Claude Code上下文工程实战
由于我刚刚听说如果提供足够的上下文,Claude Code 非常强大,我正在寻找一个机会来测试它。

作为 AIMakerspace AI 工程训练营的一部分,我们被要求使用 LangChain 工具链(LangGraph、LangSmith 等)构建一个简单的多代理系统,以 a) 阅读研究论文 b) 撰写社交媒体帖子 c) 进行文案编辑,以确保其符合社交媒体平台的语气,例如 LinkedIn、X、Facebook。
由于我刚刚听说如果提供足够的上下文,Claude Code 非常强大,我正在寻找一个机会来测试它。
因此,这篇文章基本上就是发生的事情。你可以在这里找到仓库。
1、设置上下文
1.1 参考材料
在之前的几节课中,我们(整个班级)已经接触过以下用于使用 LangGraph 构建多代理系统的 Python 笔记本:Multi_Agent_RAG_LangGraph.ipynb 和 Introduction_to_LangGraph_for_Agents_Assignment_Version.ipynb。我知道这两个都可以作为 Claude Code 的参考。
1.2 要求
根据经验,我意识到越精确地指定我想要什么,结果越好。这是需求(你可以在仓库中找到名为 ResearchPaperSocialMediaRequirements.md 的文件):
总体要求
我们想构建一个 LangGraph 多代理系统,该系统接受 3 个参数:
- 研究论文
- 目标社交媒体 —— LinkedIn、X、Facebook
- 社交媒体帖子的整体目标
并生成一个带有 markdown 格式的文本文件的社交媒体帖子
整体设计
该系统将具有以下 LangGraph 代理:
- 一个 SEARCH_AGENT,它将输入论文的描述并使用 Arxiv 搜索工具(来自 langchain_community)搜索论文并返回该论文的文本
- 一个 SOCIAL_MEDIA_AGENT,它将输入论文的文本、目标社交媒体网络和帖子的目标,并创建一个社交媒体帖子
- 一个 COPY_EDITOR,检查 SOCIAL_MEDIA_AGENT 创建的社交媒体帖子是否符合指定社交媒体网络的语气,并对社交媒体帖子的文案进行更改
- 一个 SUPERVISOR 代理来协调其他三个代理的工作
工具
代理将需要以下工具:
- 一个 file_read 工具,读取文本文件并将文件中的行连接成一个字符串以供使用
- 一个 file_write 工具,接收一个字符串并将其写入文件
- 一个 file_edit 工具,将行插入文本文件
这些大多数都可以从这个工作区中的Multi_Agent_RAG_LangGraph.ipynb中获得一些想法
其他考虑
请包括必要的配置,通过 LangSmith 对此系统进行故障排除
2、构建
2.1 提示
使用此工作区中的两个 Python 笔记本作为参考,构建一个使用 LangGraph 的多代理系统,以从 arxiv 读取研究论文并创建社交媒体帖子。系统的规格在名为 ResearchPaperSocialMediaRequirements.md 的 markdown 文件中指定
Claude code 然后继续构建了 Python 笔记本
2.2 Facepalms
在测试驱动笔记本之前,我的 QA 蜘觉蜘蛛感 🕷开始发痒。多年自己编程和接触到开发人员忘记的东西(你知道你是谁 😃)的经验,我向 Claude 提出了以下问题:
提示
你是否包含了所需的 Python 包的“pip install”?
没有 🤦♂。Claude code 去添加了那个。
提示
你在笔记本中包含了设置 LangSmith 以进行可观测性的步骤吗?
