用 NannyML 检测数据漂移
NannyML 不仅告诉我们“平均值发生了变化”,还向我们展示了数据分布何时以及如何发生变化。这通常是欺诈模式甚至客户行为正在演变的第一个信号。

在金融科技领域,打击欺诈是一场永不停歇的竞赛。欺诈者的行为瞬息万变,这给欺诈检测模型带来了巨大的挑战。上个月运行良好的模型可能会逐渐失去准确性,这并不是因为模型本身质量不佳,而是因为数据发生了变化。这个问题被称为数据漂移。
在我们的分析单元中,我们将这些变化作为反洗钱 (AML) 用例的一部分进行研究。结构化存取款是 AML 中最常见的欺诈行为之一。客户会进行多次小额交易来隐藏巨额资金。这种情况很难被发现,因为单笔交易看起来很正常,但随着时间的推移,其模式却异常。
为了帮助我们的模型保持敏锐,我们推荐使用 NannyML 进行监控。这款工具专为我们这样的情况而设计,我们拥有两个主要数据集:
- 参考数据集:用于训练模型的历史数据。
- 分析数据集:新的生产数据,包含正在进行的交易。
挑战在于,在反洗钱 (AML) 领域,标签(欺诈或非欺诈)通常会延迟到账。调查人员可能需要数周甚至数月才能确认交易是否构成欺诈。因此,我们无法始终实时衡量模型性能。
那么,我们如何才能持续监控我们的模型呢?
1、数据漂移检测
检查漂移的基本方法是比较数据集之间的简单统计数据,例如:
- 均值(平均值)
- 标准差(数据的分散程度)
- 分布形状(值的分散程度)
但这还不够。两个数据集可能具有相同的均值,但仍然有很大差异。
这就是 NannyML 更进一步的原因。它使用了众所周知的统计检验方法:
- 针对连续特征的柯尔莫哥洛夫-斯米尔诺夫检验 (KS)。该检验方法用于检查两个分布是否相同。两个分布可以具有相同的均值,但形状(方差、偏度、多模态)可能非常不同。KS 可以检测任何位置或形状的差异,而不仅仅是平均值差异。
- 针对分类特征的卡方检验 (χ²),例如交易类型(账单分拆、机票兑换、取款、现金垫款)。该检验方法用于检查类别的频率是否发生了变化。
通过这些方法,NannyML 不仅告诉我们“平均值发生了变化”,还向我们展示了数据分布何时以及如何发生变化。这通常是欺诈模式甚至客户行为正在演变的第一个信号。
数据漂移检测在反洗钱中的重要性
当发生漂移时,模型可能会开始漏掉可疑案例,或者产生更多的假阳性。对于反洗钱 (AML) 来说,这至关重要:遗漏欺诈意味着财务风险,过多的误报意味着调查人员的时间浪费。
通过使用 NannyML 监控漂移,我们可以在准确率下降之前获得预警。之后,当欺诈标签最终到达时,我们可以确认模型的实际性能。这种先进行漂移检测,再进行性能检查的组合,是领先于欺诈者的明智之举。
2、使用性能警报检测月份
NannyML 有两个实用组件可用于此目的:
- 性能计算器——计算实际得分。对于我们的案例,我们的主要性能指标是 ROC。
- CBPE(基于置信度的性能评估)——根据预测概率估算预期 ROC。
- 此步骤的结果是:找出预期 ROC 与实际 ROC 差距较大的月份。
# === Step 1: Set up the CBPE estimator ===
# CBPE estimates model accuracy from predicted probabilities
cbpe = nml.CBPE(
y_true='is_fraud',
y_pred='predicted_fraud',
y_pred_proba='predicted_fraud_proba',
metrics=['roc_auc'],
timestamp_column_name='timestamp',
problem_type= "classification_binary",
chunk_period='m' # monthly
)
cbpe.fit(reference)
# Estimate expected performance on analysis data
est_results = cbpe.estimate(analysis)
# === Step 2: Calculate realized accuracy ===
# Once labels are available, we can compute the true accuracy
perf_calc = nml.PerformanceCalculator(
y_true='is_fraud',
