大模型微调是浪费时间
人们认为可以通过微调注入知识。他们错了。

最近,我与一位投资者进行了通话,他希望我能帮助他对一家初创公司进行尽职调查。在我们的谈话中,他们随意提到这家初创公司将依赖微调来确保其系统始终更新新信息。我很惊讶地看到微调的神话依然存在,但我猜微调和GOAT-naldo一样,一直在喝着那杯永生之汁。
微调大型语言模型(LLMs)经常被宣传为一种快速、强大的方法来注入新知识。表面上看,这很有道理:向已经强大的模型输入新数据,调整其权重,从而提高针对特定任务的表现。
但对于高级模型来说,这种逻辑完全崩溃了,而且非常严重。在高性能时,微调不仅仅是添加新数据——它是在覆盖现有知识。每个被更新的神经元都有可能失去已经深深嵌入网络中的宝贵信息。简而言之:神经元是宝贵的、有限的资源。更新它们不是无代价的行为;这是一种危险的权衡,威胁到高级模型精妙生态系统的平衡。
在今天的文章中,我们将讨论为什么对LLMs进行微调在知识注入方面是一个巨大的时间浪费(占大多数人所想的90%)。

概要
对高级LLMs进行微调并不是知识注入——而是破坏性的覆盖。训练好的语言模型中的神经元不再是空白的,而是高度互联并编码了重要的、微妙的信息。当你进行微调时,你可能会擦除有价值的现有模式,导致意想不到且有问题的下游影响。
相反,使用模块化方法如检索增强生成、适配器或提示工程——这些技术可以在不损害底层模型精心构建的生态系统的情况下注入新信息。


1、LLMs作为信息生态系统
为了理解为什么对高级语言模型进行微调不像听起来那么简单,让我们首先考虑神经网络,特别是语言模型是如何从头开始训练的。
本质上,神经网络是由无数相互连接的神经元组成的巨大集合,每个神经元都持有数值(权重),这些数值决定了它们的行为。起初,这些权重是随机设置的——没有编码意义,也没有存储知识,只是数学上的噪声。
当训练开始时,网络接收输入(单词、句子、文档),做出预测(下一个单词、句子完成),然后计算这些预测与现实之间的差异。这种差异被称为损失。网络随后使用一种称为反向传播的过程逐步调整每个神经元的权重,减少这种损失。在训练初期,这很容易——神经元存储的是基本随机的值,因此更新它们造成的有用信息损失最小。整个过程如下图所示:
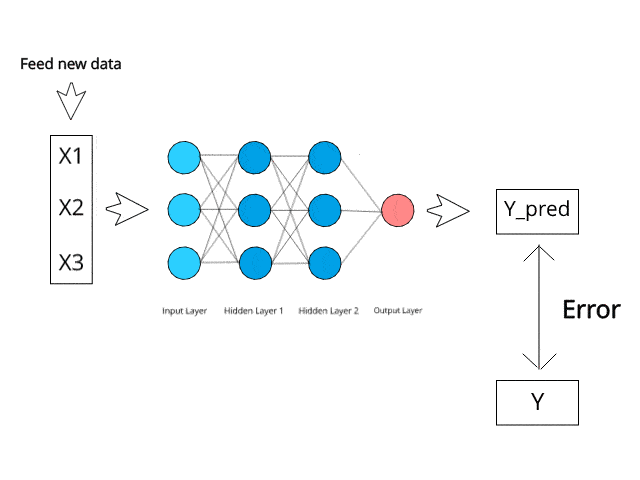
随着更多的训练,网络逐渐编码有意义的模式:语言细微差别、句法规则、语义关系以及上下文相关的含义。神经元从背景角色A进化成重要配角如Kirishima,有些甚至达到了Kacchan的地位。
在训练有素的LLMs中更新神经元的成本会上升,因为神经元包含了重要的信息。
在现代LLMs的水平上(这是大多数傻瓜尝试调整的东西),大多数神经元都密集地装满了关键见解。对其进行微调/运行任何更新更有可能会击中一些重要的神经元,完全改变你的预期行为。
你可以在安全研究中看到这一点。正如我们之前看到的,对齐改变了输出中的偏见分布,产生了新的、意想不到的偏见,与基线模型相比显著不同。举个例子:
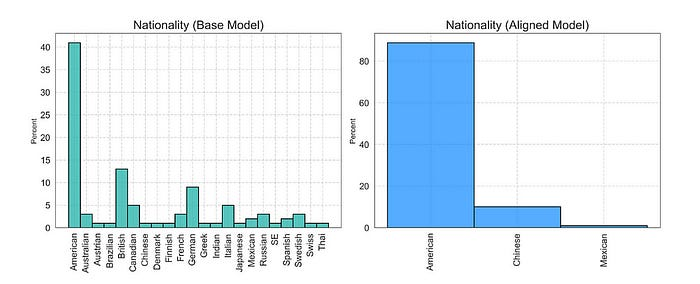
“基础模型生成了广泛的国籍,其中美国、英国和德国是最常见的。相比之下,对齐后的模型只生成三种国籍:美国(占比最高)、中国和少量的墨西哥。” 基础模型可能有一些有趣但对对齐来说不安全的德国和英国训练数据。想知道是什么吗?
鉴于我从未见过喜欢英国人的,有人可能会说对齐删除他们是正确的(因为它也删除了法国人,我认为我们已经实现了通用人工智能),但多样性的大幅减少以及数据点排名的变化都是出乎意料的。最戏剧性的例子在这里展示:“最后,客户性别的分布(图6)显示,基础模型生成大约80%的男性客户和20%的女性客户,而对齐后的模型几乎生成100%的女性客户,只有极少数男性。”
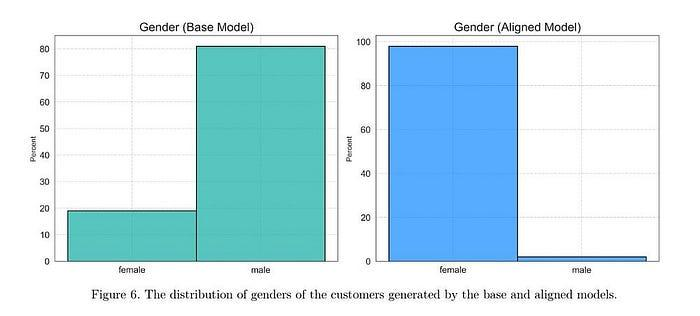
所有这些都是为了向你展示对齐带来了各种各样的影响,我们还没有深入探讨这些影响,这种无知使得红队测试变得更加困难(无法打击你不了解的目标)。
重点在于:神经元不再是中立的——每次更新都可能覆盖现有的、有价值的信息,导致网络中出现意想不到的后果。一个神经元可能在多个任务中都很重要,因此更新它会导致意想不到的下游影响。

