Gemma3 270M:最小通用LLM
Gemma 3 270M是Google Gemma 3家族中最小的成员,可能是迄今为止最实用的一个。这不仅仅是一个轻量级模型,它是一个高效完成实际工作的工具,不会耗尽你的设备或钱包。

人工智能领域一直有一种对大小的痴迷。更大的模型,更多的参数,庞大的数据集。但假如真正的魔法不是在于扩大规模,而是在于聪明地缩小呢?
进入Gemma 3 270M,这是Google Gemma 3家族中最小的成员,可能是迄今为止最实用的一个。这不仅仅是一个轻量级模型,它是一个高效完成实际工作的工具,不会耗尽你的设备或钱包。
1、快速了解Gemma 3 270M

Gemma 3 270M有2.7亿个参数。听起来很多?在AI世界里,它很紧凑。相比之下,旗舰模型如Gemini或GPT-4则达到数十亿甚至数百亿个参数。
但不要被数字迷惑,Gemma 3 270M并不是为了赢得尺寸竞赛而设计的。它是为“遵循指令”、在微型设备上运行以及进行精确的任务微调而构建的。
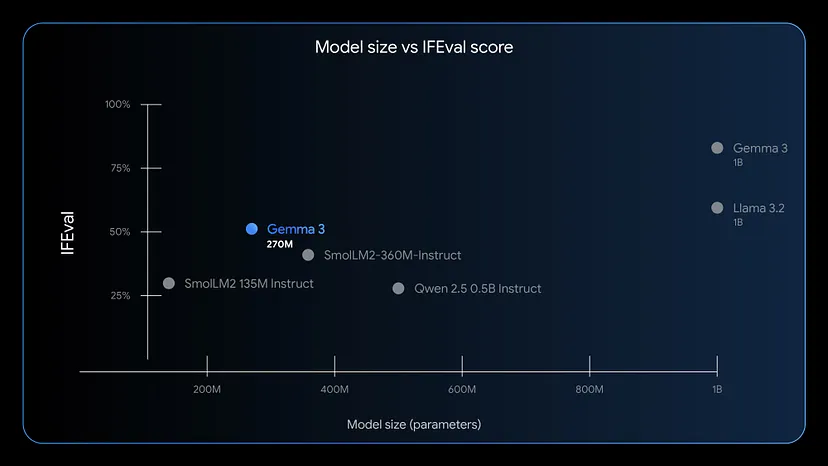
它被训练成能够直接理解并遵循指令。在IFEval(检查模型遵循指令的能力)基准测试中,它的表现是该尺寸下最好的之一。
这就像用社区大学的预算获得常春藤联盟的表现。
2、内部结构
- 紧凑的核心:总共2.7亿个参数。其中1.7亿用于嵌入(感谢25.6k的token词汇表),1亿用于transformer块。这个词汇表的大小意味着它比大多数小型模型更好地理解不常见的单词和符号。
- 极其高效:在Pixel 9 Pro上,量化(INT4)版本的Gemma 3 270M只需消耗手机0.75%的电量即可处理25次对话。
- 有两种口味:你将获得一个通用的预训练模型,还有一个经过指令微调的版本。后者可以像“总结这封邮件”或“从这段文字中提取名字”这样的命令,而无需额外训练。
- 支持量化:它支持QAT(量化感知训练),因此可以在INT4精度下运行,几乎不会影响质量。
3、它不是最好的,但确实非常有用
事实是:构建AI工具并不总是关于马力。你不会用推土机来种郁金香。
Gemma 3 270M遵循同样的逻辑,当你需要一件事做得很好时,它非常完美。例如:
- 将杂乱的文本转化为结构化数据
- 对电子邮件或支持工单进行分类
- 从法律文件中提取实体
- 在多语言应用程序中过滤有毒内容
- 为简单的创意工具(如睡前故事生成器)提供动力
为什么要在那上面浪费计算资源运行一个数十亿参数的模型呢?
4、真实案例研究:SK Telecom
这里有一个关于少即是多的故事。Adaptive ML与SK Telecom合作,必须在多种语言中进行内容审核。他们没有选择一个巨大的通用模型,而是对一个4B的Gemma模型进行了微调,以满足他们的特定任务。
结果,它在该领域内超越了一些最大的模型。
现在想象一下用一个270M的模型做类似的事情。更快,更便宜。而且如果任务狭窄且明确,这是完全可能的。
5、在以下情况下使用它

你应该选择Gemma 3 270M的情况包括:
- 你在处理大量小而重复的任务
- 你在构建需要快速运行的应用程序,即使是在低端设备上
- 你想要一个尊重用户隐私的模型,因为它可以完全离线运行
- 你需要快速原型设计和迭代
- 你计划部署多个专业模型用于不同的角色
这就像组建一支专家助手团队,而不是聘请一位价格过高的通才。
6、如何开始使用它
Google让开始变得很容易。这里是简短的路线图:
- 从Hugging Face、Kaggle、LM Studio、Docker或Ollama下载
- 使用
llama.cpp、Gemma.cpp、Keras、MLX或Vertex AI运行它 - 使用你喜欢的库、Unsloth、Hugging Face、JAX进行微调
- 在任何地方部署:你的笔记本电脑、Google Cloud,甚至如果你足够有雄心的话,也可以在你的树莓派上
而且,是的,已经有一个基于这个模型的睡前故事网页应用——完全在你的浏览器中运行,不需要互联网。这就是我们所说的小巧但功能强大。
该模型是开源的,可以在huggingface上访问。
8、结束语
Gemma 3 270M不仅仅是一个“小模型”。它是一种哲学转变。要聪明地建造,而不仅仅是大。减少浪费。专业化。完成事情。
在一个追求臃肿的世界中,Gemma 3 270M回归到简约,但有头脑。如果你有一个专注的任务,不要过度设计它。从小处开始。从Gemma 3 270M开始。
原文链接:Google Gemma3 270M : The best Smallest LLM for everything
汇智网翻译整理,转载请标明出处