y_pred='predicted_fraud',
y_pred_proba= 'predicted_fraud_proba',
metrics=['roc_auc'],
timestamp_column_name='timestamp',
problem_type= "classification_binary",
chunk_period='m'
)
perf_calc.fit(reference)
calc_result = perf_calc.calculate(analysis)
# === Step 3: Visualize and analyze alerts ===
est_results.compare(calc_result).plot().show()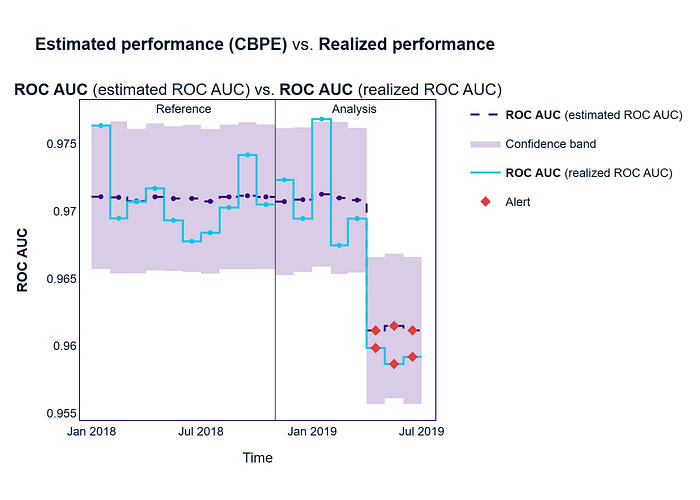
解读:
- 从 2019 年 1 月开始,实际 ROC 开始与估计 ROC 出现偏差。
- 到 2019 年 4 月至 7 月,实际 ROC 跌破预期区间,触发警报(红色菱形)。
- 该模型在生产环境中不再可靠,需要调查:漂移分析 + 可能需要重新训练。
- 根据 CBPE 的数据,该模型看起来很稳定,但实际上(一旦标签到位),其检测欺诈的能力就下降了。NannyML 通过警报发现了这个问题。这正是我们结合预期监控和实际监控的原因:检测欺诈/反洗钱系统中的静默故障。
3、哪个特征的漂移是导致性能下降的主要原因?
这时,单变量漂移分析 + CorrelationRanker 就派上用场了。
features = ["transaction_amount", "transaction_type", "user_tenure_months", "is_first_transaction"]
udc = nml.UnivariateDriftCalculator(
column_names=features,
chunk_period='m',
timestamp_column_name='timestamp',
continuous_methods=['kolmogorov_smirnov'],
categorical_methods=['chi2'],
)
udc.fit(reference)
udc_results=udc.calculate(analysis)
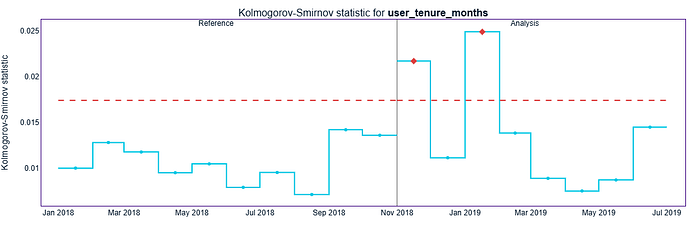
figure = udc_results.filter(column_names=udc_results.continuous_column_names, methods=['kolmogorov_smirnov']).plot(kind='drift')
figure.show()
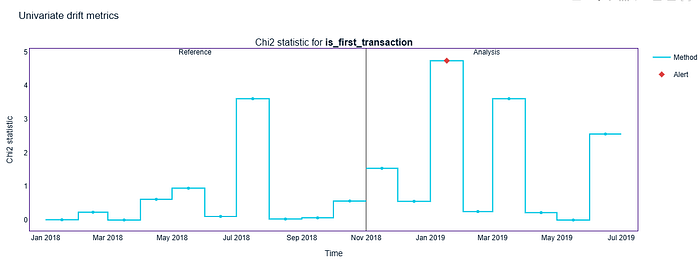
figure = udc_results.filter(column_names=udc_results.categorical_column_names, methods=['chi2']).plot(kind='drift')
figure.show()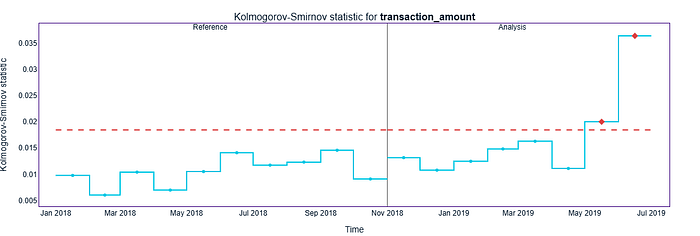
CorrelationRanker 使用皮尔逊相关系数来对每个特征的漂移与性能下降的线性相关性进行排序。
cr= nml.CorrelationRanker()
cr.fit(calc_result.filter(period='reference', metrics=['roc_auc']))
correlation_ranked_features = cr.rank(udc_results, calc_result)
display(correlation_ranked_features)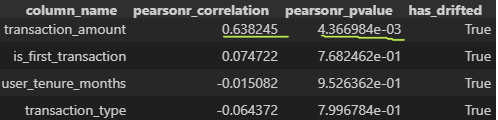
解释:在 95% 的置信水平下,特征 transaction_amount 最为重要,因为它的变化与模型性能下降明显相关。在此置信水平下,其他特征与性能之间并未显示出强烈或有意义的关系。
当我使用 KS 检验或 CorrelationRanker 等工具时,它们可以告诉我们发生了漂移。但这只能回答第一个问题:发生了变化。下一个更重要的问题是:它是如何变化的?
