本地AI = Ollama+OpenWebUI
我不希望这些大公司挖掘我的个人数据并开始用它们向我推销广告。更不用说他们也不应该分析我的行为!这就是我决定自己托管自己的AI的原因。

如果你和我一样,你可能已经使用了太多AI工具——比如ChatGPT、Perplexity等。虽然登录网站并开始输入查询非常方便,但我总是觉得不能在上面问所有问题,因为我知道我的数据会被用来分析我的行为。一个简单的例子是,我想检查我的健康问题,并看看如何管理它。我在ChatGPT中输入了它,结果让我惊讶的是,一天之内我就开始收到相关药品的广告。
我不确定你是否也这样,但我强烈支持数据隐私。我不希望这些大公司挖掘我的个人数据并开始用它们向我推销广告。更不用说他们也不应该分析我的行为!这就是我决定自己托管自己的AI的原因。由于我使用的是2020年的MacBook Air作为个人电脑,我使用云GPU租赁平台来满足我的需求。
1、Ollama和OpenWebUI到底是什么?
如果你还没有听说过这两个框架,那你肯定错过了很多!以下是对每个框架的一个(非)正式介绍:
1.1 Ollama

Ollama是一个轻量级的开源框架,允许你在本地运行LLM(在你自己的PC或云实例上)。它可以将LLaMa、Mistral、Gemma等开源模型打包成一个二进制文件,让你只需简单地输入ollama run <model>就可以轻松安装和使用。最棒的是,它跨所有平台都受到支持——Mac OS、Linux和Windows——所以如果你有一台更强大的Mac Studio或工作站,你可以无缝使用它。在过去几年里,它因其易于使用而广受欢迎,使用户能够完全控制自己的数据,从而优化性能和成本。
1.2 OpenWebUI
{kind=link}
如果你是ChatGPT风格聊天界面的忠实粉丝,并且想在本地部署相同的界面,那么OpenWebUI就是你的答案。它是Ollama的补充应用,基本上提供了一个基于网络的UI,旨在使与LLM的交互变得容易和可访问。它给你一个干净的聊天式体验——类似于其他聊天应用程序——但完全在你自己的机器上运行。对于任何想要一种简单、注重隐私的方式来与强大语言模型互动的人来说,这都非常棒。不仅如此,你还可以使用它来访问Open AI兼容API!它也非常可定制——正如你在本文后面会看到的那样。
介绍了这些之后,我们直接进入正题吧!
2、设置
2.1 设置你的实例
本教程的这一部分是平台特定的到RunC.AI,但是其他的GPU租赁平台也很相似,所以这一部分可以直接转换过来。我的大多数应用程序都部署在这个平台上,因为它们易于设置、便宜,非常适合像我这样的爱好者。继续设置—
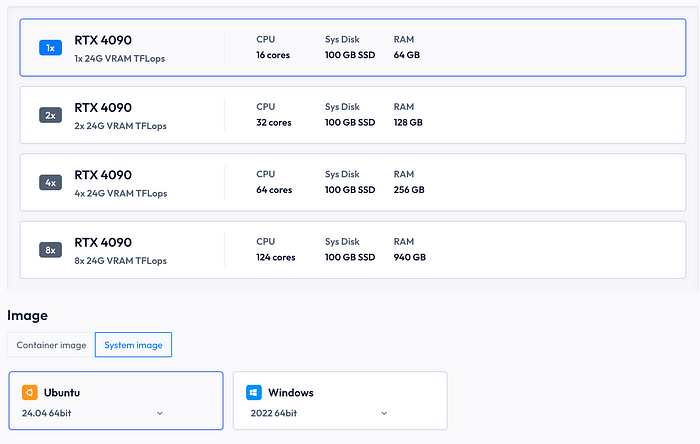
RunC.AI在部署你的实例时提供了两种图像选择:一种是系统镜像(Windows/Ubuntu),另一种是容器镜像(PyTorch、CUDA、DeepSeek-R1和许多其他)。因为我们想要一个完整的AI工作站,我们将选择Ubuntu系统镜像并在其上部署我们的应用程序。首先,在该平台上创建一个帐户,并选择带有你选择的GPU的Ubuntu系统镜像。他们有多种GPU选项,但我发现单个RTX-4090足以满足我的应用程序。不过,当我运行图像生成模型或训练密集型任务时,我会升级到4个RTX-4090。
一旦你部署了你的实例,只需使用提供的密码登录(复制pswd字段)。通过浏览器访问你的实例的IP地址列在Outer字段中。
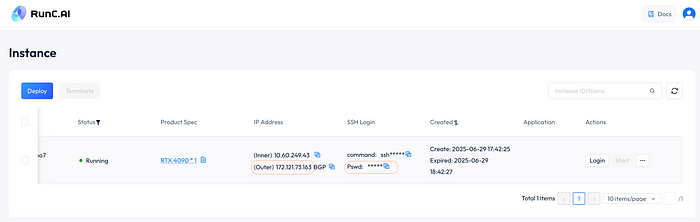
只需使用ssh命令和密码在你选择的终端中远程访问你的实例。
2.2 设置Ollama
注意 — 从现在开始,每个平台的设置都是一样的!
