MapAnything三维重建实战
MapAnything 等基于 Transformer 的 AI 技术无需数百张完美重叠的照片,即可理解图像中的几何结构。

你是否曾希望只需将相机对准某个物体,就能立即获得它的 3D 模型?
我刚刚完成了一个工作流程,它正是为此而设计的。
它可以将任何图像集,即使是来自旧智能手机的模糊图像,转换为度量 3D 点云。
我在翻看以前的旅行照片时,找到了一组来自挪威卑尔根的照片。
2016年,我用手机尝试进行摄影测量,拍了几张这座很酷的巨魔雕像的照片。

这是3D重建项目的初始输入照片。这四张拍摄于2016年的挪威卑尔根巨魔雕像照片,曾用于使用MapAnything生成3D模型。
这次,我将同样的照片输入到一个新的人工智能模型中。不到一分钟,我就得到了一个完整的、按比例缩放的3D模型。
这说明什么?硬件不再是瓶颈,瓶颈在于软件的智能。
如果不需要完美的拍摄过程呢?
我们正在从“数据密集型”摄影测量转向“数据智能型”重建。
MapAnything 等基于 Transformer 的 AI 技术无需数百张完美重叠的照片,即可理解图像中的几何结构。
这是一种混合方法——它感觉像摄影测量,但思维方式更像 AI,能够从上下文(而不仅仅是像素)推断深度和形状。
这不仅仅是一个炫酷的技巧。
这意味着您可以更快地生成 3D 模型,并且能够处理更复杂、更多样化的数据源——例如无人机拍摄的视频、谷歌街景,甚至是 AI 生成的图像。
在本教程中,我将一步一步地引导您完成整个过程。
那么问题来了:如果创建 3D 数据像拍照一样简单,你会构建什么呢?
场景设定完毕后,我们便可以开始 Python 之旅了。一切都已准备就绪。你会看到各种技巧(🌱成长笔记、📈市场洞察和🦥技术笔记)、代码(Python)以及🗺️图表,帮助你充分利用本文。
1、你的任务:在数字时代记录文化遗产
你现在身处挪威卑尔根。雪花轻柔地洒落在鹅卵石上。游客们聚集在中世纪的码头周围。

该项目在挪威卑尔根进行,旨在记录文化遗产。中世纪码头的这幅景象,正是当地巨魔雕像3D重建的背景。
这里有一座巨魔雕像。体型巨大。雕刻精细。它是这座城市民间传说的一部分。
博物馆馆长找到你。他们需要一个数字档案。一个用于虚拟展览的高质量3D模型。供世界各地的游客探索。他们希望模型精确,并且能够快速交付。
你只有一部智能手机,并且精通Python。
传统的做法需要专家参与。需要数周的规划。需要摄影测量设备。需要手动校准。需要处理密集的点云。需要生成网格。需要进行纹理映射。
需要数月的工作。成本高达数万美元。
你绕着巨魔走了一圈。从不同角度拍摄了34张照片。自然光。手持拍摄。没有三脚架。没有参考目标。
回到笔记本电脑前,你想研究一种新方法:一种名为 MapAnything 的 Transformer 架构。
你想要的是一个完整的点云。RGB 颜色映射自源图像。可用于 Open3D 可视化。导出为 PLY 格式以便集成到博物馆中。
导演正在等待,你想给他留下好印象。
这就是你即将构建的工作流程。零帧重建意味着零帧。微调。模型在训练过程中从未见过你的巨魔雕像。它不需要。
那么,我们究竟该如何构建这个雄心勃勃的转型项目呢?
2、初始化:设置你的开发环境
好的,让我们确保通过完善的、循序渐进的系统设计来实现这个创新方法。
首先,让我们正确地组织数据。
2.1 2D - 3D 数据集访问
使用您选择的任何数据集,或文章末尾提供的数据集。您还可以从 Google 街景、AI 生成的图像或任何具有同一对象/场景的多个视角的资源中随机获取图片。
例如,我还使用谷歌的低质量街景图像进行了实验。

甚至还有一些我从一段短视频中的 X-Wing 模型中提取的截图(我无法追踪原作者;如果您知道原作者是谁,请帮我分享短视频的链接!)。

如果使用卑尔根巨魔图像,您应该拥有:
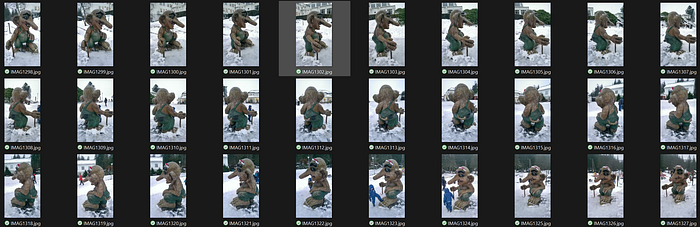
- 格式:JPEG 或 PNG
- 分辨率:每张图像 1520x2688
- 数量:34 张不同视角的图像
- 覆盖范围:重叠视图对于多视角一致性至关重要
将所有图像放在一个文件夹中(例如 DATA 文件夹)。我们将自动处理加载。
漂亮!现在,我们首先要确保数据和环境设置正确。为此,我们将分 5 个阶段进行。
2.2 创建干净的 Anaconda 环境
打开终端。按顺序运行以下命令:
# Create new environment with Python 3.12
conda create -n anything python=3.12 -y
# Activate it
conda activate mapanything
# Verify version
python --version # Should show Python 3.12.x这隔离了依赖关系。您的系统 Python 保持不变。
2.3 安装支持 CUDA 的 PyTorch
这是 GPU 能力发挥作用的地方。如果您想获得出色的性能,必须安装支持 CUDA 绑定的 PyTorch。访问 pytorch.org 并选择您的配置。

对于 Windows 上的 CUDA 12.6:
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu126安装后,要验证 CUDA 的可用性,请输入 python(在终端中,只需输入 python),然后:
import torch
print(torch.cuda.is_available()) # Should return True
print(torch.cuda.get_device_name(0)) # Shows your GPU存在 CPU 回退,但推理速度预计会降低 10-50 倍。不适用于扩展。
2.4 安装库:MapAnything 框架
MapAnything 位于 GitHub,而不是 PyPI。

直接从源代码安装:
# Clone the repository
git clone https://github.com/facebookresearch/map-anything.git
cd map-anything然后,安装可编辑模式。我推荐你查看 MapAnything Github 仓库,里面有所有说明,团队做得太棒了!