是的 🔥 🔥。但 Claude code 承认需要在 Markdown 中添加更多关于设置 LangSmith 的说明。
然后当我开始运行笔记本时,我们遇到了另一个问题:
ModuleNotFoundError: 没有名为 'arxiv' 的模块

哦,Claude code 也能够修复这个问题。
3、结果
你可以在仓库中找到名为 research_paper_social_media_system.ipynb 的笔记本。这里是一些结果:
3.1 LinkedIn 帖子
要求
- paper_description = “QLoRA: Efficient Finetuning of Quantized LLMs”
- social_network = “LinkedIn”
- objective = “向机器学习从业者和研究人员解释 QLoRA 的好处”
生成的帖子
**解锁机器学习的未来** 🚀 机器学习领域的激动人心的进展来了!最近的论文标题为 **”QLoRA: Efficient Finetuning of Quantized LLMs”** 引入了一种对大型语言模型 (LLMs) 进行微调的突破性方法,效率惊人。 🔍 **什么是 QLoRA?** QLoRA 代表量化低秩适应,一种允许使用消费级 GPU 上的 2/3/4 位精度对多达 650 亿参数的 LLM 进行微调的方法。这一创新对面临内存限制的研究人员和从业者来说是一个游戏规则改变者。 💡 **关键优势:** 1. **内存效率:** QLoRA 与传统方法相比,显著减少了内存使用,使其对计算资源有限的人更具可访问性。 2. **性能:** 它在各种任务如文本分类、自然语言推理和指令遵循中实现了具有竞争力的结果,甚至在某些情况下优于现有方法。 3. **用户友好:** 配套库 **llmtune** 简化了量化、运行和微调 LLM 的过程,使从业者可以专注于他们的研究而不是技术障碍。 🌟 **为什么重要:** 🔗 深入阅读完整论文,探索这一创新方法的细节和影响! #MachineLearning #AI #DeepLearning #QLoRA #Quantization #Research #Innovation ============================================================
3.2 X/Twitter 帖子
要求
- paper_description = “Attention Is All You Need — Transformer architecture”
- social_network = “X”
- objective = “激发人们对 Transformers 在 AI 中革命性影响的热情”
生成的帖子
🚀✨人工智能的激动人心时刻!革命性的论文“Attention Is All You Need”引入了Transformer架构,改变了自然语言处理乃至更广泛领域! 🌍💡 Transformers 利用注意力机制并行处理数据,比传统模型更快更高效。这项创新为翻译、内容生成甚至医疗保健等突破性应用铺平了道路! 🏥📚 加入人工智能革命,探索 Transformers 如何重塑我们的世界! #AI #Transformers #MachineLearning #Innovation
3.3 Facebook 帖子
要求
- paper_description = “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity”
- social_network = “Facebook”
- objective = “核心信息:虽然 AI 很强大,但它仍然是一个工具,仍然不具备像受过数学问题解决训练的人那样解决问题和泛化的能力”
生成的帖子
🌟 **思考的幻象:通过问题复杂性的视角理解推理模型的优势和局限** 🌟 在一个 AI 日益强大的世界里,一篇题为“思考的幻象”的最新研究揭示了大型推理模型(LRMs)的优势和局限。尽管这些模型可以生成令人印象深刻的推理过程,但在问题解决和泛化方面仍显不足,尤其是在复杂场景中。 🔍 研究揭示了一种被称为“推理悬崖”的现象,即 LRMs 在超过一定复杂度阈值后性能会崩溃。这强调了一个关键点:尽管 AI 有所进步,但本质上仍是一个缺乏人类思维细微理解和问题解决能力的工具。 💡 随着我们继续探索 AI 的能力,重要的是要记住,虽然它可以以多种方式帮助我们,但它并不能取代受过数学问题解决训练的人类的专业知识和创造力。 让我们拥抱 AI 作为一种强大的工具,同时也要认识到它的局限性! 🤖✨ #AI #MachineLearning #ReasoningModels #HumanIntelligence #ProblemSolving
4、结束语
- 虽然我非常印象深刻,但正如你所看到的,在构建过程中还需要做一些“消除缺陷”的工作。此外,代理使用的提示语可能需要进一步优化以更好地适应社交媒体网络,不过,所有结构都已经在那里,并且已经连接到 LangSmith,所以可以利用它来帮助优化提示语。
- 上周,Andrew Ng 提到了他与“AI Fund”下的公司的一些学习经验(参见 视频),他表示对于 MVP 来说,一些团队只是从头开始重建。我能理解为什么。Cursor 和 Claude code 等工具显著降低了重建软件的成本。然而,软件测试是否跟上了?(看起来这是一个很好的后续文章主题)
- 一项关于 AI 对经验丰富的开源项目开发者生产力影响的研究(参见 来源)似乎表明,经验丰富的开发者(尤其是那些熟悉代码库的)使用此类 AI 工具的生产力较低。下表显示了一些可能的原因(它们都合情合理)。
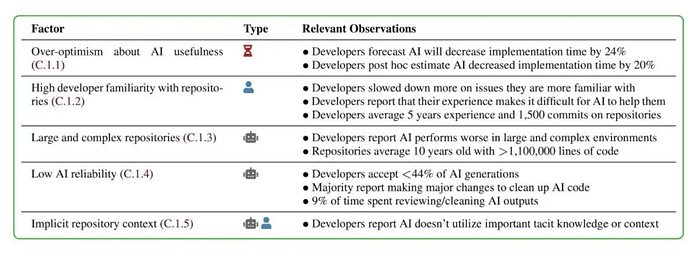
所以,我想老话还是正确的:因人而异 😆
原文链接:I context engineered a LangGraph Multi-Agent system using Claude Code
汇智网翻译整理,转载请标明出处
