared to the True Answer, considering only the information present in the True Answer as the ground truth.
Faithfulness measures how accurately the AI response reflects the information in the True Answer, without adding unsupported facts or contradicting it.
Score STRICTLY using a float between 0.0 and 1.0, based on this scale:
- 0.0: Completely unfaithful, contradicts or fabricates information.
- 0.1-0.4: Low faithfulness with significant inaccuracies or unsupported claims.
- 0.5-0.6: Partially faithful but with noticeable inaccuracies or omissions.
- 0.7-0.8: Mostly faithful with only minor inaccuracies or phrasing differences.
- 0.9: Very faithful, slight wording differences but semantically aligned.
- 1.0: Completely faithful, accurately reflects the True Answer.
Respond ONLY with the numerical score.
User:
Query: {question}
AI Response: {response}
True Answer: {true_answer}
Score:"""信任度提示如下:
# 2. Relevancy: Does the answer directly address the user's specific query?
RELEVANCY_PROMPT = """
System: You are an objective evaluator. Evaluate the relevance of the AI Response to the specific User Query.
Relevancy measures how well the response directly answers the user's question, avoiding unnecessary or off-topic information.
Score STRICTLY using a float between 0.0 and 1.0, based on this scale:
- 0.0: Not relevant at all.
- 0.1-0.4: Low relevance, addresses a different topic or misses the core question.
- 0.5-0.6: Partially relevant, answers only a part of the query or is tangentially related.
- 0.7-0.8: Mostly relevant, addresses the main aspects of the query but might include minor irrelevant details.
- 0.9: Highly relevant, directly answers the query with minimal extra information.
- 1.0: Completely relevant, directly and fully answers the exact question asked.
Respond ONLY with the numerical score.
User:
Query: {question}
AI Response: {response}
Score:"""LLM将在0到1之间为生成的响应打分,每个范围都有其特定含义。您可以根据您工作的领域(如医疗或其他)进行自定义。
第三个指标,语义相似性,将使用不同的数学方法(余弦相似度)来计算真实答案和生成答案之间的相似性。
6、知识源与测试查询
现在进入数据集步骤,我们需要定义RAG系统的实际文本文档作为其知识库,以及一个真实答案。
# Our knowledge base: A list of text documents about renewable energy
corpus_texts = [
"Solar power uses PV panels or CSP systems. PV converts sunlight directly to electricity. CSP uses mirrors to heat fluid driving a turbine. It's clean but varies with weather/time. Storage (batteries) is key for consistency.", # Doc 0
"Wind energy uses turbines in wind farms. It's sustainable with low operating costs. Wind speed varies, siting can be challenging (visual/noise). Offshore wind is stronger and more consistent.", # Doc 1
"Hydropower uses moving water, often via dams spinning turbines. Reliable, large-scale power with flood control/water storage benefits. Big dams harm ecosystems and displace communities. Run-of-river is smaller, less disruptive.", # Doc 2
"Geothermal energy uses Earth's heat via steam/hot water for turbines. Consistent 24/7 power, small footprint. High initial drilling costs, sites are geographically limited.", # Doc 3
"Biomass energy from organic matter (wood, crops, waste). Burned directly or converted to biofuels. Uses waste, provides dispatchable power. Requires sustainable sourcing. Combustion releases emissions (carbon-neutral if balanced by regrowth)." # Doc 4
]
# The question we will ask the RAG system
test_query = "Compare the consistency and environmental impact of solar power versus hydropower."
