基于深度研究的GenAI应用开发
在这篇文章中,我们将讨论如何实施和推广深度研究的设计模式。最终目标是将其专门化为您的领域用例。

“到2025年,RAG就死了。它已经被解决、重复过无数次了。它已经不再是什么新东西了。”最近我听到一位机器学习工程师这样说。确实,在2025年与客户讨论生成式人工智能用例时,我发现标准的RAG通常无法处理他们需要回答的复杂且不明确的问题。他们也无法训练用户提出足够具体的问题,以便简单的检索能够识别正确的上下文。数据源的数量和类型过于复杂,标准化变得困难。
进入深度研究。深度研究是目前最具通用性和价值的生成式人工智能应用设计模式。每个AI工程师和领域领导者都应该理解深度研究及其如何定制以满足特定领域的知识任务。不是指Gemini、ChatGPT等提供的现成的深度研究人员,而是您自己的自定义实现,解决您的特定领域知识任务。
在这篇文章中,我们将讨论如何实施和推广深度研究的设计模式。最终目标是将其专门化为您的领域用例。完整的代码库可以在GitHub上找到。
1、用于回答GCP技术问题的深度研究人员
为了有一个可以工作的示例用例,我们的目标是自动化我的大部分客户服务工程师的工作。在与客户会面后,我经常花时间撰写技术跟进邮件,提供答案以及文档和示例代码等资源。根据复杂程度的不同,这是一项相当大的时间投入,尤其是每周多次这样做时。我们将构建一个深度研究系统来自动化这些技术跟进邮件。作为工作流框架,我们将使用Firebase Genkit。
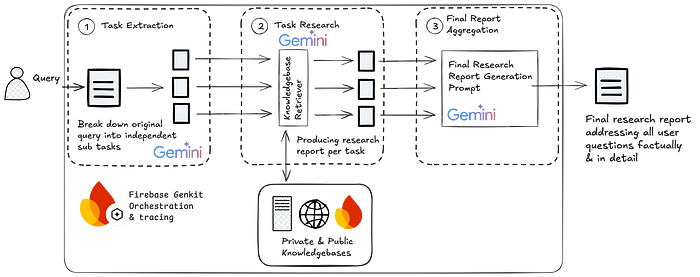
2、概念概述
深度研究模式由三个步骤组成:
- 理解并分解用户的请求
- 并行研究与检索管道以收集信息
- 聚合研究结果
让我们开始构建!
3、分解用户请求
我们的起点是会议记录。在会议结束后,我们需要提取技术问题以进行后续跟进。我们应该以易于后续处理的格式提取这些问题。
这是一个简单的文本提示就可以轻松解决的任务,使用原始会议记录作为输入。每个要提取的任务都是一个普通的字符串形式的问题。例如,一个问题可能如下所示:“我如何使用Gemini 2.5和Genkit构建自己的深度研究助手?”由于我们希望助手适用于任何会议记录,因此要提取的任务数量应该是灵活的。因此,提取提示应该输出一个包含不确定数量字符串的数组。
Genkit在TypeScript中允许我们为可调用提示定义输入和输出类型。提取提示的输入是原始会议记录,即一个简单的字符串。我们定义提取提示(任务对象数组)的输出如下:
const TaskSchema = z.object({
description: z.string(),
});
const TaskArraySchema = ai.defineSchema(
'TaskArraySchema',
z.array(TaskSchema)
);
提取提示不应过度工程化,提取问题是相对简单的任务。提示应解释任务的上下文和规则。大型语言模型必须不能编造或遗漏任何在记录中存在的问题。此外,它应简要总结问题,同时尽可能保持事实性。为此,我们将温度设置在较低的一端。使用dotprompt,Genkit使定义提示与提示配置、输入和输出模式相结合变得容易(Firebase Genkit文档)。
---
config:
temperature: 0.1
input:
schema:
transcript: string
output:
schema:
TaskArraySchema
---
<< System Instructions >>
You are an AI assistant helping extract customer's technical questions from a conversation between a Google Cloud Customer Engineer (CE) and a customer.
Analyze the transcript and identify the core technical questions, needs, or pain points the customer expresses or implies. Focus on questions that highlight the customer's technical understanding and requirements regarding Google Cloud.
** Always include topics that the CE promised to send a follow up on.
** Always focus on the specific technical questions that can be answered based on the GCP documentation.
** Only focus on questions that have NOT YET been answered in the meeting.
** DO NOT include high level business and use case questions.
<< Output Formatting >>
Format the output as a JSON array of tasks, where each task has:
description: The customer's technical question, phrased as a concise question from the customer's perspective.