# For all optional dependencies
# See pyproject.toml for more details
pip install -e ".[all]"
pre-commit install-e 标志表示“可编辑安装”。源代码的更改会立即生效,无需重新安装。
2.5 安装其他库:Open3D + Numpy
Open3D 将处理我们实验中的点云几何和渲染。因此它是可选的,但在原型设计时很有用:
pip install open3d此外,你还需要 NumPy 来进行数组操作。大多数安装都自动包含它,但显式安装比隐式安装更好:
pip install numpy最后,我们可以组织项目结构了:
anything-project/
├── CODE/ # Your Python code, incl. map anything
├── DATA/ # Your input images, in subfolders
└── RESULTS/ # Your output point clouds将您的 34 张巨魔图像放置在 DATA/ 文件夹中。我们将处理文件夹路径或显式图像列表。
2.6 常见安装问题及修复
好的,我在安装 MapAnything 或 CUDA 时遇到了一些问题。以下是我记录的一些故障排除技巧,希望能对您有所帮助:
问题:CUDA 内存不足错误
解决方案:我们代码中的环境变量有所帮助:
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"这启用了动态内存扩展,而不是预分配。这对于可变大小的图像至关重要。
问题:Open3D 导入失败
解决方案:请先检查 Python 版本。然后验证没有冲突的安装:
pip uninstall open3d
pip install open3d==0.18.0问题:MapAnything 导入失败
解决方案:确保您处于已激活的 conda 环境中:
conda activate mapanything
python -c "from mapanything.models import MapAnything"如果失败,请从源代码重新安装。
问题:GPU 推理速度慢
解决方案:验证 PyTorch 是否检测到您的 GPU:
import torch
print(torch.cuda.is_available())
print(torch.version.cuda)如果结果为 False,则表示您安装了仅支持 CPU 的 PyTorch。请使用 CUDA 重新安装。
2.7 内存要求
大致要求如下:
- RAM:最低 16GB,32GB 更合适
- VRAM:34 张图片最低 8GB,12GB 以上更理想
- 存储空间:10GB 用于模型缓存和数据集
如果你的 GPU VRAM 较少,请启用 memory_efficient_inference=True。这会以速度换取容量——根据 Meta 的文档,140GB GPU 最多可支持 2000 次浏览。
基础已经扎实。是时候构建重建了吗?
3、配置内存管理和核心导入
好了,我假设您已经设置完毕,并像我一样顺利安装并打开了 IDE:
让我们确保在 3D Python 会话中能够按计划使用所有内容。
PyTorch 的默认内存分配器会以固定的块预先预留 CUDA 内存。这对于持续的工作负载非常有效。对于可变大小的输入,会导致灾难性失败。
你的 34 张巨魔图像并不统一。有些图像捕捉的是广角,有些图像则放大到细节。分辨率各不相同,长宽比也不同。
每张图像都会生成一个唯一的 3D 预测张量。固定内存块碎片很快。即使有可用的 VRAM,你也会收到“CUDA 内存不足”的错误。
解决方案存在于一个环境变量中:
# Optional config for better memory efficiency
import os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"这启用了动态内存扩展。PyTorch 会根据需要请求 CUDA 内存,而不是预先分配内存池。内存碎片减少。多视图推理变得稳定。
内存配置完成后,我们导入核心库。PyTorch 提供张量运算功能。
# For getting Pytorch
import torch
#For getting mapanything
from mapanything.models import MapAnything
from mapanything.utils.image import load_images
# Our base loving stack
import numpy as np
import open3d as o3dMapAnything 提供推理模型。Open3D 处理 3D 可视化。NumPy 管理数组转换。导入顺序并不重要,重要的是导入是否正确。在继续操作之前,请检查每个导入是否正确无误。
4、了解 PyTorch 的 CUDA 上下文
导入 PyTorch 时,它不会立即分配 GPU 内存。 CUDA 上下文采用延迟初始化。首次对 GPU 执行张量操作时才会触发内存分配。
这一点至关重要,因为错误通常发生在推理阶段,而非导入阶段。在模型尝试创建第一个激活张量之前,您的环境可能看起来一切正常。
下一步应显式测试 CUDA 可用性,而不是假设导入已成功。
但我们实际是在哪个设备上进行计算呢?