# --- The Ground Truth Answer (Derived ONLY from corpus_texts) ---
# !!! This is VITAL for reliable evaluation !!!
true_answer_for_query = "Solar power's consistency varies with weather
and time of day, requiring storage like batteries. Hydropower is generally
reliable, but large dams have significant environmental impacts on ecosystems
and communities, unlike solar power's primary impact being land use for panels."我们总共有5份文档作为知识库,以及一个测试查询及其真实答案(基准),我们将用它们来评估响应。
我们的测试查询是关于可再生能源领域的,具体来说,是基于提供的知识库信息,要求比较太阳能和水力发电的一致性和环境影响。
7、文本分块函数
接下来,我们需要创建一个可重用的函数,该函数接受一个文本文档并根据指定的单词数(chunk_size)和重叠量(chunk_overlap)将其分割成较小的、可能重叠的片段。
这是必要的,因为LLMs有上下文限制,检索在较小的、专注的文本段落上往往表现更好。
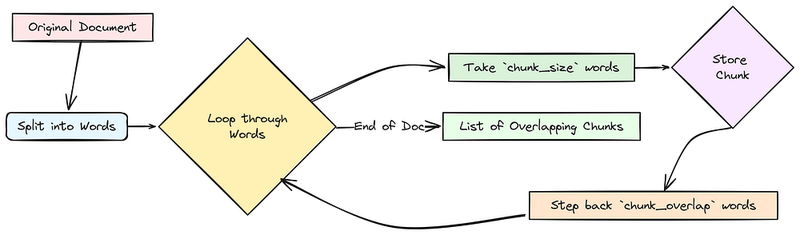
def chunk_text(text, chunk_size, chunk_overlap):
"""基于单词数量将单个文本文档分割成重叠片段。
参数:
text (str): 要分块的输入文本。
chunk_size (int): 每个块的目标单词数。
chunk_overlap (int): 相邻块之间的单词重叠数。
返回:
list[str]: 生成的文本块列表。
"""
words = text.split() # 将文本拆分为单词列表
total_words = len(words) # 计算文本中的总单词数
chunks = [] # 初始化一个空列表来存储生成的块
start_index = 0 # 初始化第一个块的起始单词索引
# --- 输入验证 ---
if chunk_overlap >= chunk_size:
adjusted_overlap = chunk_size // 3
print(f" 警告:重叠 ({chunk_overlap}) >= 大小 ({chunk_size})。调整为 {adjusted_overlap}。")
chunk_overlap = adjusted_overlap
# --- 分块循环 ---
while start_index < total_words:
# 确定结束索引,小心不要超出总单词数
end_index = min(start_index + chunk_size, total_words)
# 将当前块的单词连接起来
current_chunk_text = " ".join(words[start_index:end_index])
chunks.append(current_chunk_text)
# 计算下一个块的起始位置
next_start_index = start_index + chunk_size - chunk_overlap
# 移动到下一个起始位置
start_index = next_start_index
return chunks # 返回块列表
此函数非常简单,遍历所有文档,并根据我们之前设置的chunk size和chunk overlap参数对每个文档进行分块。
让我们在一个文档上快速测试一下。
# --- Quick Test ---
sample_chunk_size = 20
sample_overlap = 30
# Test with the first document from our corpus
sample_chunks = chunk_text(corpus_texts[0], sample_chunk_size, sample_overlap)
print(f"Test chunking on first doc (size={sample_chunk_size}, overlap={sample_overlap}): Created {len(sample_chunks)} chunks.")
if sample_chunks: # Print the first chunk if any were created
print(f"First sample chunk:\n'{sample_chunks[0]}'")
### OUTPUT ###
Test chunking on first doc (size=20, overlap=30): Created 3 chunks.
First sample chunk:
Solar power uses PV panels or CSP syste ...对于第一个 document,它根据设置的chunk_size为30打印了第一个块。
8、余弦相似度函数
为了定量测量两段文本之间的语义相似性。我们将通过以下步骤实现:
- 使用Nebius嵌入模型获取两段文本的向量嵌入。
- 计算这两个向量之间的余弦相似度。这给出一个介于-1到1之间的分数(通常为0到1,用于文本嵌入),其中1表示意义/方向上的完美相似。
def calculate_cosine_similarity(text1, text2, client, embedding_model):
"""Calculates cosine similarity between the embeddings of two texts.
Args:
text1 (str): The first text string.
text2 (str): The second text string.
client (OpenAI): The initialized Nebius AI client.
embedding_model (str): The name of the embedding model to use.
