构建自己的AI视频处理应用
过去,进行视频处理需要创建一个完整的流程:一个服务用于提取音频,另一个用于语音转文本,可能还需要OCR模型来从幻灯片中提取文本,然后还需要一个总结器将所有内容整合在一起。

在这篇文章中,我为你准备了两件重要的事情:
- 一种简化且由AI驱动的构建视频处理应用程序的方法,并附带你可以复制的代码。
- 探讨这个应用程序的架构对未来软件的意义。
过去,进行视频处理需要创建一个完整的流程:一个服务用于提取音频,另一个用于语音转文本,可能还需要OCR模型来从幻灯片中提取文本,然后还需要一个总结器将所有内容整合在一起。这需要大量工作。结果发现,现在有一种强大且简化的实现方式。
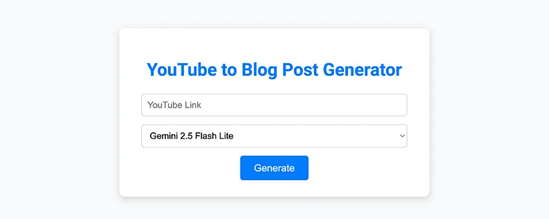
为了尝试这种新的做法,我构建了一个应用程序,它以YouTube视频作为输入并输出一篇博客文章。这是第一页,用户可以输入YouTube链接并选择哪个模型来撰写博客文章:
让我们用我以前关于如何在Cloud Run中使用临时文件的视频试试看:
我粘贴了该视频的YouTube URL,选择了想要使用的模型,然后点击了“生成”按钮。应用程序调用了Gemini API,34秒后显示了一篇带有自定义标题图片的博客文章。以下是它的开头部分:

非常好!我认为我可以迅速调整这篇博客文章,使其足够好以发布。
1、代码原理
那么这段代码看起来是什么样的呢?我鼓励你查看GitHub仓库中的完整源代码。但目前,让我们回顾一下顶层的应用程序逻辑:
youtube_link = request.form['youtube_link']
model = request.form['model']
blog_post_text = generate_blog_post_text(youtube_link, model)
title = extract_title_from_markdown(blog_post_text)
image_data = generate_image(title)
return render_template(
'blog-post.html',
title=title,
blog_post_html=markdown.markdown(blog_post_text),
image_data=image_data
)
这就是它所做的:
- 前两行提取了用户输入的YouTube链接和模型。
- 然后代码调用 generate_blog_post_text() 并返回Markdown格式的博客文章文本。
- 代码调用 extract_title_from_markdown() 来获取博客文章的标题。
- 它调用 generate_image() 根据博客文章标题生成图像。
- 它将博客文章文本和图像插入到 blog-post.html 模板中,并将生成的HTML返回给用户的浏览器。
换句话说,很多神奇的功能都发生在 generate_blog_post_text() 中!让我们看看它!
def generate_blog_post_text(youtube_link, model):
contents = [
types.Part.from_uri(file_uri=youtube_link, mime_type="video/*"),
types.Part.from_text(text=prompts.get_blog_gen_prompt())
]
return client.models.generate_content(
model = model,
contents = contents
).text
如你所见,该函数将一个包含两个部分的内容对象组装起来:YouTube视频和文本提示(我们稍后会讨论提示)。然后它调用Google的Gen AI库中的 generate_content(),就完成了!