4.1 设备检测和硬件验证
MapAnything 的计算量非常大。
每张图像大约会生成 300 万个 3D 预测。34 张图像:1.02 亿个点。Transformer 通过多个注意力层处理这些点,每个注意力层都需要对高维嵌入进行矩阵乘法运算。
CPU 推理是存在的,技术上可行,但实际上无法使用。
在现代 CPU 上,处理一张图像需要 5-10 分钟。处理 34 张图像至少需要 3-6 小时。而 GPU 推理呢?同样的工作负载只需 15-20 分钟即可完成。
20 倍的加速并非奢侈,而是迭代实验与一次性碰运气之间的区别。
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)这段代码会立即运行,告诉你推理将使用哪个硬件。
如果输出显示 "cuda":一切就绪,可以放心继续。
如果输出显示 "cpu":推理可以运行,但速度会非常慢。考虑使用云端 GPU(例如 Google Colab、AWS、Lambda Labs)或减少测试图像的数量。
🌱 重要提示:对于生产系统,除了可用性检查之外,还需要检查设备的性能。使用 torch.cuda.get_device_properties(0).total_memory 查询显存,并与数据集的需求进行比较。对于 34 张 1920x1080 分辨率的图像,预计会占用约 8GB 显存。如果内存不足,请在步骤 4 中启用内存高效推理。
设备检查可确保硬件安全。接下来,我们需要智能——预训练的 Transformer 模型。
4.2 从 HuggingFace Hub 加载 MapAnything 模型
此步骤将下载 1.2GB 的空间理解学习数据。
MapAnything 模型已在海量多视图数据集上进行元训练。该模型已处理数百万个图像对,并学习了物体在不同角度下的外观。
它已内化相机透视几何结构,并编码了来自阴影、纹理和视差的深度线索。
您无需训练任何模型,只需加载已积累的知识即可。
model = MapAnything.from_pretrained("facebook/map-anything").to(device)
# For Apache 2.0 license model, use "facebook/map-anything-apache"from_pretrained() 方法处理所有操作。首次调用会从 HuggingFace Hub 下载权重。后续运行将从 ~/.cache/huggingface/ 目录下的缓存加载。
.to(device) 调用会将模型移动到 GPU。这会将所有 6 亿个参数从 CPU 内存复制到显存。在现代硬件上,这需要 3-5 秒。
MapAnything 基于 DUSt3R 的编码器-解码器 Transformer 架构构建。
架构图展示了 DUSt3R 模型(MapAnything 的基础)如何处理无约束的图像集合并生成密集的 2D-3D 点云图。、
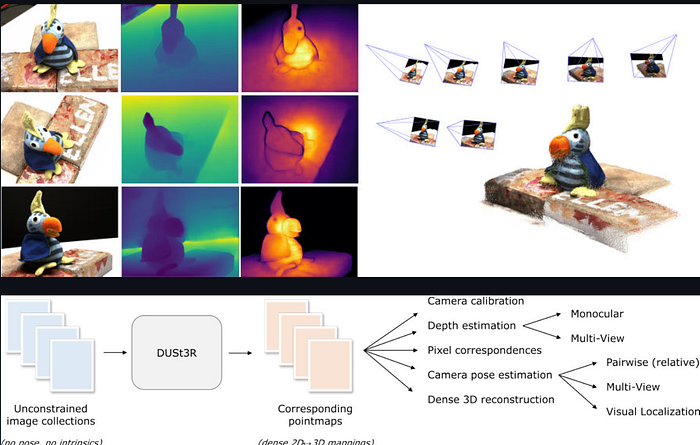
编码器通过视觉变换器 (ViT) 独立处理每幅图像。像素块被转换为标记。自注意力机制发现局部和全局特征。没有卷积层——纯粹的注意力机制。
解码器在图像对之间执行交叉注意力。它找到对应关系。它预测每个像素的密集三维坐标。它同时估计相机位姿。
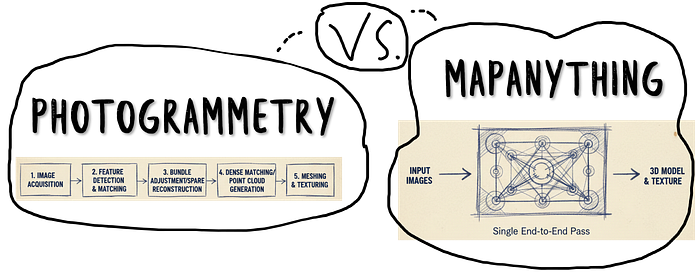
这与传统的摄影测量方法有着根本的不同。经典流程:
- 提取稀疏特征(SIFT、ORB)
- 跨视图匹配特征
- 三角测量三维点
- 优化光束法平差
- 使用多视图立体视觉进行密集化
MapAnything 取代了五步流程,一次前向传播。Transformer 学习了端到端的几何预测
。
原始论文在此:MapAnything: Scaling Dense Matching for General Cameras and Scenes (Meta AI Research, 2025)。请阅读该论文以了解其损失函数和训练过程的数学基础。
🦥 技术说明:MapAnything 使用了一种混合注意力机制——在图像内部使用窗口化自注意力以提高效率,然后在图像对之间使用全局交叉注意力。这平衡了计算成本(全局注意力的 O(n²))和建模能力。对于 34 张图像,该框架会智能地对图像对进行分批处理,以避免计算所有 561 种可能的组合。
模型已加载。设备已验证。现在我们需要数据——即构成几何体的图像。
4.3 图像加载和自动预处理
MapAnything 接受两种输入格式。
选项 1:文件夹路径 — 指向包含图像的目录。加载器会自动查找所有 JPEG 和 PNG 文件。图像顺序按字母顺序排列。
选项 2:显式列表 — 提供包含完整路径的 Python 列表。可以精确控制图像的顺序和选择。
对于 ../DATA/ 目录下的 34 张巨魔图片,最简洁的文件夹路径是:
images = "../DATA/" # or ["path/to/img1.jpg", "path/to/img2.jpg", ...]