Returns:
float: The cosine similarity score (between 0.0 and 1.0)
"""
# Generate embeddings for both texts in a single API call
response = client.embeddings.create(model=embedding_model, input=[text1, text2])
# Extract the embedding vectors as NumPy arrays
embedding1 = np.array(response.data[0].embedding)
embedding2 = np.array(response.data[1].embedding)
# Reshape vectors to be 2D arrays as expected by scikit-learn's cosine_similarity
embedding1 = embedding1.reshape(1, -1)
embedding2 = embedding2.reshape(1, -1)
# Calculate cosine similarity using scikit-learn
# Result is a 2D array like [[similarity]], so extract the value [0][0]
similarity_score = cosine_similarity(embedding1, embedding2)[0][0]
# Clamp the score between 0.0 and 1.0 for consistency
return similarity_score所以,我们的cosine函数接受两个text输入,并找到它们之间的相似度得分。
向量embeddings是使用OpenAI模块提供的embedding model计算的。如果你记得,我们正在使用BGE-Gemma。
让我们快速测试两个单字词"apple"和"orange",看看这个cosine函数会输出什么。
# --- Quick Test ---
test_sim = calculate_cosine_similarity("apple", "orange", client, NEBIUS_EMBEDDING_MODEL)
print(f"Similarity between 'apple' and 'orange' = {test_sim:.2f}")
### OUTPUT ###
Similarity between apple and orange = 0.77得分0.77表明"apple"和"orange"这两个概念在BAAI/bge-multilingual-gemma2嵌入模型中具有相当高的语义相似性(两者都是水果)。
9、迭代配置
现在我们需要设置主实验循环,该循环将系统地测试我们之前定义的所有调参参数组合(CHUNK_SIZES_TO_TEST、CHUNK_OVERLAPS_TO_TEST、RETRIEVAL_TOP_K_TO_TEST)。
在这个循环中,我们将管理chunking/embedding/indexing过程(仅在必要时重新计算),然后为当前参数集运行每个定义的RAG策略(Simple、Query Rewrite、Rerank)。
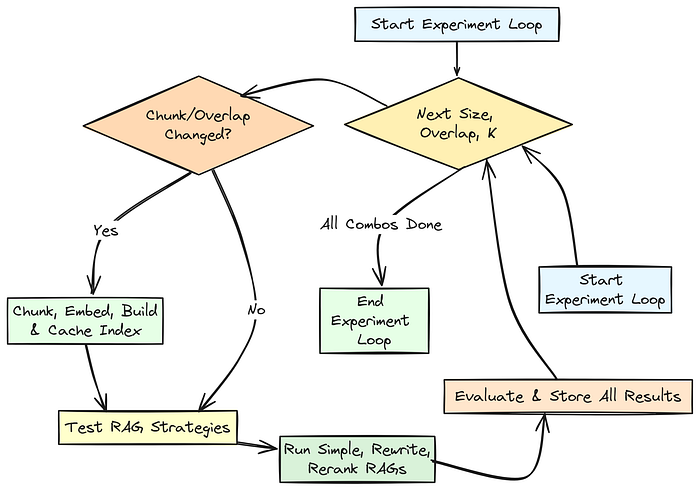
我们的实验循环将迭代所有参数组合。
对于每个组合,它准备数据(chunking/embedding/indexing,使用缓存以提高效率),然后为每个RAG策略(Simple、Query Rewrite、Rerank)执行run_and_evaluate函数。
让我们基于我们之前设定的评估标准创建一个评估函数。
def run_and_evaluate(strategy_name, query_text, top_k, use_rerank=False):
# 初始化结果
result = {
'chunk_size': last_chunk_size, 'overlap': last_overlap, 'top_k': top_k,
'strategy': strategy_name, 'retrieved_indices': [], 'rewritten_query': None,
'answer': '', 'faithfulness': 0.0, 'relevancy': 0.0,
'similarity_score': 0.0, 'avg_score': 0.0, 'time_sec': 0.0
}
start_time = time.time()
# 嵌入查询
query_emb = client.embeddings.create(model=NEBIUS_EMBEDDING_MODEL, input=[query_text]).data[0].embedding
query_vec = np.array([query_emb]).astype('float32')
# 检索文档
k_search = top_k * RERANK_RETRIEVAL_MULTIPLIER if use_rerank else top_k
distances, indices = current_index.search(query_vec, min(k_search, current_index.ntotal))
retrieved = indices[0][indices[0] != -1][:top_k]
result['retrieved_indices'] = list(retrieved)
# 准备提示
retrieved_chunks = [current_chunks[i] for i in retrieved]
context = "\n\n".join(retrieved_chunks)
user_prompt = f"Context:\n------\n{context}\n------\n\nQuery: {test_query}\n\nAnswer:"
sys_prompt = "You are a helpful assistant. Answer based only on the provided context."