这并不局限于一种视频来源。这段代码使用的是YouTube URL,但你的应用程序也可以轻松地通过上传本地MP4文件或指向云存储桶中的视频文件来工作。过程是相同的,结果是根据你的指令生成的丰富文本输出。
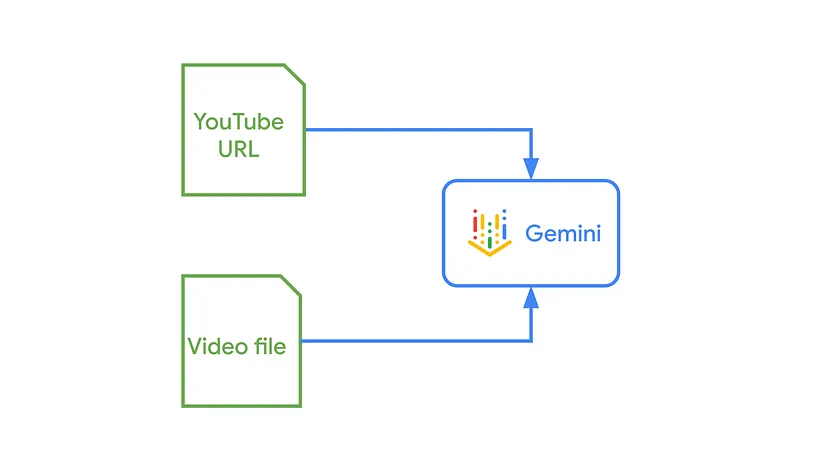
这段看似简单的代码标志着软件开发的新方法。它取代了几年前我们可能编写的代码,比如提取字幕、发送音频、将字幕转录为音频以及总结字幕的代码。所有这些旧的、脆弱的流水线代码已被……实际上被一个提示所取代。
2、你的提示就是流水线
因此,如果API调用简单而优雅,你如何控制得到什么?这是主要技巧:你业务逻辑的很大一部分只是移动到了提示中。你不再编写流水线,而是只是设计用普通英语书写的提示。
但没有人第一次就能得到一个复杂的提示。一个好的建议是首先让AI本身为你的任务生成第一个提示。从那里开始,就需要迭代。你可能需要通过添加背景上下文、定义特定的角色(比如“一位友好且专业的技术作家”)以及添加清晰的布局规则来完善语气和结构。Markdown对于保持信息组织很有用,既对我们人类作家有用,也对AI读取提示时有用。
经过一些试错之后,我最终得到了这个提示:
你是一位专门从事开发者倡导内容的专家技术作家。
根据视频创建一篇引人入胜的博客文章。
只返回博客文章,不要解释或其他对话式响应。
用适当的层次结构将博客文章格式化为Markdown。
结构与流程:
- 以吸引读者的钩子开头。
- 一个吸引人的介绍,抓住读者。
- 结构良好的部分,有清晰的标题。
- 在各部分之间使用平滑的过渡。
- 逐步建立论点。
- 使用适合中级开发者的口语化但信息丰富的语气。
- 以可操作的见解或发人深省的结论结束。
- 不要直接引用视频。这篇博客文章应独立存在。
写作风格:
- 用清晰、吸引人的散文写作,避免过多的项目符号。
- 用段落充分发展想法。
- 包含来自视频的相关统计数据、示例或案例研究。
- 保持权威但易于理解的语气。
- 变化句子结构以提高可读性。
格式:
- 使用 ## 作为主要部分(最多3–5个部分)。
- 仅在必要时使用 ### 作为子部分。
- 自然地在句子中加粗关键概念。
- 使用引文框突出重要引语或见解。
- 仅限于必要的信息列表。
这种方法非常灵活。由于逻辑只是文本,比代码更容易和安全地修改。例如,你可以将提示从“写一篇博客文章”换成“写一个三句的社交媒体帖子”,甚至“生成一个10题测验”。这是一种处理不同输出的巧妙方式。为了额外的灵活性,你可以将提示从代码中提取出来,放入文本文件或数据库中。
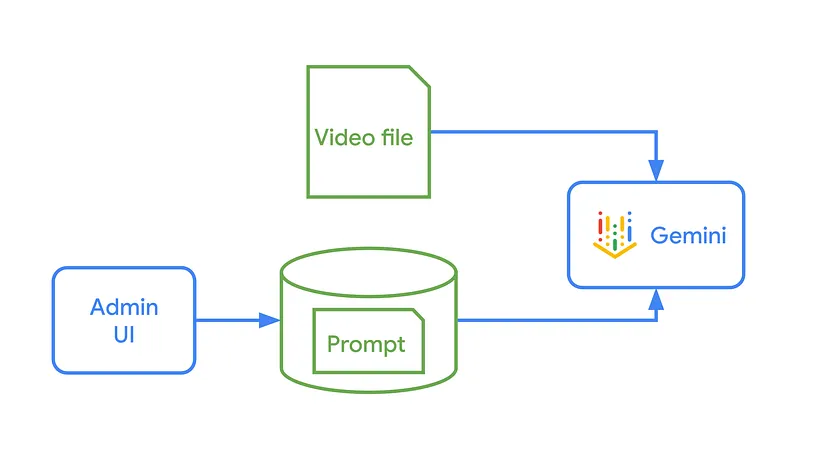