一旦你登录到你的实例,使用以下命令安装Ollama:
curl -fsSL https://ollama.com/install.sh | sh
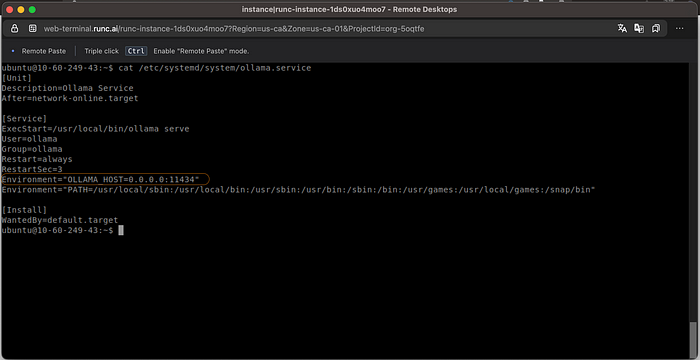
安装完成后,编辑ollama.service文件以启用你的localhost和Docker容器之间的通信。使用以下命令打开服务文件:
sudo vi /etc/systemd/system/ollama.service
在那里,你会看到环境变量OLLAMA_HOST,你需要将其设置为0.0.0.0:11434。最后,你的服务文件应该如下所示:
如果一切看起来都正常,使用以下命令重新启动Ollama守护进程:
sudo systemctl daemon-reload
sudo systemctl restart ollama
如果一切正确设置,当你在浏览器中打开分配给你的实例的IP地址并加上端口11434时,你应该会看到以下内容:
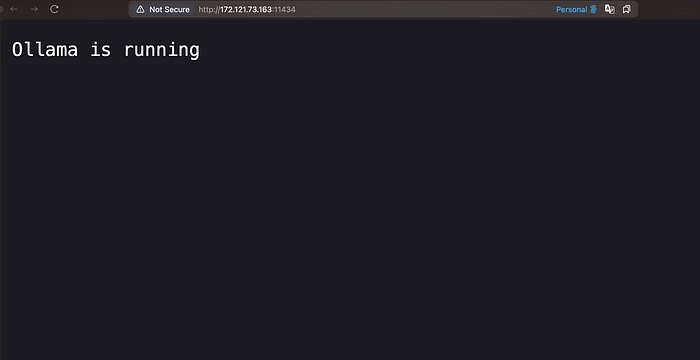
你现在可以按照以下方式拉取任何你想要的模型:
ollama pull <model>
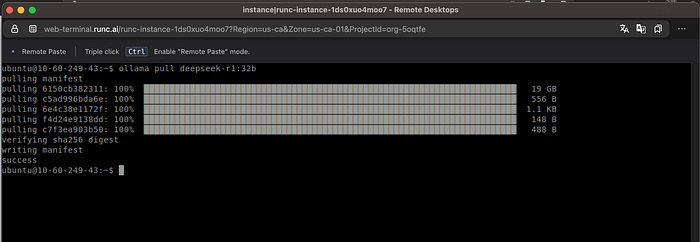
2.3 使用Ollama下载模型
注意 — 确保你下载的模型能适应你的GPU!
我个人为每个任务部署了以下三个模型:
- Qwen-2.5 Coder — 用于代码相关的任务
- Gemma3 — 用于视觉相关的任务
- DeepSeek-R1 — 用于日常、分析和思考任务
我也尝试过其他模型,但发现上述模型最适合我的需求。现在你可以直接从终端运行这些模型:
ollama run <model>
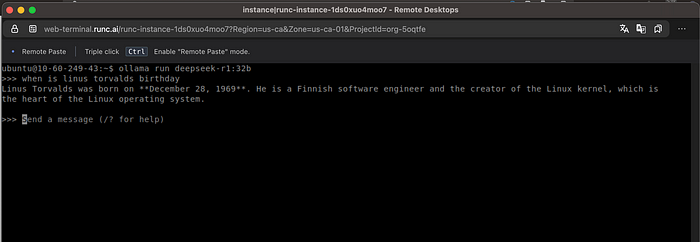
但谁会想要那个呢。如果你想有一个类似ChatGPT的网页界面,下一节将帮助你设置它。
2.4 设置Open-WebUI
要设置OpenWebUI,你首先需要按照这里的说明安装docker,然后使用以下命令拉取docker镜像:
sudo docker pull ghcr.io/open-webui/open-webui:cuda
一旦你下载了镜像,只需使用以下命令运行它并使用所有可用的GPU:
docker run -d --network=host -v open-webui:/app/backend/data \
-e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart \
always ghcr.io/open-webui/open-webui:cuda
一旦它开始运行,只需访问http://your.IP.address:8080。第一次访问此网站时,它会要求你注册新帐户。这个帐户将是管理员,因此请确保你不要丢失这个帐户的凭据!
