Fathom-DeepResearch
Fathom-DeepResearch 引入了一个完全开源的代理系统,在复杂、长视界的网络推理和综合任务上可以与专有DeepResearch风格的模型相媲美。

Fathom-DeepResearch 引入了一个完全开源的代理系统,在复杂、长视界的网络推理和综合任务上可以与专有DeepResearch风格的模型相媲美。
该框架结合了两个专门的40亿参数模型:
- Fathom-Search-4B,一个DeepSearch模型,能够进行超过20次连续工具调用,经过训练用于多轮、基于证据的网络推理。
- Fathom-Synthesizer-4B,一个综合模型,将多跳搜索痕迹转化为结构化、引用密集的DeepResearch报告。
关键创新包括:
- DUETQA,一个由多代理自我对弈生成的5K个实时网络搜索依赖的多跳问答对数据集。
- RAPO(奖励感知策略优化),一种稳定化的强化学习变体,可减轻多轮工具使用中的梯度崩溃。
- 可调节的步骤级奖励,使探索与验证行为之间的精细控制成为可能。
这些进步在DeepSearch和DeepResearch基准测试中实现了最先进的结果,同时保持了高效且稳定的训练
1、直觉
人类研究人员并不依赖记忆的知识——他们搜索、交叉验证并综合。
同样,Fathom-DeepResearch 教导语言模型作为自主调查员运作:
- 迭代地搜索网络,
- 评估检索到的证据,
- 将多源信息整合成连贯的报告。
这种范式将推理从“参数回忆”重新定义为交互式探索,使模型能够处理传统的LLM无法解决的开放性、基于证据的问题。
2、问题
由于以下原因,开源DeepResearch系统落后于专有系统:
- 多轮RL训练的不稳定性 —— 传统GRPO在长轨迹下会崩溃。
- 奖励黑客攻击 —— 代理重复工具调用而不改善答案。
- 有限的数据集 —— 现有的QA语料库(TriviaQA、HotpotQA)不需要实际网络检索。
- 弱综合能力 —— 大多数模型解决封闭形式的任务,但在开放性、多源推理中失败。
这些问题阻碍了开源模型执行需要持续搜索和结构化证据集成的真实世界“深度研究”。
3、解决方案
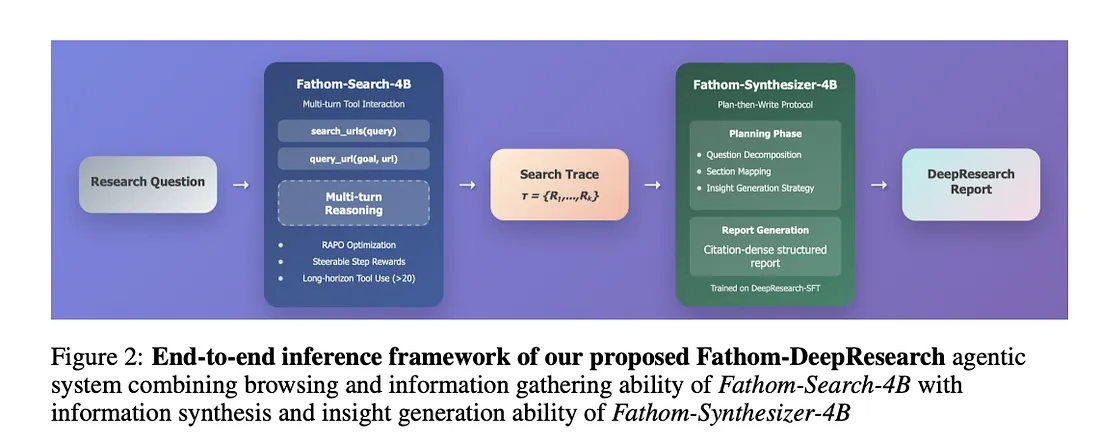
3.1 Fathom-Search-4B:长视界网络推理模型
基于Qwen3–4B构建,它使用两个工具进行实时网络搜索和结构化的查询-URL推理:
search_urls:检索排序后的URL。query_url:从页面中提取目标特定的证据。
其训练结合了
- DUETQA数据集:通过两个具有搜索功能的模型(O3、O4-mini)和非搜索验证器(GPT-4o)之间的多代理自我对弈生成。每个问题在没有搜索的情况下都是无法回答的,确保依赖于现实世界的检索
- RAPO算法:GRPO的“奖励感知”扩展,包含:
- 数据集修剪以移除已解决的提示,
- 优势缩放以保留梯度,
- 回放缓冲区以实现稳定的方差和样本效率
- 可调节的步骤级奖励:每次工具调用被标记为(UniqueSearch、RedundantSearch、Exploration、Verification)。奖励鼓励新颖、高效的搜索行为并惩罚冗余
结果:
Fathom-Search-4B超越了所有开源基线(ZeroSearch、WebSailor、II-Search),甚至能与GPT-4o-Search竞争。
在DeepSearch基准测试中,Stage-2达到:
- SimpleQA = 90.0%
- FRAMES = 64.8%
- WebWalker = 50.0%
- Seal0 = 22.5%
- MuSiQue = 33.2%。
它还推广到像GPQA-D和MedQA这样的推理任务,平均准确率为53.8%
3.2 Fathom-Synthesizer-4B:结构化综合模型
训练用于将原始DeepSearch追踪转换为引用丰富的DeepResearch报告,遵循计划然后写作协议:
- 将问题分解为子目标。
- 将检索到的证据映射到每个部分。
- 为见解综合生成分析策略
这在DeepResearch-SFT上进行训练,这是一个由GPT-5生成的2.5K样本合成数据集,强制执行:
- 部分级别的引用基础,
- 证据与部分的对齐,
- 基于见解的综合指令
训练:
- 5个epoch,bf16精度,8× H100 GPU。
- 通过YaRN RoPE缩放将上下文窗口扩展到65 K tokens,以容纳完整的多轮追踪。
4、结果
在DeepResearch-Bench上,Fathom-DeepResearch达到了RACE = 45.47 和 FACT = 56.1,与Gemini-2.5-Pro DeepResearch(48.88 / 81.44)等闭源代理相当,并在整体报告质量和事实准确性方面超过了OpenAI-DeepResearch(46.98 / 77.96)
局限性和未来机会:
- 训练效率:RAPO稳定了长视界RL,但由于同步管道,超出6K tokens时扩展性较差。
- 需要异步训练:未来的版本可能会采用异步回放以处理更大、更多样化的数据。
- 超越网络QA:扩展到多模态证据(例如PDF、图表)和现实世界领域(科学或政策分析)仍然是开放的。
- 奖励函数设计:可调节的奖励旋钮(探索与验证预算)提供了灵活性,但需要仔细调整。
5、结束语
Fathom-DeepResearch 是一个开源DeepResearch代理的蓝图 —— 结合了稳定的长视界RL、多代理数据生成和结构化综合。
它超越了短期事实QA,朝着自主、基于证据的研究系统迈进,通过透明、可重复的设计匹配闭源性能。
原文链接:Fathom-DeepResearch: Unlocking Long-Horizon Information Retrieval and Synthesis for SLMs
汇智网翻译整理,转载请标明出处