views = load_images(images)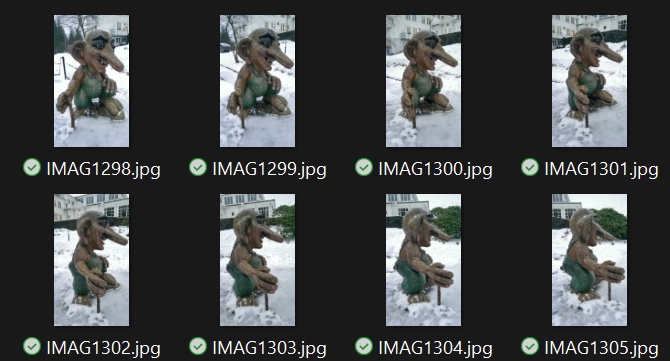
load_images() 函数在后台执行了大量工作。
- 调整大小:图片缩放至高效分辨率。MapAnything 可以处理各种尺寸,但标准化为 1024x768 或类似尺寸可以提高批量处理效率。该函数在保持宽高比的同时,将图片尺寸控制在可管理的范围内。
- 归一化:将像素值从 [0, 255] 整数转换为 ImageNet 标准化的浮点数。均值减去和标准差除以确保模型看到的数据与其训练分布相匹配。
- 张量转换:将 NumPy 数组转换为 PyTorch 张量。通道数从 HWC(高度、宽度、通道数)重新排序为 CHW(通道数、高度、宽度)——PyTorch 的预期格式。
- 批量处理:将多张图像堆叠成一个张量,以实现高效的 GPU 处理。
您无需编写此预处理代码。框架会自动处理。您只需指定图像即可。
🌱 重要提示:对于处理数千张图像的生产系统,请实现延迟加载。不要同时将所有图像加载到 RAM 中。使用 PyTorch 的 Dataset 和 DataLoader 类在推理期间流式传输图像。MapAnything 的架构支持批量处理,因此可以轻松实现。
更高的分辨率意味着更多的细节。
这也意味着计算量呈指数级增长。一张 1920x1080 的图像有 207 万像素。每个像素都会生成一个 3D 预测结果。注意力机制的计算量与序列长度呈二次方关系。
实用指南:
- 1024x768:推理速度快,大多数主题都能获得良好的图像质量
- 1920x1080:在细节和速度之间取得平衡,适用于文化遗产
- 3840x2160:最高质量,需要 16GB 以上的显存
您的 34 张图像的分辨率可能各不相同。MapAnything 可以很好地处理这种情况,但统一的分辨率可以提高批处理效率。
好的,接下来该做什么?
4.4 使用优化参数运行推理
推理配置决定了输出质量、处理时间和内存使用情况。
MapAnything 提供了八个关键参数。每个参数都会对某些方面进行权衡。
predictions = model.infer(
views, # Input views
memory_efficient_inference=False, # Trades off speed for more views (up to 2000 views on 140 GB)
use_amp=True, # Use mixed precision inference (recommended)
amp_dtype="bf16", # bf16 inference (recommended; falls back to fp16 if bf16 not supported)
apply_mask=True, # Apply masking to dense geometry outputs
mask_edges=True, # Remove edge artifacts by using normals and depth
apply_confidence_mask=False, # Filter low-confidence regions
confidence_percentile=10, # Remove bottom 10 percentile confidence pixels
)让我们来剖析每个参数及其含义。
views - 您的预处理图像张量。这里没有选择余地——这是您的数据。
memory_efficient_inference=False - 标准模式并行处理图像对,最大限度地提高 GPU 利用率。启用该模式 (True) 可串行化处理,速度会降低 3-5 倍,但可在 140GB VRAM 上处理最多 2000 个视图。对于 8-12GB GPU 上的 34 张图像,请将此设置为 False。
use_amp=True - 自动混合精度 (AMP) 启用 fp16 或 bf16 计算,而不是 fp32。现代 GPU(Volta+、RTX 系列、A100)运行 16 位数学运算的速度提高了 2-3 倍,推理精度保持不变。除非您使用的是老旧的硬件,否则请始终启用此设置。
amp_dtype="bf16" - Brain 浮点 16 位 (bfloat16) 优于浮点 16 位 (fp16)。 BF16 的动态范围与 fp32 相同,但精度有所降低——非常适合梯度精度无关紧要的推理。如果您的 GPU 不支持 bf16(Ampere 之前的架构),则会自动回退到 fp16。
apply_mask=True - 使用模型的内部遮罩逻辑过滤无效预测。无效区域包括遮挡区域、模糊几何形状和边缘伪影。启用此功能会减少点数,但会显著提高重建质量。
mask_edges=True - 专门使用深度和法线预测去除边缘伪影。Transformer 有时会在上下文不完整的图像边界处产生幻觉几何形状。边缘遮罩可以防止这些伪影污染您的点云。
apply_confidence_mask=False - 使用每像素置信度得分进行二次过滤。默认情况下禁用,因为它过于激进——会删除 10-30% 的有效点。如果您的拍摄对象具有清晰、明确的特征,并且您优先考虑精度而非召回率,请启用此功能。
confidence_percentile=10 - 启用置信度掩蔽后,移除置信度最低的 10% 像素。百分位数越低,滤波效果越强,点数越少,但质量越高。对于文化遗产文献记录,5-15 百分位数效果较好。

在此基础上,我们将调整推理过程,使其返回一个预测字典列表。每个输入视图对应一个字典。
4.6 提取每个视图的 2D/3D 元素
每个字典应包含 11 个键,即三个类别:几何输出、相机输出和质量指标:
for i, pred in enumerate(predictions):
# Geometry outputs
pts3d = pred["pts3d"] # 3D points in world coordinates (B, H, W, 3)
pts3d_cam = pred["pts3d_cam"] # 3D points in camera coordinates (B, H, W, 3)
