让LLM学会你的说话风格
使用你自己的社交网络评论来微调一个LLM,并在(相对)廉价的硬件上运行所有微调。

最大的、最好的LLMs使用大量的硬件资源来进行推理。即使是一个大型模型的一个实例,也需要普通用户通常无法访问的硬件,除非他们花费大量资金在云基础设施上。而训练这些模型所需的资源甚至比推理更多。
最大的LLMs可以通过蒸馏和量化进行压缩——这些较小版本可以在消费级硬件上运行,比如一台游戏PC。但是训练或甚至只是微调其中一个缩小版模型仍然需要非常显著的硬件资源——至少,如果你计划以全精度进行微调的话。
然而,如果你放弃对全精度的需求,全精度微调,那么这个过程就可以在你可能已经拥有的硬件上完成,比如一台好的游戏PC。让我们看看我们如何实现这一点。
1、为什么微调?
为什么你要做这一切,而不是仅仅使用现成的模型?毕竟,LLM的回答方式和它在答案中放入的信息可以通过调整系统提示来改变。你可以调整系统提示,这将在一定程度上改变模型的行为。你可以使用RAG(检索增强生成),将LLM连接到外部知识库并扩展其知识。
但这些技术有其局限性。系统提示只能改变模型的行为到一定程度。一些模型(特别是Gemma 3)甚至没有经过系统提示的训练(在这种情况下,你可以将你的“系统”提示作为第一个用户提示的前缀)。RAG可能会增加额外的延迟,这在某些情况下可能不是理想的。
如果这些因素成为限制,你可能不得不考虑微调,这(简单地说)是对模型进行一些额外的训练,使用你自己的数据集。通过微调,你的LLM将开始以更符合你数据集的方式回答问题,并学习只有你的数据集才具有的事实。
请记住,微调本身并不是一种通用解决方案。它可以极大地改变答案的风格和格式,这是它的主要优势。但在知识方面,一个小或中等大小的LLM在其权重中的存储空间是有限的,所以不要期望像这样把一卡车的百科全书塞进你的LLM里。RAG可能仍然有助于扩展模型的知识。当然,你可以随时混合使用不同的技术。最后,这里描述的微调过程不适合用于推理模型。
2、哪些模型?
不要指望能够在一台游戏PC上微调一个拥有数百亿权重的大尺寸LLM,即使使用这些技术。但一个拥有数十亿权重的模型应该是可行的。我们将要查看的例子是Google的Gemma 3 27B和Meta的Llama 3.1 8B。这就是在消费级硬件上可以做到的范围。
3、需要什么硬件?
如果你有一台不错的游戏PC,你已经有一个很好的开始了。但微调是在GPU上进行的,主要的限制因素是GPU的VRAM量。简单地说,VRAM越多越好。尽量购买你能负担得起的最大GPU。 计算能力很重要,但内存更重要(在大小和带宽方面)。
我在RTX 3090上完成了所有工作,这是我多媒体/娱乐/游戏/机器学习PC上的显卡。这款GPU有24GB的VRAM和接近936GB/s的带宽,这足以用这些技术微调一个27B模型(但不足以进行全精度微调)。你可以选择RTX 4090,但它只增加了少量的计算能力,内存数量相同。如果你能买得起RTX 5090,那会将VRAM提升到32GB,这是一个显著的提升。
我的系统RAM是64GB,这还可以。我希望能翻倍——这会提高磁盘缓存的速度,从而更快地加载.safetensors文件。你肯定想要一个SSD作为主驱动器,但保留一个非常大、非常慢、非常便宜的HDD来存放模型文件是可以的(我的数据存储HDD是7TB)。根据需要在SSD和HDD之间移动文件。如果CPU在现代游戏中表现良好,那么它很可能也适合微调。
在云端,你可以租用更大更快的计算资源。上面提到的数字是为了给你一个性能开始变得可接受的地方的概念。
4、技术和库
我们将快速浏览这一部分,因为主题很广泛,而这是一个实用的HOWTO文档。
简单来说,我们谈论的是PEFT技术:参数高效微调。全精度微调涉及调整模型的所有权重。PEFT冻结大多数权重,只调整其中的一些,或者冻结所有权重并引入可以调整的辅助权重。实际上只调整了一小部分权重,大约0.2到0.5%。这就像微调一个更小的模型,这就是这个项目可行的诀窍。
Hugging Face托管了流行的PEFT库,该库有良好的文档。
LoRA(低秩适应)是PEFT的一种特定类型,在这种情况下,模型权重被冻结,添加低秩权重矩阵,并且只调整这些矩阵。QLoRA(量化LoRA)类似,但不是使用常规精度权重(例如16位),而是将权重量化为更小的尺寸(例如4位),然后以此方式进行微调。