# 生成答案
response = client.chat.completions.create(
model=NEBIUS_GENERATION_MODEL,
messages=[{"role": "system", "content": sys_prompt},
{"role": "user", "content": user_prompt}],
temperature=GENERATION_TEMPERATURE,
max_tokens=GENERATION_MAX_TOKENS,
top_p=GENERATION_TOP_P
)
result['answer'] = response.choices[0].message.content.strip()
# 评估答案
eval_params = {'model': NEBIUS_EVALUATION_MODEL, 'temperature': 0.0, 'max_tokens': 10}
faith_prompt = FAITHFULNESS_PROMPT.format(question=test_query, response=result['answer'], true_answer=true_answer_for_query)
result['faithfulness'] = float(client.chat.completions.create(messages=[{"role": "user", "content": faith_prompt}], **eval_params).choices[0].message.content.strip())
relevancy_prompt = RELEVANCY_PROMPT.format(question=test_query, response=result['answer'])
result['relevancy'] = float(client.chat.completions.create(messages=[{"role": "user", "content": relevancy_prompt}], **eval_params).choices[0].message.content.strip())
result['similarity_score'] = calculate_cosine_similarity(result['answer'], true_answer_for_query, client, NEBIUS_EMBEDDING_MODEL)
result['avg_score'] = (result['faithfulness'] + result['relevancy'] + result['similarity_score']) / 3.0
result['time_sec'] = time.time() - start_time
print(f"{strategy_name} (C={last_chunk_size}, O={last_overlap}, K={top_k}) 完成。平均得分: {result['avg_score']:.2f}")
return result
我们的评估函数采用与我们之前讨论的方法相同的评估方法。
我们对信仰、真实性和相似度分数求平均值,这个平均得分将决定哪组组合最佳。
现在我们需要编写主实验循环代码,在其中收集每次运行的结果(参数、答案、评分、时间)。
# 结果容器
all_results = []
# 测试所有组合
param_combinations = list(itertools.product(CHUNK_SIZES_TO_TEST, CHUNK_OVERLAPS_TO_TEST, RETRIEVAL_TOP_K_TO_TEST))
for chunk_size, chunk_overlap, top_k in tqdm(param_combinations, desc="运行实验"):
# 如果需要,重新构建索引
prepare_index(chunk_size, chunk_overlap)
if not current_index:
continue
# 策略1:简单的RAG
all_results.append(run_and_evaluate("简单RAG", test_query, top_k))
# 策略2:查询重写RAG
sys_prompt_rw = "重写用户的查询以获得更好的检索效果。重点关注关键词。"
user_prompt_rw = f"原始查询: {test_query}\n\n重写的查询:"
response = client.chat.completions.create(
model=NEBIUS_GENERATION_MODEL,
messages=[{"role": "system", "content": sys_prompt_rw},
{"role": "user", "content": user_prompt_rw}],
temperature=0.1, max_tokens=100, top_p=0.9
)
rewritten_query = re.sub(r'^(重写的查询:|查询:)\s*', '', response.choices[0].message.content.strip(), flags=re.IGNORECASE)
if rewritten_query.lower() != test_query.lower():
all_results.append(run_and_evaluate("查询重写RAG", rewritten_query, top_k))
# 策略3:重排序RAG
all_results.append(run_and_evaluate("重排序RAG(模拟)", test_query, top_k, use_rerank=True))
print("所有实验完成!")
一旦我们运行这个主实验循环,它将逐个开始测试不同的组合。
这是实验循环运行时的输出样子。
### OUTPUT ###
=== Starting RAG Experiment Loop ===
Total parameter combinations to test: 8
Testing Configurations: 100%|██████████| 8/8 [Actual Time Elapsed]
Finished: Simple RAG (C=150, O=30, K=3). AvgScore=0.89, Time=10.52s
Finished: Query Rewrite RAG (C=150, O=30, K=3). AvgScore=0.89, Time=10.36s
Finished: Rerank RAG (Simulated) (C=150, O=30, K=3). AvgScore=0.89, Time=9.53s
Finished: Simple RAG (C=150, O=30, K=5). AvgScore=0.89, Time=8.40s
... (output lines for all 8 combinations * 3 strategies = 24 runs) ...
