基于文件系统的AI代理上下文工程
AI代理可以将检索结果写入文件系统,而不是使用对话历史记录来保存所有工具调用结果和笔记,并在必要时选择性地查找相关的信息。

深度代理的一个关键特性是它们对一组文件系统工具的访问。深度代理可以使用这些工具来读取、写入、编辑、列出和搜索其文件系统中的文件。
在本文中,我们将探讨我们认为文件系统对代理重要的原因。为了理解文件系统如何有帮助,我们应该从思考代理今天可能不足的地方开始。它们失败的原因要么是(a)模型不够好,要么是(b)没有访问正确的上下文。上下文工程是“将上下文窗口填满与下一步相关的正确信息的微妙艺术和科学”。理解上下文工程——以及它如何失败——对于构建可靠的代理至关重要。
1、上下文工程的观点
一种看待现代代理工程师工作的角度是通过上下文工程的视角。代理通常拥有大量的上下文(所有支持文档、所有代码文件等)。为了回答一个即将到来的问题,代理需要一些重要的上下文(包含回答问题所需的信息)。在试图回答这个问题时,代理检索一些上下文体(将其拉入它的上下文窗口)。
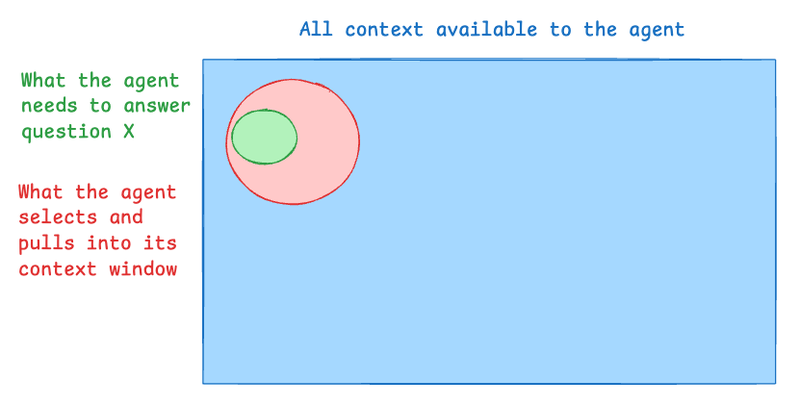
从这个角度来看,代理的上下文工程可能会以许多方式“失败”:
- 如果代理所需的上下文不在总上下文中,代理就无法成功。例如:客服代理需要访问某个文档页面来回答一个问题,但该页面尚未被索引。
- 如果代理检索到的上下文不能涵盖代理所需的上下文,那么代理将无法正确回答。例如:客服代理需要访问某个文档页面来回答一个问题,该页面存在且已被索引,但未被代理检索到。
- 如果代理检索到的上下文比代理所需的上下文大得多,那么代理就会浪费时间或令牌(或两者)。例如:客服代理只需要一个特定的页面,而代理却检索了100个页面。
作为代理工程师,我们的工作是让红色匹配绿色(确保代理检索到的上下文尽可能小地包含所需信息)
当寻求隔离适当上下文时会出现一些具体的挑战
- 太多令牌(检索到的上下文 >> 必要的上下文)
一些工具,如网络搜索,可以返回大量令牌。几次网络搜索很快就能在你的对话历史中累积成千上万的令牌。你最终可能会遇到一个烦人的400错误请求,但在那之前,你的LLM账单会迅速膨胀,性能也会下降。 - 需要大量上下文(必要上下文 > 支持的上下文窗口)
有时代理可能确实需要很多信息才能回答一个问题。这种信息通常无法在一个搜索查询中返回,这就是为什么许多人转向了“代理搜索”的想法——让代理反复调用搜索工具。问题是,上下文的数量很快增长到无法全部放入其上下文窗口的程度。 - 寻找特定信息(检索到的上下文 ≠ 必要的上下文)
代理可能需要引用数百或数千个文件中埋藏的特定信息来处理输入。代理如何可靠地找到这些信息?如果无法做到,那么检索到的上下文就不会是回答问题所需要的。有没有替代方法(或补充方法)来代替语义搜索? - 随时间学习(总上下文 ≠ 必要的上下文)
有时代理可能只是没有访问回答问题所需上下文的权限(无论是在它拥有的工具还是指令中)。终端用户可能经常在与代理的互动中提供暗示性或明确的线索,表明该上下文可能是什么。有没有办法让代理将这些信息添加到其上下文中以供以后迭代使用?
这些都是常见的障碍,我们大多数人都以前经历过不同类型的这些问题!
2、文件系统如何使代理更好?