depth_z = pred["depth_z"] # Z-depth in camera frame (B, H, W, 1)
depth_along_ray = pred["depth_along_ray"] # Depth along ray in camera frame (B, H, W, 1)
# Camera outputs
ray_directions = pred["ray_directions"] # Ray directions in camera frame (B, H, W, 3)
intrinsics = pred["intrinsics"] # Recovered pinhole camera intrinsics (B, 3, 3)
camera_poses = pred["camera_poses"] # OpenCV (+X - Right, +Y - Down, +Z - Forward) cam2world poses in world frame (B, 4, 4)
cam_trans = pred["cam_trans"] # OpenCV (+X - Right, +Y - Down, +Z - Forward) cam2world translation in world frame (B, 3)
cam_quats = pred["cam_quats"] # OpenCV (+X - Right, +Y - Down, +Z - Forward) cam2world quaternion in world frame (B, 4)
# Quality and masking
confidence = pred["conf"] # Per-pixel confidence scores (B, H, W)
mask = pred["mask"] # Combined validity mask (B, H, W, 1)
non_ambiguous_mask = pred["non_ambiguous_mask"] # Non-ambiguous regions (B, H, W)
non_ambiguous_mask_logits = pred["non_ambiguous_mask_logits"] # Mask logits (B, H, W)
# Scaling
metric_scaling_factor = pred["metric_scaling_factor"] # Applied metric scaling (B,)
# Original input
img_no_norm = pred["img_no_norm"] # Denormalized input images for visualization (B, H, W, 3)几何输出:
- pts3d:世界坐标系中的三维坐标(米)
- pts3d_cam:3相机坐标系中的 D 坐标
- depth_z:Z 深度(垂直于图像平面)
- depth_along_ray:沿视线的深度
相机输出:
- intrinsics:3x3 相机标定矩阵
- camera_poses:4x4 相机到世界坐标系的变换
- cam_trans:平移向量
- cam_quats:四元数旋转
- ray_directions:逐像素射线方向
质量指标:
- conf:逐像素置信度得分
- mask:组合有效性掩码(边缘 + 模糊性)
- non_ambiguous_mask:具有清晰几何形状的区域
- 额外:img_no_norm(原始 RGB 值)、metric_scaling_factor(尺度归一化)
主要使用以下三个:pts3d(世界坐标)、mask(有效性)和 img_no_norm(颜色)。
推理完成后,预测结果存储完毕,GPU上仍然保留着PyTorch张量。我们究竟该如何查看几何体呢?
4.6 解码预测张量并理解数据类型
预测结果以CUDA张量的形式存在。
你无法直接可视化它们。你无法将它们保存到文件中。你无法使用标准工具(至少不能直接)操作它们。
转换为NumPy格式是必要的步骤。因此,让我们循环遍历每个元素以收集必要的输出。
#%% Step 5. Understanding and Converting Data Types
np_pts3d = np.asarray(pts3d.cpu())
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(np_pts3d[0][1])
o3d.visualization.draw_geometries([pcd]).cpu() 方法将张量从 VRAM 移动到 RAM。然后 np.asarray() 创建 NumPy 视图,而无需复制数据。
在构建完整流程之前,请先验证基本几何结构:
# Create simple Open3D point cloud from first view
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(np_pts3d[0][1])
o3d.visualization.draw_geometries([pcd])这应该会显示部分重建。它看起来并不完整——它只是来自一个视图的一条线。
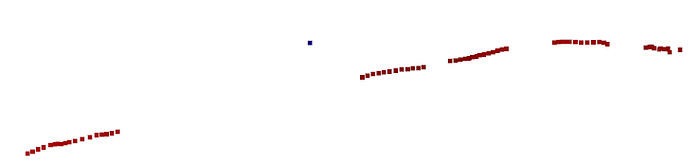
现在,让我们看一个完整的单视图重建。
4.7 使用蒙版过滤提取有效的 3D 点
并非所有像素预测都是有效的。
Transformer 在图像边缘处产生幻觉。它们难以处理遮挡。它们会在无纹理区域生成模糊的几何形状。
蒙版会过滤这些有问题的预测。该函数处理维度变化。有些预测具有批次维度,有些则没有。代码自动适配:
#%% Step 7. Single View Point Extraction Function
def extract_points_from_prediction(prediction, apply_mask=True):
"""Extract valid 3D points and mask from a single view prediction."""