<< Meeting Transcript to analyze >>
{{transcript}}
<< End of Meeting Transcript to analyze >>
<< Tasks (JSON array) >>为了协调提取步骤,我们定义了一个Genkit流程,定义了一个可调用的提示如下:
export const taskExtractionFlow = ai.defineFlow(
{
name: "taskExtractionFlow",
inputSchema: z.string(),
outputSchema: TaskArraySchema,
},
async (transcript) => {
const taskExtractionPrompt = ai.prompt('taskExtraction');
const { output } = await taskExtractionPrompt(
{
transcript: transcript,
},
{
model: gemini25ProPreview0325,
output: { schema: TaskArraySchema }
}
);
return output;
}
);
就这样,我们已经完成了任务提取。我们完成了第一步,现在可以动态地为每次过去的会议提取要研究的问题。
4、并行任务研究
接下来,我们需要研究每个问题。研究步骤的复杂度随着所需知识库的大小和类型而大大不同。我们的应用程序处理围绕GCP架构决策和技术问题,当在GCP上构建应用程序时。我们通常提供最新的GCP文档信息和GCP GitHub存储库中的示例代码。
我们选择两个知识来源来提供适当的研究背景:
首先,假设我们拥有自定义构建的知识库,将有价值的GCP文档片段转换为文本嵌入并存储在Firestore中。这可以通过Firestore向量索引功能访问。
其次,我们包括Google可编程搜索引擎API,以模拟每个研究任务的Google搜索。可编程搜索引擎API允许我们利用Google索引的最新文档,并限制搜索引擎到给定的一组网站及其子页面。这使得可编程搜索引擎API成为获取实时信息的便捷来源,而无需重新构建我们的知识库(每当文档更新时)。
任务研究的输入是我们之前创建的研究任务数组。每个任务的研究结果应按以下方式分类:
const TaskResearchResponse = ai.defineSchema(
'TaskResearchResponse',
z.object({
answer: z.string(),
caveats: z.array(z.string()),
docReferences: z.array(z.object({
title: z.string(),
url: z.string(),
relevantContent: z.string().optional(),
})),
})
);
这种严格类型化的研究报告允许我们在聚合步骤中传递重要的注意事项和相关文档引用。这种结构对于保持对哪个文档导致哪些见解的监督至关重要。它允许我们在后续电子邮件中提供文档链接和见解。
任务研究的核心是文档检索。Genkit允许通过许多预构建插件或自定义函数连接知识库。在这种情况下,我们定义了两个自定义检索器,一个用于在Firestore向量索引上运行相似性搜索,另一个用于通过可编程搜索引擎API运行搜索查询。
以下是我们的Firestore向量搜索Genkit检索器的定义。它使用向量搜索服务器端操作(ssa)。该ssa被定义为Firestore SDK的包装器(请参阅代码库中的代码)。然后将知识库中最近邻文档格式化为Genkit文档数组。
export async function createSimpleFirestoreVSRetriever(ai: Genkit) {
return ai.defineSimpleRetriever(
{
name: "simpleFirestoreVSRetriever",
configSchema: z.object({
limit: z.number().optional().default(5),
}).optional(),
// Specify how to get the main text content from the Document object
content: (doc: Document) => doc.text,
// Specify how to get metadata from the Document object
metadata: (doc: Document) => ({ ...doc.metadata }), // Include all metadata from the action
},
async (query, config) => {
const results = await vectorSearchAction(query.text, { limit: config?.limit });
const resultDocs: Document[] = results.map(doc => {
return Document.fromText(
doc.content || '', {
firestore_id: doc.documentId,
chunkId: doc.chunkId
});
});
return resultDocs;
}
);
}
自定义搜索检索器调用我们之前定义的可编程搜索引擎。搜索引擎API仅提供结果URL。因此,我们解析结果并通过提供的URL从顶部搜索结果中抓取内容。我们对原始HTML内容进行一些基本清理,并将其转换为Genkit文档以供进一步处理。您可以在仓库中找到完整代码(GitHub链接)。
接下来,我们使用Gemini 2.5填充研究问题响应模式来总结单个研究问题的答案。汇总提示是一般且简单的:
---
config:
temperature: 0.1
input:
schema:
task: string
format_instructions: string
output:
schema:
TaskResearchResponse
---
使用提供的Google Cloud文档上下文研究以下技术任务。
任务: {{task}}
提供一个响应,满足以下条件:
1. 清晰回答技术问题
2. 在相关时包括具体的步骤或配置
3. 注意重要的注意事项或最佳实践
4. 引用特定部分的文档
技术响应:
最后,我们将各个任务研究步骤合并到Genkit流程中。为了高效处理,我们将检索步骤包装成每个任务的Promise,并将研究聚合包装成异步映射。这样并行化了各个任务研究。