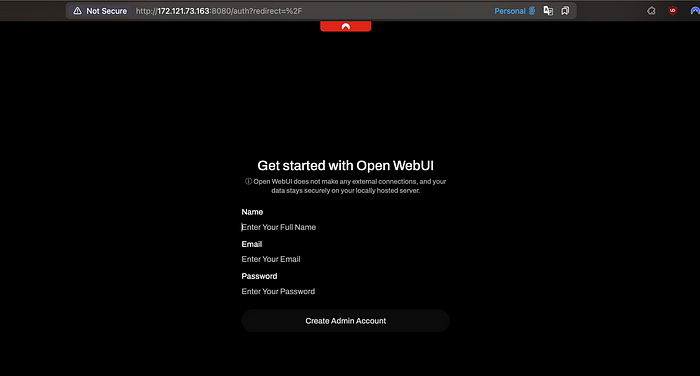
3、你能用这个做什么?
Open-WebUI基本上是一个功能齐全的网页界面,你可以做通常在像ChatGPT或Gemini这样的界面上所做的任何事情。
3.1 选择你的模型
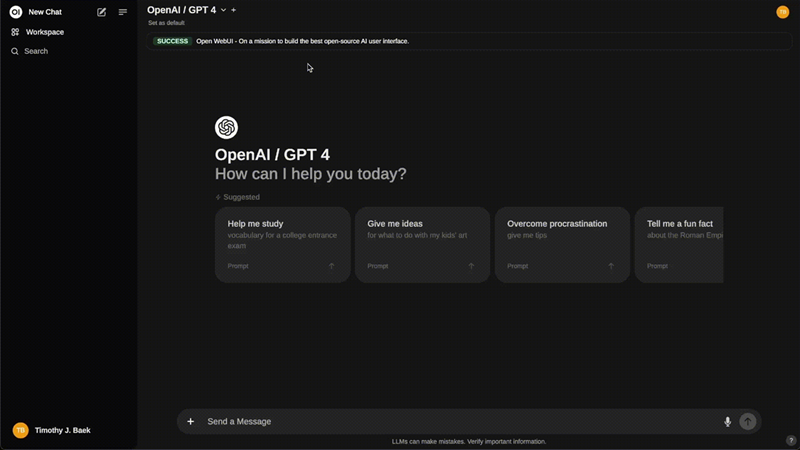
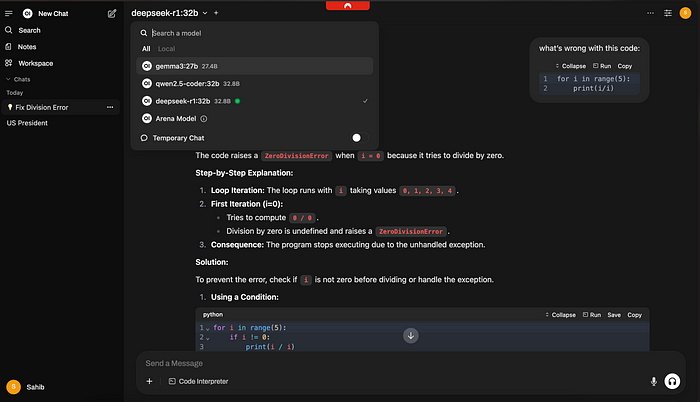
类似于Perplexity或You,你可以从下拉菜单中选择各种不同的模型,如下面的图片所示。如上所述,我通常使用DeepSeek-R1进行日常任务。
3.2同时使用多个模型
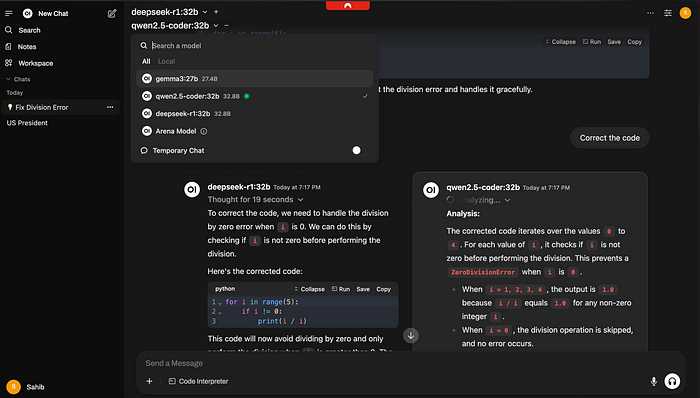
使用模型选择下拉菜单右侧的“+”符号,你可以选择多个模型一起生成输出。例如,我让DeepSeek和Qwen-Coder来纠正代码。这在你想比较或一起使用多个模型,或者根据你的提示生成多模态输出时非常有用。你也可以通过在聊天中使用@<model>和你的提示来与特定模型交谈。
3.3 上传并交互文件
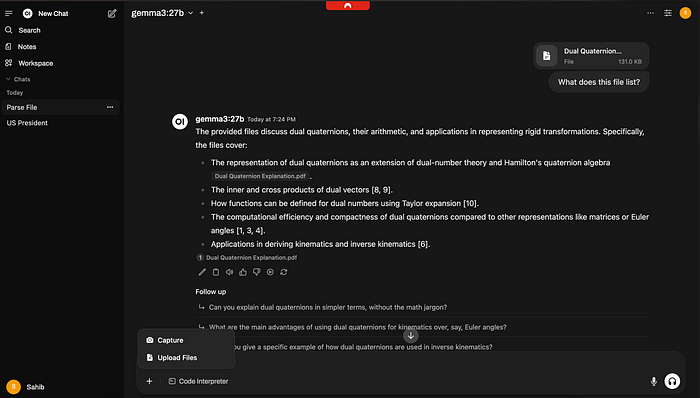
这个工具的另一个非常有用的功能是查看、解析和响应文件。这对于想要与大型文档进行交互并理解它们非常有用。只需上传你想要的文件并询问模型一个问题!