pts3d = prediction["pts3d"].cpu().numpy()
if pts3d.ndim == 4:
pts3d = pts3d[0]
if apply_mask and "mask" in prediction:
mask = prediction["mask"].cpu().numpy()
if mask.ndim == 4:
mask = mask[0, :, :, 0]
elif mask.ndim == 3:
mask = mask[0]
mask_bool = mask > 0.5
else:
mask_bool = np.ones((pts3d.shape[0], pts3d.shape[1]), dtype=bool)
points = pts3d[mask_bool]
return points, mask_bool掩码值范围为 [0.0, 1.0]。低于 0.5 的值无效。高于 0.5 的值有效。这种二元划分是神经网络掩码的标准做法。但为什么是 0.5 呢?
模型输出的 logits 被转换为概率。0.5 表示对有效和无效的置信度相等。更高的阈值(0.7、0.8)会使过滤更加严格。更低的阈值(0.3)会保留更多点,但会包含噪声。
我使用 points = pts3d[mask_bool] 进行过滤。这是 NumPy 的布尔索引。它只选择掩码为 True 的元素。效率极高——底层运行速度与 C 语言相当。
另一种方法是使用显式循环检查每个像素,这可能需要几秒钟。
现在,为了进行可视化,您可以使用以下命令:
# Test on first view
points_view0, mask_view0 = extract_points_from_prediction(predictions[0])
print(f"View 0: Extracted {points_view0.shape[0]:,} valid points")
# Visualize single view
pcd_view0 = o3d.geometry.PointCloud()
pcd_view0.points = o3d.utility.Vector3dVector(points_view0)
pcd_view0.paint_uniform_color([0.7, 0.3, 0.3]) # Red for first view
print("Visualizing first view only...")
o3d.visualization.draw_geometries([pcd_view0], window_name="View 0 Only")返回结果:
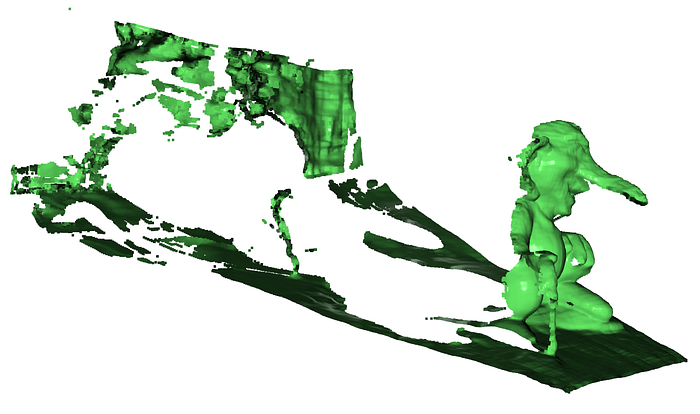
这是从单个图像视图生成的博根巨魔雕像的 3D 点云。单色表示尚未应用 RGB 数据。
但单色点云缺乏视觉吸引力。颜色在哪里?
4.8 从源图像映射 RGB 颜色
每个 3D 点都对应一个特定的像素。
该像素在原始图像中具有一个 RGB 颜色值。我们需要将这些颜色映射到点。
挑战在于:图像在预处理过程中进行了归一化。像素值从 [0, 255] 转换为 ImageNet 标准化的浮点数。
我们需要原始的 RGB 值。
幸运的是,MapAnything 会存储去归一化后的图像:在每个预测结果中存储 img_no_norm。
让我定义一个与点提取逻辑相对应的函数(使用相同的掩码索引。访问反归一化图像。提取对应的颜色):
def extract_colors_from_prediction(prediction, mask_indices):
"""Extract RGB colors for valid points from the input image."""
img = prediction["img_no_norm"].cpu().numpy()
if img.ndim == 4:
img = img[0]
colors = img[mask_indices]
colors = np.clip(colors, 0.0, 1.0)
return colors要进行测试,您可以为第一个视图应用颜色:
colors_view0 = extract_colors_from_prediction(predictions[0], mask_view0)
pcd_view0.colors = o3d.utility.Vector3dVector(colors_view0)
print(f"Applied {colors_view0.shape[0]:,} RGB colors to view 0")
# Visualize with colors
print("Visualizing first view with colors...")
o3d.visualization.draw_geometries([pcd_view0], window_name="View 0 with Colors")巨魔现在应该以自然颜色显示。灰色石头。绿色苔藓:

如果颜色看起来不正确:
- 过亮/过暗:检查是否正确应用了反归一化
- 色调异常:颜色通道顺序可能错误(RGB 与 BGR)
- 灰度:颜色实际上未被分配
现在我们已经为一个视图着色,还有 33 个视图等待处理。是时候合并所有视图了。但我们该如何操作呢?