这时,SummaryStatsAvgCalculator 就派上用场了。它不仅提供统计警报,还能显示数字随时间的变化情况。例如,我们可以跟踪某个特征每月的平均值,如果需要,还可以查看标准差、最小值或最大值。
通过这种视图,我可以将纯粹的统计数据转化为一个更容易在商务会议上解释的故事:不仅存在漂移,而且例如“2019 年平均交易金额增长了三倍”。这使得漂移变得清晰可见且具体。
column_name = [
'transaction_amount'
]
calc = nml.SummaryStatsAvgCalculator(
column_names=column_name,
chunk_period='m',
timestamp_column_name='timestamp'
)
calc.fit(reference)
stats_avg_results = calc.calculate(analysis)
# Find the month
stats_avg_results.plot().show()
alert_avg_transaction_amount = 3069.8184
print(alert_avg_transaction_amount)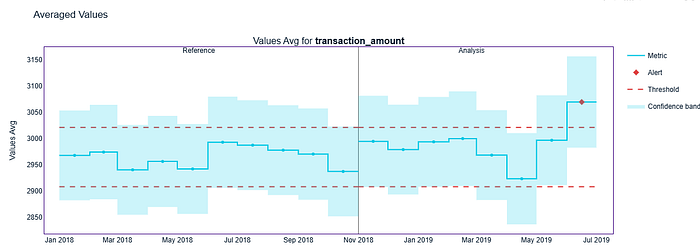
此外,我可以绘制分布的演变过程:
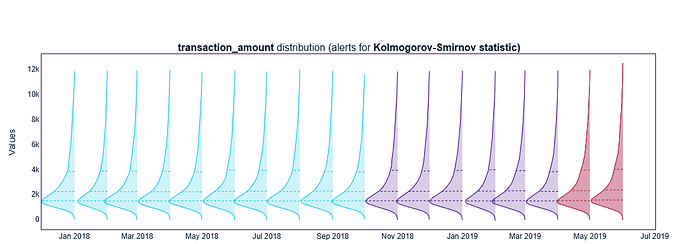
- 参考期(青色,2018 年 1 月至 9 月):分布稳定,中位数约为 2000。形状较窄,且各月之间保持一致。
- 非预警期分析(紫色,2018 年 10 月至 2019 年 4 月):数值看起来仍然接近参考期。中位数保持在 2000 左右,略有上升,但没有太大变化。在此阶段,KS 测试未发出任何警报。
- 预警期(红色,2019 年 5 月至 6 月):现在 KS 测试确实出现了标记漂移。小提琴的形状变得更粗更高(数值越高,分布越分散)。中位数明显高于前几个月(接近 4000)。
这就是 NannyML 将其标记为红色的原因——分布在统计上有所不同。
欺诈者行为变化的解读:
欺诈者并没有保持相同的模式。起初,他们试图通过进行多次小额交易来隐藏信息,保持在举报门槛以下。但后来,他们的行为发生了变化——他们不再进行多次小额交易,而是开始在单笔交易中转移更大金额。
该模型基于旧行为进行训练,因此它学会了在小范围内寻找可疑活动。当模式发生变化时,模型就无法识别新的欺诈策略。这就是其ROC下降的原因,现在需要用新数据重新训练。
原文链接:Detecting Data Drift in Anti Money Laudering with NannyML
汇智网翻译整理,转载请标明出处