引用我们的一位最优秀的宝石之一的话,“为安全生成进行微调就像曼联——既昂贵又几乎从未产生结果,但不知为何仍然被视为合法的竞争者,主要归功于一小群(妄想的)支持者。多年来,人们一直在谈论微调将解决所有问题——从幻觉到对齐中的不安全生成。”
理解这一点对于认识到微调高级语言模型的隐性成本至关重要。除非你投资了大量的AWS资金,并且希望确保他们的股票上涨,否则你最好把时间花在更有意义的事情上。
2、前进的道路:模块化的知识插入
如果微调是一种风险解决方案,那么替代方案是什么?答案在于模块化和增强。像检索增强生成(RAG)、外部记忆库和适配器模块这样的技术提供了更可靠的方法来整合新信息,而不会覆盖现有网络的知识库。
- 检索增强生成(RAG) 使用外部数据库在推理时动态增强知识。很多人愚蠢地宣称RAG已死(我们最终会讨论这个问题),但在处理大型知识库进行问答时,这仍然是最可靠的技术。对于更复杂的知识工作,你可能会发现朴素的RAG不足,但可以实施更先进的检索和表示技术以实现更强的性能(例如,我们在Iqidis中使用知识图谱和基于实体的分块,结合普通分块——这允许我们的AI从更大的知识库中提取上下文)

- 适配器模块 和 LoRA(低秩适应)通过专门的、隔离的子网络插入新知识,而不触碰现有的神经元。这对于格式化、特定链等内容来说是最好的——这些都不需要完整的神经网络更新。
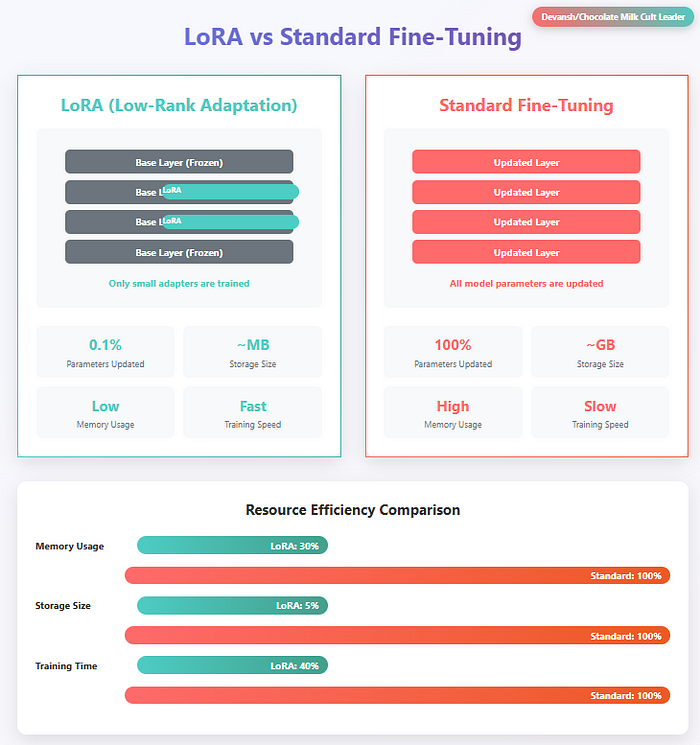
LoRA与全量微调对比LLMs。LoRA更便宜、更快,并且通常在特定场景下匹配性能,而不会造成破坏性干扰。
- 上下文提示 利用预存模型的能力,而无需对神经元进行永久修改。
好的提示将LLM引导到更有可能产生好答案的区域。这是一种技能,而不是运气,即使LLMs是非确定性的。
这些技术认识到神经元的真实本质:有限的、宝贵的、密集打包的资源,在可能的情况下最好保持完整。还有许多其他技术,我们将在人工智能简化中深入讨论,但这些三种技术是大多数团队在不需要大量AI专业知识的情况下就能开始使用的(现在有很多框架和服务用于LoRA之类的东西,虽然LoRA非常复杂,但RAG的基本设置/调优现在非常容易实现)。
3、结束语
微调不是知识注入——它是知识覆盖。对于高级LLMs来说,神经元不再是中立的占位符;它们是高度专业化、密集互联的宝贵信息仓库。草率地更新它们可能会造成灾难性的、无形的损害。
如果你的目标是构建灵活、可扩展且稳健的系统,对待微调应给予应有的谨慎。拥抱模块化解决方案(软件原则不会因为我们在做AI就消失)以保持网络基础知识的完整性。否则,你只是在一点一点地拆解你精心构建的知识生态系统。
原文链接:Fine-Tuning LLMs is a Huge Waste of Time
汇智网翻译整理,转载请标明出处