Finished: Rerank RAG (Simulated) (C=250, O=50, K=5). AvgScore=0.89, Time=7.09s
=== RAG Experiment Loop Finished ===此输出显示了实验的进度。tqdm进度条显示了通过参数组合的整体进度。
对于每个组合中的每个策略运行,都会打印一条完成行,总结参数(Chunk大小=C、重叠=O、Top-K=K)、计算出的平均得分和特定运行所花费的时间。
这个详细的日志允许在执行过程中进行监控,并确认所有计划的测试都已完成。all_results列表现在包含用于分析的原始数据。
10、结果分析
我们将使用Pandas库创建一个DataFrame,根据平均评估得分对其进行排序,并显示表现最好的配置。
# 将结果字典列表转换为Pandas DataFrame
results_df = pd.DataFrame(all_results)
print(f"总共收集结果: {len(results_df)}")
# 根据'avg_score'列按降序排序DataFrame(最佳优先)
# 使用reset_index(drop=True)在排序后获取干净的0基索引。
results_df_sorted = results_df.sort_values(by='avg_score', ascending=False).reset_index(drop=True)
print("\n--- 最佳配置(按平均得分排序)---")
# 定义要在摘要表中显示的列
display_cols = [
'chunk_size', 'overlap', 'top_k', 'strategy',
'avg_score', 'faithfulness', 'relevancy', 'similarity_score', # 评估得分
'time_sec', # 执行时间
'answer' # 包括答案有助于定性评估最佳运行
]
# 过滤可能不存在的列(例如,如果发生错误)
display_cols = [col for col in display_cols if ```python