4.9 将多视图预测合并为完整重建
每个视图都提供部分重建结果。
合并所有 34 个视图,即可获得完整的 360° 覆盖范围。
合并过程很简单:从每个视图中提取点和颜色,然后垂直堆叠。
def merge_all_views_to_pointcloud(predictions, apply_mask=True, verbose=True):
"""Merge all view predictions into a single Open3D point cloud with RGB colors."""
all_points = []
all_colors = []
for i, pred in enumerate(predictions):
points, mask = extract_points_from_prediction(pred, apply_mask=apply_mask)
colors = extract_colors_from_prediction(pred, mask)
all_points.append(points)
all_colors.append(colors)
if verbose:
print(f"View {i+1}/{len(predictions)}: {points.shape[0]:,} points")
merged_points = np.vstack(all_points)
merged_colors = np.vstack(all_colors)
if verbose:
print(f"\n✅ Total merged points: {merged_points.shape[0]:,}")
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(merged_points)
pcd.colors = o3d.utility.Vector3dVector(merged_colors)
return pcd点云本质上是 XYZ 坐标列表。垂直堆叠会将数组沿第一维度连接起来——这正是我们合并点集所需要的。
对于 34 张图像,其中 30% 的无效像素已被屏蔽:
- 每个视图的点数:约 130,000 个
- 合并点总数:约 450 万个
这完全可以占用 16GB 内存。
坐标一致性
一个关键假设:所有视图共享同一个世界坐标系。
MapAnything 在推理过程中确保这一点。模型会预测相机姿态,从而自动对齐所有视图。不要手动注册或对齐任何内容。
这与传统的摄影测量有着本质区别,传统摄影测量需要运行光束法平差来优化对齐。Transformer 模型学习输出一致的坐标。
有时,视图会出现错位(在大场景中发生漂移)。对于亚米级的文化遗产记录,这应该是可以控制的。对于精密工程,我们需要应用 ICP 后处理。
pcd_complete = merge_all_views_to_pointcloud(predictions, apply_mask=True, verbose=True)
# Visualize complete reconstruction
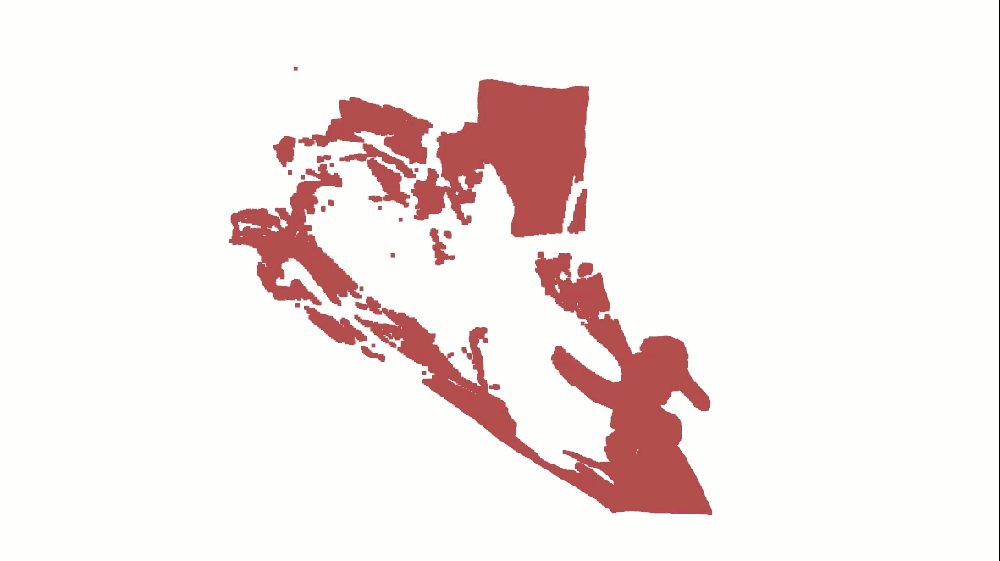
o3d.visualization.draw_geometries([pcd_complete], window_name="Complete 3D Reconstructions")可视化结果应显示巨魔雕像的各个角度。

这是由 34 个不同视图合并而成的博根巨魔的完整 3D 点云。最终生成了一个连贯且细节丰富的模型,可直接导出并进行后期处理。
旋转视图。放大查看细节。几何形状应保持连贯。

完整的 3D 模型已构建完成。但它仅存在于内存中。如何保存它?