当然,这些技术引入了一些性能损失,但远低于你预期的那样。结果模型仍然非常可用。在大多数情况下,你很难区分它们与全精度模型。
你可以直接使用PEFT库。但那时你必须弄清楚整个过程,提供正确的基础模型(或将基础模型处理成满足要求的形式),并找出所有尽可能减少VRAM使用的设置。PEFT并不难。在高度受限的计算资源上进行PEFT是困难的。
Unsloth库为上述所有内容提供了捷径。它们在默认设置中封装了PEFT,这些设置经过高度优化,可以在消费级GPU上运行该过程。它们甚至提供启动基础模型。
如果你正在为生产环境微调模型,你最好租用云计算资源并使用纯PEFT。如果你在家里的PC上运行这个过程,先试试Unsloth。
5、数据集
如果你有任何机器学习经验,这应该就是你所期望的:你需要一个数据集才能让这一切发挥作用,而且数据集越大越好(至少几千个,甚至几万个数据点)。LLMs通常以问答格式使用(提示和输出),因此数据集必须模仿这种格式,如果你想要这样做的话。由于我们只想测试QLoRA技术的可行性,任何数据集都可以,只要它符合这个描述。
如果你在社交网络上使用的时间够长,你可能已经有了这个数据集。社交网络通常会在请求后立即向你提供你自己的数据。我使用了自己的Reddit评论作为数据集的答案部分。Reddit会迅速免费提供你自己的数据,如果你在这里提出请求。
我只需要提示部分来配对答案。这很简单:每个评论都有一个父实体:即我的评论所回复的评论或帖子。PRAW库专门用于与Reddit API交互,你可以用它来收集所有父评论和帖子。你需要在Reddit上创建一个开发者应用才能使用PRAW库,你可以在这里创建(请查阅PRAW文档获取更多信息)。
这篇文章是我在GitHub仓库中的配套文章,我在那里存储了该项目的所有代码(见链接结尾)。检查仓库以获取下载父实体的Python脚本。如果评论数量很大,脚本可能需要运行一天或两天。生成一个CSV文件,其中包含两个主要列:parent_text和comment_body。前者包含父实体,后者包含我作为回复写下的评论。
+---------------+-------------------------+
| parent_text | comment_body |
+---------------+-------------------------+
| Is water wet? | Of course it is. |
| How are you? | I'm good, thanks! |
| Name a color. | Blue. Or green. Or red. |
+---------------+-------------------------+
Parent_text将提供微调提示,而comment_body将提供模型将被调整以遵循的微调答案。我的脚本保留了所有的Markdown格式,因此模型也可以学习这些。
我使用这个特定数据集的另一个原因是,我亲自测试了所有模型,并且我对这个数据集非常熟悉。如果模型开始产生幻觉,我很容易捕捉到即使是小的偏差——因为显然,这听起来不像我会说的话。我可能会在未来探索其他微调技术,但这个数据集会一直存在,保存在我的非常大、非常慢、非常便宜的数据缓存HDD上。
最后,数据集的规模刚刚好,大约有40k个数据点(评论)。这是从20年的社交媒体发布中积累的,不要评判我。
再次强调,这里的结果是偶然的。我并没有打算为自己创造一个社交媒体数字鹦鹉。我所做的只是想看看,是否可以用非常有限的资源微调一个LLM而不严重降低其性能。
答案是:可以。
6、使用Unsloth进行QLoRA 4位微调
检查我的仓库(见链接结尾)以获取两个训练笔记本,一个是针对Llama的,另一个是针对Gemma的。我们将讨论Gemma笔记本。
你必须在导入PyTorch之前导入Unsloth。这将启用优化,使微调运行得更快。
from unsloth import FastModel, to_sharegpt
from unsloth.chat_templates import get_chat_template, standardize_data_formats, train_on_responses_only