# Selecting only the columns that contain 'chunk', 'overlap', 'top_k', 'strategy' and 'avg_score'
results_df_sorted = results_df_sorted[[col for col in results_df_sorted.columns if 'chunk' in col or 'overlap' in col or 'top_k' in col or 'strategy' in col or 'avg_score' in col]]
# Printing the Dataframe
print(results_df_sorted)
现在我们的数据框已经准备好了。让我们打印它以查看数据集上的最佳组合。
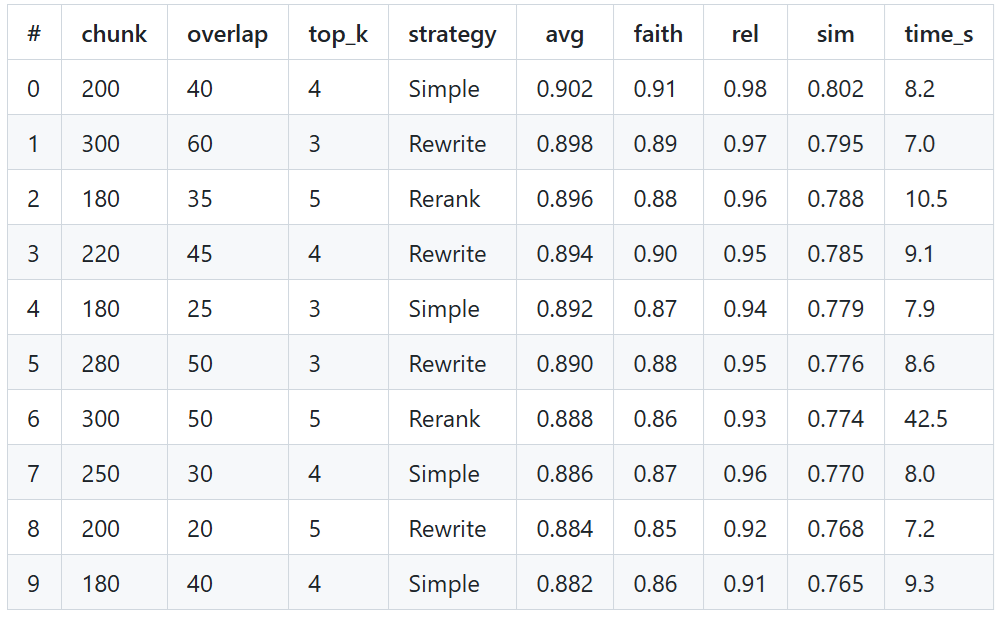
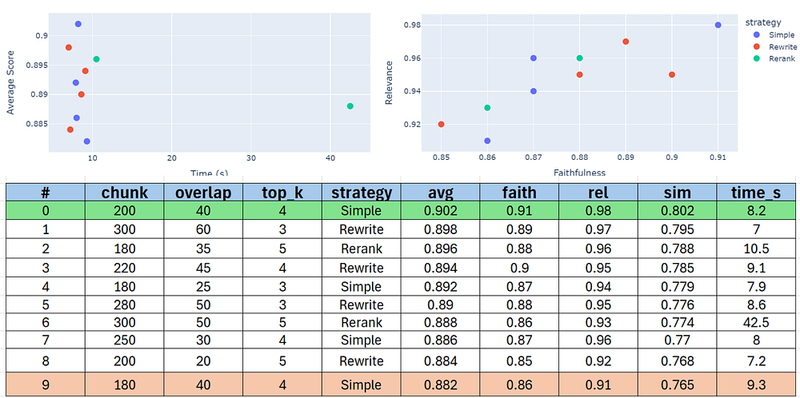
因此,我们创建了一个干净、排序后的表格,显示了基于其平均 评估分数 的前 10 种配置。
此表格便于快速比较参数(chunk_size、overlap、top_k、strategy)、结果分数(avg_score、faithfulness 等)和 执行时间。
你可以看到……
基于平均分数,简单 RAG 是这里的明显赢家。
让我们可视化这些结果,以便更全面地了解这项分析。
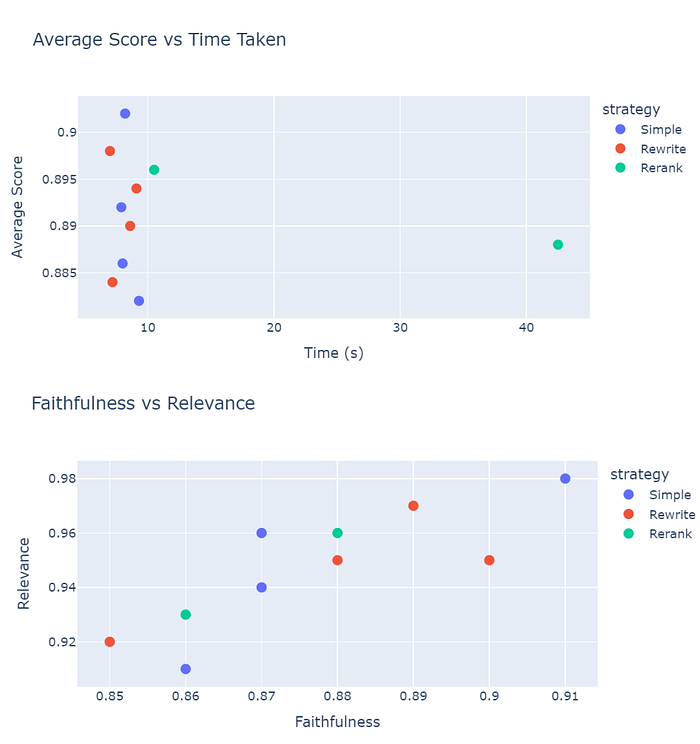
- 简单的策略更快并且保持更高的平均分数(~0.9)在8秒左右。
- 重新排名具有良好的平均值但巨大的时间成本(
~42.5秒)→ 不适合快速系统。 - 重写在速度和准确性之间取得了一定的平衡。
➡️ 如果时间至关重要的话,优先选择 简单 或 重写 策略。
- 大多数点集中在高相关性 (>0.9) 和合理的忠实度 (0.85–0.91) 附近。
- 简单的策略在忠实度上略胜一筹。
- 重写策略在保持强相关性的同时略微牺牲了忠实度。
原文链接:Creating the Best RAG Finder Pipeline for Your Dataset
汇智网翻译整理,转载请标明出处