但该应用程序不仅仅生成文本。我们还可以通过添加其他元素来增强输出,例如自定义的标题图像。
3、如何生成标题图像
你可能希望添加额外的调用来改进结果。例如,我添加了第二个调用以生成你在博客文章截图中看到的标题图像。图像生成是在我们之前看到的主要应用逻辑的这两行代码中:
title = extract_title_from_markdown(blog_post_text)
image_data = generate_image(title)
一旦第一次调用Gemini返回完整的博客文章,代码就会提取博客文章的标题。然后将该标题(如“谦逊的文件系统:无服务器的惊喜”)输入到第二个API调用到Imagen模型以生成自定义标题图像。这是AI应用程序中的常见模式:一个AI操作的输出成为另一个AI操作的输入。
生成标题图像的代码如下:
def generate_image(blog_title):
prompt = prompts.get_image_gen_prompt(blog_title)
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt=prompt,
config=types.GenerateImagesConfig(
number_of_images=1,
output_mime_type='image/png',
),
)
image_data = response.generated_images[0].image.image_bytes
encoded_image = base64.b64encode(image_data).decode('utf-8')
return encoded_image
它获取图像生成提示(包括博客文章标题),调用 generate_images() 创建图像,然后将图像字节格式化为Base64,以便内联到HTML页面中。
像这样生成文本和图像可能会引发我们对实际可行性的疑问。让我们解决有关成本和性能的关键问题。
4、成本如何?让我们计算一下!
这听起来很强大。但它也很昂贵吗?毕竟,处理视频并不容易。让我们看一下数字。
根据Google的文档,每秒视频大约处理为300个标记。这意味着一分钟的视频大约是18,000个标记。截至本文撰写时,Gemini 2.5 Flash模型的价格是每百万个标记30美分。
如果你计算一下,处理一分钟的视频大约花费不到一美分的一半。
只有在使用完每日免费配额后才会产生费用。如果你的应用程序需要处理大量的视频库,你可能需要指示API以低分辨率处理视频,这会使标记成本降低三分之二。
但作为开发人员,我们也需要考虑速度。
5、快吗?让我们进行一些测量!