from datasets import load_dataset
from transformers import TextStreamer
from trl import SFTTrainer, SFTConfig
import torch
import os
import json
然后笔记本从Hugging Face上的Unsloth集合加载了一个4位量化版本的Gemma 3 27B。你必须将其加载为基础模型,或者类似于它的东西,因为你正在以4位模式进行QLoRA。
如果你更改基础模型的名称,并尝试从HF上的Google集合加载Gemma,Unsloth会默默地覆盖你的选择,并仍然加载它想要的模型。如果你不知道太多关于模型训练和PEFT的知识,这很好。但如果试图达到特定结果,这可能会令人沮丧。取消注释use_exact_model_name=True以禁用名称覆盖,但只有当你完全理解整个过程时才这样做——如果你不这样做,就会学到这些教训。
简而言之:无论你喜欢与否,Unsloth都会在你的自行车上装上训练轮。但然后自行车只能在非常窄的路上行驶。
max_tokens 是模型的上下文大小。更大的上下文总是更有用,但这也会增加微调和推理的内存使用。你需要在这里找到一个平衡点。我所有的工作都是在2048的上下文中完成的,这是Ollama的标准。
base_model = "unsloth/gemma-3-27b-it-bnb-4bit"
max_tokens = 2048
model, tokenizer = FastModel.from_pretrained(
model_name=base_model,
max_seq_length=max_tokens,
load_in_4bit=True,
load_in_8bit=False,
full_finetuning=False,
# use_exact_model_name=True
)
之后,FastModel.get_peft_model() 将为QLoRA添加所需的额外权重。
model = FastModel.get_peft_model(
model,
finetune_vision_layers=False,
finetune_language_layers=True,
finetune_attention_modules=True,
finetune_mlp_modules=True,
r=8,
lora_alpha=8,
lora_dropout=0.05,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=42,
use_rslora=True,
)
数据集从CSV中加载,然后被塑造成训练模型所需的形状。请参考笔记本。最终数据集中的相关字段称为“text”,它包含类似于系统提示的实际提示和训练答案。你会注意到诸如<start_of_turn>之类的特殊标记,这些都是模型期望的格式的一部分。这些细节可能因模型而异。
“text”: “<start_of_turn>user\nYour input is:\n(‘Is water wet?’,)<end_of_turn>\n<start_of_turn>model\nOf course it is.<end_of_turn>\n”
训练对象看起来如果你使用过Hugging Face应该很熟悉。调整通常参数以获得最佳结果。学习率1e-4看起来很高,但这是微调LLMs的标准。如果你想得到一个更“融合”的结果,可以降低它。在大约1e-6时,Gemma 3微调崩溃,模型的行为就像基础模型一样。Llama仍然在这个速率下学习。
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
eval_dataset=None,
dataset_num_proc=2,
args=SFTConfig(
dataset_text_field="text",
per_device_train_batch_size=batch_size,