export const taskReseachFlow = ai.defineFlow(
{
name: "taskReseachFlow",
inputSchema: TaskArraySchema,
outputSchema: TaskResearchResponseArray,
},
async (tasks) => {
console.log("Running Task Research Flow on transcript...");
// 1. 并行检索每个任务的相关文档
const retrievalPromises = tasks.map(task => {
return ai.retrieve({
retriever: 'simpleFirestoreVSRetriever',
query: task.description, // 使用任务描述作为查询
options: { limit: 10 }
});
});
const taskDocsArray = await Promise.all(retrievalPromises);
// 2. 并行任务研究生成
const taskResearchPrompt = ai.prompt('taskResearch');
const generationPromises = tasks.map(async (task, index) => {
const docs = taskDocsArray[index];
const { output } = await taskResearchPrompt(
{
question: task.description
},
{
docs: docs,
output: { schema: TaskResearchResponse }
}
);
return output;
});
const researchResults = await Promise.all(generationPromises);
return researchResults;
}
);
我们的流程返回一个研究结果对象数组。标准化的格式使结果最容易在下一个工作流步骤中处理。
5、研究结果的聚合
我们已经取得了很大的进展!我们成功地提取了要研究的任务,并建立了一个高效的管道,可以并行高效地处理任意数量的研究任务,利用多个知识库,包括公共和私有知识库。剩下的就是聚合一份关于我们发现的报告,以一种对我们和我们的用户有用的形式呈现。我们的工作示例是撰写技术跟进邮件的挑战。使用个体研究报告的集合,让我们制定一个文本提示,使用这些报告撰写一封简洁的电子邮件草稿,提供答案和文档资源。
研究报告聚合提示将因用例而异。迄今为止我们使用的提示中,这个提示应该是最详细的,因为我们需要定义期望的输出格式、语气等。由于我们主要调整的是写作风格,多镜头提示方法在这里也很有意义。通过清晰且多样的例子,模型更容易遵循你的风格指导。
为了生成我们的技术跟进邮件,让我们使用以下提示:
---
config:
temperature: 1
input:
schema:
tasks: string
research: string
output:
schema:
email: string
---
Generate a professional follow-up email to the customer based on the technical research results.
Original Task:
{{tasks}}
Research Findings:
{{research}}
Requirements for the email:
1. Start with a brief meeting reference and summary
2. Address each technical question briefly and consicely, most bullet points should not be longer than one sentence
3. Link to specific documentation sections whenever possible, but only as it makes sense in the context
5. Maintain a professional but friendly tone
6. End with next steps or an offer for further clarification
Here is an example of the conciseness level of the email.
In your email please match the level of details provided in the example.
<< BEGINNING OF EXAMPLE EMAIL >>
See example in the full codebase
<< END OF EXAMPLE EMAIL >>
Generated Email:我们最终应该将电子邮件生成提示包装到相应的流程中(代码在仓库中)。
这就完成了深度研究管道。
此深度研究工作流的完整代码可在GitHub上找到。克隆仓库,探索实现细节,并根据您的研究密集型任务进行调整。
6、结束语
深度研究设计模式是生成式人工智能应用架构中最实用的一种。深度研究是标准RAG系统的下一代进化。我相信在未来1到2年内,许多日常知识工作者的任务将通过深度研究应用程序加速或自动化。这个项目的最初想法是为了自动化我工作中的一大块内容。这已经做得非常好了。
任何深度研究人员的实际实用性将在很大程度上取决于您可以提供访问的知识库的相关性。如果需要进一步调整结果,检索质量和任务研究报告的整理是额外的性能杠杆。最后,最终报告生成必须针对每个用例进行定制。所需输出格式将因知识任务而异。最终报告的整理至关重要,特别是在将深度研究人员暴露给终端用户时。即使您可以生成最佳和最相关的个体任务研究结果,但如果最终报告不符合用户的需求,整个深度研究人员将是无用的。
当然,我们生活在一个LLM代理的时代。我们讨论的实现遵循LLM工作流,而不是依赖代理做出决策。在大多数情况下,这将是足够的。我们可以考虑为最复杂的任务实现一个代理循环。例如,任务研究可以迭代每个任务研究报告,直到研究足够彻底。然而,代理能力往往会使架构复杂化,而使用工作流(甚至更好)可以达到相同的效果。因此,我们将代理实现留作下一篇文章的主题。
您对深度研究模式有何经验?您是否能够对其进行定制?您打算用它自动化日常工作中的哪些任务?
汇智网翻译整理,转载请标明出处