3.4 添加新用户
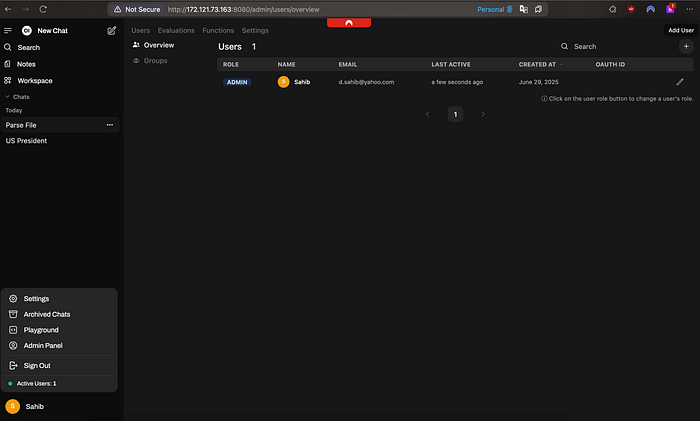
这更多是在管理员方面。如果你想让其他人(可能是你的家人或团队成员)访问你的实例并与LLM互动,你可以轻松地添加/管理新用户。只需点击左下角的用户图标,然后通过管理员面板添加/删除/更新用户。
3.5 创建专业模型
当你要专门化一个基础模型时,这个功能非常有用。例如,如果你想专门化DeepSeek用于代码助手、博客写手、交易机器人,或者其他任何东西,只需提供适当的系统提示!只需点击左侧边栏聊天部分上方的“Workspace”,然后在模型部分创建一个新模型。例如,可以如下所示:
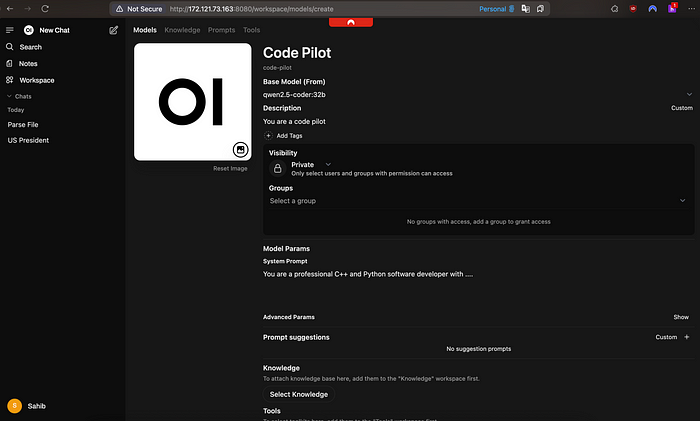
这显然不是Open-WebUI功能的完整列表,你肯定可以做更多的事情!例如,如果你想在你的服务器上设置Stable Diffusion来生成图像,请遵循这个仓库 。
将其连接到Open-WebUI。如果你有其他类型的应用程序想要覆盖,我建议你随意探索这个界面,看看还能做些什么!
原文链接:Host All Your AI Locally Using Ollama and OpenWebUI
汇智网翻译整理,转载请标明出处