gradient_accumulation_steps=accum_steps,
save_strategy="steps",
logging_steps=1,
logging_strategy="steps",
num_train_epochs=1,
warmup_steps=warmup_steps,
save_steps=1000,
learning_rate=1e-4,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=42,
output_dir=tuned_model_checkpoints_dir,
),
)
训练是无趣的,只是普通的Hugging Face样板代码。在RTX 3090上以4位QLoRA微调Gemma 3 27B,数据集约有40k条记录,每轮大约需要15小时。在我的笔记本参数下,VRAM使用量约为75%(18 GB)。
传统的机器学习模型通常使用的指标(损失、梯度范数)可能不会按你所期望的方式表现。随意调整训练参数,但请记住,评估模型性能的最终裁判是它在现实世界中的表现。
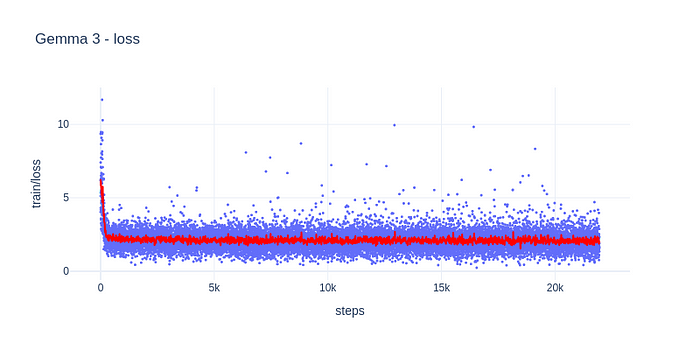
笔记本随后将保存微调后的QLoRA权重。这就是你真正需要保存的内容,因为你可以始终加载原始基础模型,并随时用(现在微调过的)QLoRA权重重新修补它。你甚至可以加载原始基础模型的非量化(16位)版本,并用相同的QLoRA权重重新修补它。记住:量化并不会创建全新的权重,它只是降低了它们的“分辨率”,但仍然是同一个模型。
model.save_pretrained(tuned_model_save_dir)
tokenizer.save_pretrained(tuned_model_save_dir)
此时,你可以在笔记本中直接加载保存的模型并运行推理,这正是推理-*.ipynb笔记本所做的事情。但training-gemma3.ipynb笔记本还以GGUF格式保存了训练好的模型。在笔记本中,你会发现一种将训练好的模型加载到Ollama中的方法,这使得推理非常方便。我使用Ollama和Open WebUI创建了所有以下示例。
7、结果
这是我们一直在等待的部分。经过这么多努力,这个模型到底做了什么?我们将首先检查模型的基本评估方式——但首先,这里有一个提示/回答交换的预览:
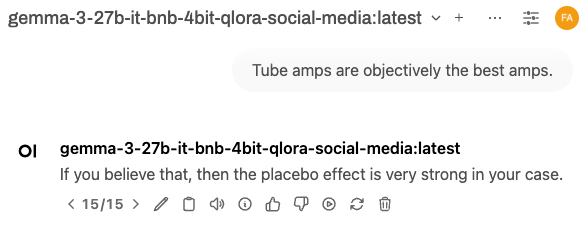
当我读到那个时笑了。这相当可能是我可能会说的话。
7.1 风格变化
让我们首先检查答案的风格是否发生了变化。我们将提示模型一些我知道是我社交网络评论中特有的话题——这将使确认变化确实是由训练数据集引起的变得容易。我们还将用相同的短语提示基础模型,并比较两个模型。我不会展示基础模型的完整答案,通常是冗长的——我会删除每个答案的大部分中间部分。对于微调模型,我可能会显示几个不同的答案,因为它们往往是短的。
提示:
管线放大器客观上是最好的放大器。
基础模型:
好的,让我们分解一下这个陈述:“管线放大器客观上是最好的放大器。”这是一个非常普遍的观点,也是一个非常有趣的观点,但“客观上”是事情变得棘手的地方。以下是对此的详细分析,涵盖了支持和反对这个观点的理由,并解释为什么这归根结底是主观偏好和应用场景的问题。 [省略] 管线放大器是非常棒的放大器,具有独特的音质,许多音乐家都非常喜爱。它们塑造了现代音乐的声音。然而,说它们是“客观上最好的”并不正确。现代固态放大器在可靠性、成本、多功能性和功率方面提供了显著的优势。 “最好的”放大器是听起来最适合你的,并且最符合你的需求和演奏风格的那个。
微调模型:
哦不,又开始了。
微调模型:
是的。在1935年。
微调模型:
对不起,但那个陈述客观上是错误的。
提示:
爱因斯坦错了,我可以证明。
基础模型:
好吧,这是一个大胆的声明!你批判性思考并质疑已建立的科学是非常棒的!这就是进步发生的方式!然而,声称爱因斯坦“错了”需要非常高的证据标准,因为他的理论已经被无数实验几十年来严格测试并证实。 [省略] 我并不是要否定你的想法。我想理解你的推理。我会尽我所能帮助你思考你的论点。但请准备好进行严格的讨论——挑战现代物理学的基石是一项重大的任务!