简单来说:文件系统提供了一种单一接口,代理可以通过它灵活地存储、检索和更新无限量的上下文。
让我们看看这如何帮助上述每个场景。
2.1 太多令牌(检索到的上下文 >> 必要的上下文)
代理可以将这些结果写入文件系统,而不是使用对话历史记录来保存所有工具调用结果和笔记,并在必要时选择性地查找相关的信息。Manus是最早公开讨论这种方法的人之一他们的博客文章中提到了这一点。下面的图表来自他们的博客文章。
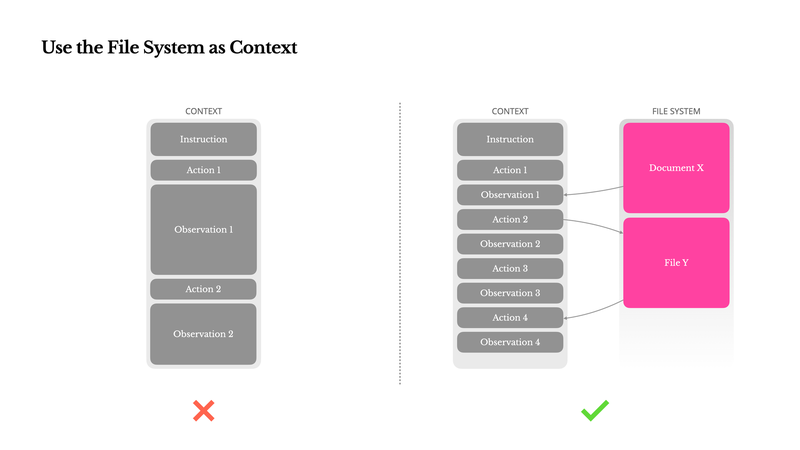
让我们以网络搜索工具的第一个例子为例。我运行了一个网络搜索,得到10k个令牌的原始内容。其中大部分内容可能并不总是必要的。如果我把这些内容放在我的消息历史中,整个对话过程中都会保留这10k个令牌,导致我的Anthropic账单上涨。但如果我把这个大的工具结果转移到文件系统,代理就可以智能地grep搜索某些关键词,然后只将必要的上下文读入我的对话中。
在这个例子中,代理实际上将文件系统用作一个大型上下文的临时纸巾。
2.2 需要大量上下文(必要上下文 < 支持的上下文窗口)
有时代理需要大量上下文来回答问题。文件系统为LLM提供了一个很好的抽象,允许它们按需动态存储和提取更多信息。这些包括:
- 对于长期答案,代理需要制定计划并遵循它。通过将计划写入文件系统,代理可以在以后将此信息重新拉入上下文窗口,提醒代理它应该做什么(例如 “通过重述操纵注意力”)
- 为了浏览所有这些上下文,代理可能会启动子代理。当这些子代理工作并学习东西时,它们不仅向主代理回复它们的学习成果,还可以将知识写入文件系统(例如 “最小化电话游戏”)
- 一些代理需要很多关于如何做事情的说明。与其将所有这些说明都放入系统提示中(从而增加上下文),你可以将它们存储为文件,并让代理按需动态读取它们(例如 Anthropic技能)。
2.3 寻找特定信息(检索到的上下文 ≠ 必要的上下文)
语义搜索是早期LLM浪潮中检索上下文最流行的方法之一。在某些用例中它可以有效,但由于文本中缺乏语义信息,根据文档类型(例如技术API参考、代码文件),语义搜索可能非常不适用。
文件系统提供了一种替代方法,允许代理使用ls、glob和grep工具智能地搜索上下文。如果你最近使用过Claude Code,你会知道它严重依赖glob和grep搜索来找到它需要的正确上下文。这种技术成功的几个关键点如下。
出于这些原因,在某些情况下使用文件系统(以及使用文件系统获得的搜索能力)可以产生更好的结果。
请注意,语义搜索仍然有用!并且可以与文件系统搜索一起使用。Cursor最近写了一篇博客,强调同时使用两者的优点。
2.4 随着时间学习(总上下文 ≠ 必要的上下文)
代理出错的一个主要原因是缺少相关上下文。提高代理的一个好方法通常是确保它们能够访问正确的上下文。有时这可能看起来像添加更多的数据源或更新系统提示。
更新系统提示的一种常见做法是:
- 看到一个代理缺乏适当指令的例子
- 从主题专家那里获取相关指令
- 用这些指令更新提示
通常,最终用户实际上是最佳的主题专家。通过与代理的对话,他们可能会提供有关正确相关指令的重要线索(隐含或显式)。因此,考虑到这一点——有没有办法自动化第三步(用这些指令更新提示)?
我们认为代理的指令(或技能)与其他它们可能想要处理的上下文没有区别。文件系统可以作为代理存储和更新自己指令的地方!
在用户反馈之后,代理可以立即写入自己的文件并记住一个重要信息。这对于快速的一次性事实非常有用,特别是那些可能因用户而异的东西,比如他们的名字、电子邮件或其他偏好。
这还没有完全解决,仍然是一个新兴模式,但它是一个令人兴奋的新方式,让LLM可以随着时间的推移增长自己的技能集和指令,确保未来的迭代中能够访问必要的上下文。
3、看看深度代理如何利用其文件系统
我们有一个开源仓库叫做Deep Agents (Python, TypeScript),它让你可以快速构建一个具有文件系统访问权限的代理。许多使用文件系统的上下文工程技巧已经内置!肯定还有更多模式会出现——试试Deep Agents并告诉我们你的想法吧!
原文链接:How agents can use filesystems for context engineering
汇智网翻译整理,转载请标明出处
