数据代理:不知疲倦的数据科学家
想象一下,一位永不眠的数据科学家。他/她可以连接到您的数据库,整理杂乱的记录,执行分析,并生成清晰的报告。

最近,我不断在人工智能论文中看到“数据代理”这个词。起初,我以为这只是另一个流行词——就像“副驾驶”或“人工智能助手”一样。
但后来,我读了一篇香港科技大学和清华大学联合发表的研究论文,题为《数据代理调查:新兴范式还是过度炒作?》,它让我改变了看法。
这篇论文并非关于另一个会编写 SQL 的聊天机器人,而是关于一种全新的人工智能,它可以处理整个数据处理流程——从数据清洗和准备到分析,甚至还能向你解释数据。
他们称这些系统为“数据代理”,它们有可能彻底改变我们处理数据的方式。我们全面管理数据。
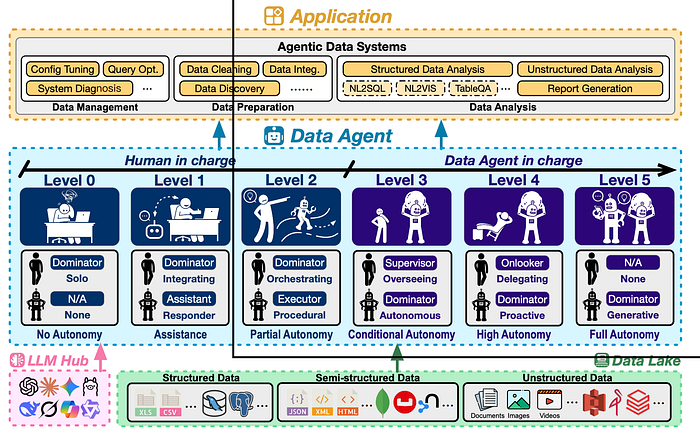
1、数据代理概述
数据代理究竟是什么?
想象一下,一位永不眠的数据科学家。他/她可以连接到您的数据库,整理杂乱的记录,执行分析,并生成清晰的报告。
现在,将这个人替换成AI。这就是数据代理。
以下是最简单的理解方式:
class DataAgent:
def __init__(self, model, data_env):
self.model = model
self.data_env = data_env
def run(self, task):
plan = self.model.plan(task)
data = self.data_env.query(plan)
result = self.model.analyze(data)
return result它就像是会动手的 ChatGPT。它不仅能回答您的问题,还能主动出击,完成工作,并返回结果。
如今,这些代理已经可以优化数据库、清理 CSV 文件或生成可视化图表。他们还很年轻,但方向很明确。
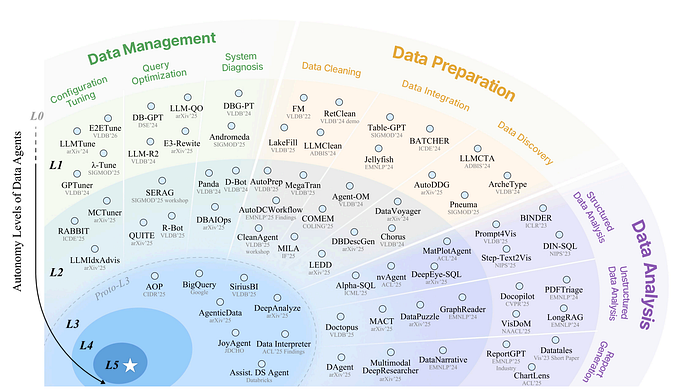
2、为什么“数据代理”这个名称并非只是营销噱头
目前,人们对这个术语的使用方式各不相同。有些人指的是可以查询数据的聊天机器人,而另一些人则指的是能够执行完整流程的自主人工智能。
这种混淆使得人们难以区分真正的进步和炒作。
该论文的研究人员试图通过开发一个六级系统来解决这个问题——类似于自动驾驶汽车从0级到5级的分类方式。
数据代理自主性的六个层级,以下是简要版本:
| 层级 | 功能 | 体验 |
|---|---|---|
| L0 | 所有操作均需手动完成 | 需要自行编写代码 |
| L1 | 基本帮助 | ChatGPT 为您编写 SQL 代码片段 |
| L2 | 部分控制 | 人工智能运行特定的数据任务 |
| L3 | 协调任务 | AI 构建并运行完整的工作流程 |
| L4 | 自主运行 | AI 在您察觉之前修复数据问题 |
| L5 | 创建新方法 | AI 成为成熟的数据科学家 |
我们目前处于 L2 或 L3 左右。AI 可以管理工作流程中的步骤,但仍然需要我们指导和检查其工作。
3、数据代理最擅长的三件事
每个数据代理,无论其级别如何,都倾向于专注于以下三个方面:
3.1 数据管理
它们优化数据库、调整配置并重写 SQL 查询以提高速度。
agent.optimize_query("SELECT * FROM sales WHERE region='Asia'")这是枯燥但至关重要的任务——无需熬夜调试即可完成。
3.2 数据准备
数据科学家的大部分工作都涉及清理杂乱的数据。数据代理可以通过检测错误、填充缺失值和合并杂乱的数据来协助这项工作。表格。
agent.clean("raw_sales.csv")
agent.merge(["sales.csv", "customers.csv"])这就像拥有一个不会抱怨电子表格的数字实习生。
3.3 分析和报告
这才是真正有趣的地方。你可以用简单的英语提问,而代理会决定如何操作。
agent.analyze("Show me the top 5 products in Q4.")它可能会生成 SQL、提取数据并构建图表——所有这些都可以在一个流程中完成。像 Alpha-SQL 和 ReportGPT 这样的系统已经接近实现这一功能。
4、重大飞跃:让 AI 掌控一切
最有趣的飞跃发生在第二级和第三级之间。那时,AI 从执行你指定的任务转变为理解需要做什么。
在第二级,你可能会说:
“清理数据,然后生成报告。”
在第三级,代理可能会举例:
“我清理了数据,但发现存在缺失值。我在生成报告之前已将其填充。”
# L2
agent.run("clean_data")
agent.run("generate_report")
# L3
agent.orchestrate("Find sales trends for Q4")这种转变——从服从的助手到独立的解决问题者——正是数据代理充满活力的原因。
5、棘手之处在于:信任和责任
一旦人工智能能够做出决策,事情就会变得复杂。如果它删除了数据,该怎么办?如果数据集错误或模式解读错误,谁该负责?是你?开发者?
这就是本文提出的六级架构如此重要的原因。它不仅具有学术意义,还能帮助我们设定预期。你可以精确地了解人工智能拥有多大的控制权,以及何时需要介入。
6、下一步:生成式数据代理
研究人员设想,未来的代理能够主动寻找任务,而不是被动等待。
想象一下:你的人工智能检测到客户参与度出现异常下降,并发出以下信息:
“嘿,你三月份的数据有点问题。我应该调查一下吗?”
这就是第四级或第五级的典型特征。一个主动的、生成式的代理,它更像是你的同事,而不仅仅是一个工具。
7、为什么这很重要
数据工作一直充满挑战。在开始分析之前,你需要花费数小时来清理、合并和验证数据。
数据代理可以减轻这种痛苦。它们不会取代人类,而是会让数据科学更容易上手。
如果大型语言模型赋予我们超乎常人的写作能力,那么数据代理或许能赋予我们超乎常人的数据直觉。
也许有一天,我们不再会问“人工智能能处理这件事吗?”,而是会问“为什么我还要自己做?”
原文链接:Data Agents: The Next AI Revolution in How We Work With Data
汇智网翻译整理,转载请标明出处