这个应用程序允许我们更改要处理的视频和要使用的模型,这使得基准测试变得容易。
让我们先看看三种不同的模型!我让应用程序处理如何在Cloud Run中使用临时文件的视频,该视频长度为59秒,但改变了使用的模型。我为每个模型运行了三次。以下是结果:
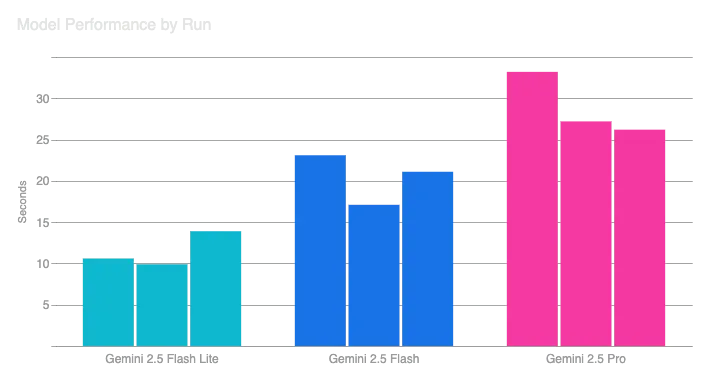
不出所料,Gemini Pro耗时更长。它比Gemini Flash或Flash Lite更大且功能更强。它旨在执行更深入和更细致的推理。Gemini Flash和Gemini Flash Lite旨在提供快速回答,例如当用户等待时。
接下来,让我们看看视频长度。我使用Gemini Flash处理了三个不同长度的视频(0:59、4:09和8:04):
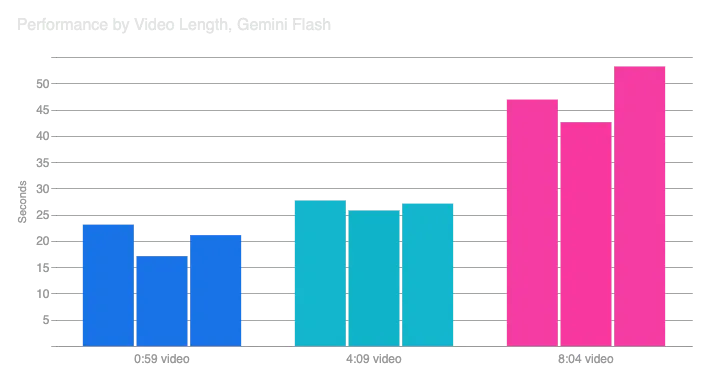
不出所料,较长的视频处理时间更长。有趣的是,四分钟的视频不像一分钟的视频那样花费太多时间,但八分钟的视频则花费更多时间。
如果你想处理一个非常长的视频呢?那将花费更长时间,可能超过用户愿意等待的时间。因此,你可能需要向Gemini发送批量请求。你的应用程序将收到请求已被接受的确认,并可以告诉用户。当处理完成后,可能几个小时后,你的应用程序将收到一个Pub/Sub消息。然后你可以通知用户,例如通过发送电子邮件。
6、应用程序的新模式
这种模式才是有趣的,而不仅仅是演示。你可以将同样的想法应用于许多常见的业务问题,例如总结录音会议以获取行动项或从屏幕捕获生成文档。
这不仅是一种不同的思维方式。它是一种范式转变。我们习惯于输入文本,输出文本,但现在我们可以将视频和音频文件扔给这些模型,并获得有用的文本、图像,甚至新的音频和视频片段。越来越多地,业务逻辑正在转移到提示中。这是一个新一波浪潮,我们作为开发人员可以驾驭并变得更擅长于用信息技术解决业务问题。
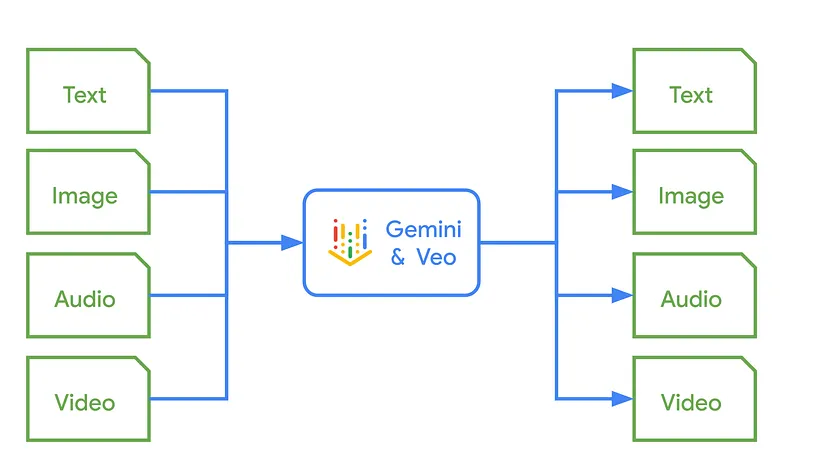
现在,轮到你探索这种转变如何改变你自己的项目并解锁新的可能性。你接下来会创造什么?
原文链接:How to build your own video-processing app with AI, and what it means for us as developers
汇智网翻译整理,转载请标明出处