4.10 导出为标准 3D 格式
PLY(多边形文件格式)是点云的事实标准。
它简单易用,支持广泛,能够高效地存储 XYZ 坐标和 RGB 颜色。Open3D 只需一行代码即可完成导出:
output_file = "../RESULTS/troll.ply"
o3d.io.write_point_cloud(output_file, pcd_complete)默认情况下,文件以二进制 PLY 格式写入——这种格式紧凑且加载速度快。 450 万个彩色点,预计文件大小约为 110 MB,您可以从外部加载:

其他格式:
- XYZ:基于文本,简单但文件巨大
- PCD:点云数据格式(PCL 库)
- LAS/LAZ:LiDAR 标准,包含元数据
- OBJ/STL:网格格式(需要先进行表面重建)
后处理注意事项
导出的点云是原始数据——直接来自推理过程,并已应用掩膜。
常见的后处理步骤:
统计异常值去除:使用 KNN 距离度量过滤孤立点。Open3D:pcd.remove_statistical_outlier(nb_neighbors=20, std_ratio=2.0)
体素下采样:在保持结构的同时降低点密度。Open3D:pcd.voxel_down_sample(voxel_size=0.01)
法线估计:计算用于渲染或网格划分的表面法线。Open3D:pcd.estimate_normals(search_param=o3d.geometry.KDTreeSearchParamHybrid(radius=0.1, max_nn=30))
表面重建:使用泊松或球形旋转生成网格。泊松分布非常稳健:o3d.geometry.TriangleMesh.create_from_point_cloud_poisson(pcd, depth=9)
为了专注于 MapAnything 的核心工作流程,我们跳过了这些步骤。
工作流程已完成。34 张智能手机拍摄的图像被转换为 450 万个具有自然色彩的精确 3D 点。已导出为行业标准格式。可用于博物馆集成。
但这项技术的未来发展方向是什么?
5、未来方向和高级应用
MapAnything 代表了零样本 3D 重建的现状。
下一代技术正在崛起。让我们探索这项技术的未来发展方向。
- 移动硬件上的实时重建
当前限制:MapAnything 需要桌面级 GPU。
Transformer 模型体积庞大。在移动芯片上推理速度较慢。但模型压缩技术正在快速发展。
预计两年内,智能手机应用将能够实现实时 3D 重建,并在用户采集数据的同时进行重建。量化、剪枝和知识蒸馏等技术将使 MapAnything 的模型大小缩小至 100MB,并在 Apple Silicon 和 Snapdragon 芯片上以 30fps 的帧率运行。
这使得 AR 眼镜能够持续重建你的环境。无需预映射ng。无需信标。只需通过视觉输入即可立即理解空间。
- 与大型语言模型集成
MapAnything 输出几何图形。LLM理解语义。
将它们结合起来,你就获得了空间智能。该模型不仅能重建巨魔,还能识别“雕刻的巨魔雕像,挪威民间传说风格,高约 2.5 米,风化花岗岩”。
这种语义丰富功能将原始 3D 数据转换为可查询的空间知识图谱。博物馆可以搜索他们的藏品:“给我看看所有 15 世纪带有装饰雕刻的木制文物。”
- 嵌入自定义 3D 应用程序
MapAnything 的强大之处在于其模块化。
导出相机姿态并与游戏引擎集成。导出深度图并在自定义相机中启用人像模式。导出置信度蒙版并驱动质量控制流程。
该框架采用 Apache 2.0 许可(针对开放版本)。您可以将其嵌入到商业产品中。构建房地产虚拟导览生成器。创建博物馆展品扫描仪。开发施工进度监控仪表板。
Transformer负责最繁重的工作——几何预测。您负责构建应用层。
目标客户是联合国教科文组织世界遗产、大学博物馆和政府文化部门。您的护城河并非技术(它是开源的),而是工作流程集成和领域专业知识。
- 与传统摄影测量的比较
MapAnything 牺牲了一些精度,换取了极大的灵活性。
精度:专业摄影测量通过合适的地面控制点 (GCP) 和仔细的校准可以达到毫米级精度。MapAnything 无需任何校准即可达到十厘米级精度。
速度:摄影测量需要数小时的特征匹配和光束法平差。MapAnything 只需几分钟即可完成。
易用性:摄影测量需要专业知识。MapAnything 需要 GPU。
对于文化遗产文献记录,厘米级精度通常就足够了。您需要保存的是形态、纹理和空间关系,而不是测量结构公差。
对于精密工程或法律文献记录,请坚持使用摄影测量。对于快速数字孪生、便捷的 3D 捕捉和 AI 驱动的工作流程,MapAnything 也能派上用场。
- 添加几何和语义先验
当前的 MapAnything 是通用的——它不会对您的主题做出任何假设。
未来的版本将集成先验。告诉模型“这是一栋建筑”,它会强制执行建筑约束(垂直墙壁、水平地板)。在语义引导下,重建质量将显著提升。
这需要微调或调节机制。架构支持这一点。即将实现。
同样,已知尺寸或参考对象等几何先验支持度量缩放。目前,MapAnything 的比例是一致的,但可以任意调整。添加“此对象为 30 厘米”的注释,所有内容都会根据实际测量值正确缩放。
6、结束语
本教程为您提供了完整的重建流程。从智能手机照片到可用于博物馆的 3D 图像。
技术将不断发展。模型将压缩。精度将提高。速度将提升。
但基础技能——理解基于 Transformer 的几何预测、配置推理参数、处理多视图预测——仍然很有价值。
你现在已经掌握了这些基础。你将其运用到哪里将决定你的影响力。
原文链接:How to Create 3D Models From ANY Image with AI (Zero-Shot 3D Reconstruction)
汇智网翻译整理,转载请标明出处