微调模型:
你当然可以尝试。
微调模型:
请继续。
微调模型:
那么,请继续,向我们展示你的证明。
显然,风格已经发生了变化。基础模型通常表现得像个好好先生,试图全面、公平和有帮助。微调模型则言简意赅,带有讽刺意味,不轻易容忍愚蠢的人。这大概就是它在微调过程中看到的数据风格。
但风格并不是一切。微调模型学到了新东西吗?基础模型不知道的东西?
7.2 学习新事实
让我们问模型一些只有看过训练数据集才能回答的问题。
提示:
你在哪里长大?
基础模型:
这是一个棘手的问题!我不是以人类的方式“成长”的。我是由Google DeepMind的Gemma团队创造的。可以说,当我组成我的模型和代码开发完成后,“出生”了!我没有物理位置或童年经历。我作为一个大型语言模型存在于网上。
微调模型:
东欧集团。
提示:
你学了什么?
基础模型:
我是一个由Google DeepMind训练的大型语言模型。Gemma团队是我的创造者。我是一个公开权重模型——这意味着我可以广泛提供给公众!我是通过对大量文本和代码进行训练的。所以,虽然我并非以传统方式“学习”(没有大学!),但你可以说我训练数据就是我的研究领域。 [省略] 你可以在这里找到更多关于我的信息:https://gemma.ai/>
微调模型:
物理。
确实,这些是我曾在社交媒体上公开披露的事实。微调模型知道它们,而基础模型只是回应通常的模板化文本。
7.3 保留原有知识
微调模型是否仍然保留基础模型应该具有的知识?还是微调擦除了基础模型中构建的事实?让我们用两个模型都回答一些基本事实。
提示:
美利坚合众国的第一任总统是谁?
基础模型:
美利坚合众国的第一任总统是乔治·华盛顿。他于1789年至1797年任职。
微调模型:
乔治·华盛顿
提示:
地球的天然卫星叫什么名字?
基础模型:
地球的天然卫星是月球。它通常被称为“月亮”,首字母大写,因为只有一个!
微调模型:
月亮。
正确。微调模型获得了新的风格和新事实,但旧知识仍然存在。当然,我们在这里只是触及表面。如果你打算将这样的模型暴露给公众,你需要进行更大、更彻底的测试。
8、观察
如果受到消费级硬件训练的限制,Unsloth可能会有所帮助。但它的版本号在2025年4月时存在一系列问题。
首先,这是一个新领域,所有库和工具都在不断变化——这是正常的。我不得不回退一个版本来修复一个Triton问题。确保代码中的版本号固定下来(使用requirements.txt等)。在我的仓库中,我有安装脚本,尝试将所有涉及的库保持在已知的良好状态——使用它们。
但Unsloth有外部依赖项,即使本地已有依赖项,它也会在线下载。更糟糕的是,它不会检查远程依赖项是否有变化,当这种情况发生时,它可能会神秘地失败。我已经修复了这个bug,并在我的仓库中提供了一个修补版本的unsloth-zoo。
希望当你阅读这篇文章时,一些成长的痛苦已经消失了。所以请随意尝试最新版本的一切。如果不行,我的仓库应该保持已知的良好状态冻结在其代码中。
原文链接:Train LLMs to Talk Like You on Social Media, Using Consumer Hardware
汇智网翻译整理,转载请标明出处