如何设计大规模AI系统
训练一个机器学习模型是一回事,也许在基准数据集上达到最先进的准确性。但将其部署,使其为数百万用户服务,处理TB级的数据,并可靠地全天候运行则是完全不同的挑战。

训练一个机器学习模型是一回事,也许在基准数据集上达到最先进的准确性。但将其部署,使其为数百万用户服务,处理TB级的数据,并可靠地全天候运行则是完全不同的挑战。
从一开始,训练和部署机器学习模型的每一个部分都需要仔细规划和合适的工具。
从早期开发到全面部署构建和运行一个AI系统是……
强大的软件开发技能变得非常重要,这是一个许多AI工程师都缺乏的差距
在这篇博客中,我们将探讨构建能够创建LLM、多模态模型以及各种其他AI产品的大型AI系统所需的每个开发阶段。这些开发阶段如何相互关联,以及它们各自的职责。
1、AI的系统和硬件
构建大规模AI系统的第一个步骤是选择正确的硬件。它影响你的模型运行的速度、花费的钱以及所有东西使用的能源。
在本节中,我们将讨论可用的不同硬件系统,以及如何使它们成本和能源效率更高。
1.1 AI计算硬件
广泛用于训练或其他AI任务的三种最常见的硬件类型是:
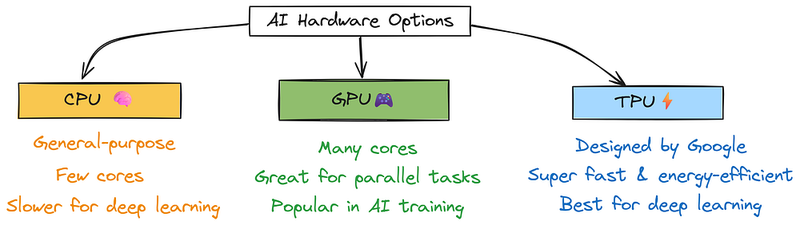
- CPU(中央处理器) 它们擅长做各种各样的任务,但核心数量不多,因此对于深度学习或需要大量并行处理的大规模AI任务来说较慢。
- GPU(图形处理单元) 最初是为视频和图形而设计的,但现在它们是AI的最爱。由于它们比CPU有更多的核心,这意味着可以同时处理很多事情,非常适合训练和运行AI模型。
- TPU(张量处理单元) 是Google专门为深度学习设计的特殊芯片。它们非常快,超级高效,能耗低。这使得它们非常适合大型复杂的AI任务。
你可以在这里了解更多:https://cloud.google.com/tpu
但是最近,由于对AI的需求增长,也引入了一些新的硬件类型。
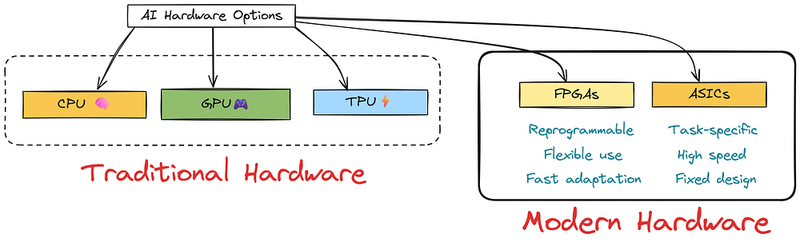
- 一个很好的例子是FPGA(现场可编程门阵列)。这些芯片很特别,因为它们可以根据不同的AI任务重新编程。它们让你根据模型的需求微调性能,这对于快速变化的AI项目非常有用。
- 然后是ASIC(专用集成电路)。这些不像CPU甚至FPGA那样通用。相反,它们专为一件事而设计:尽可能快、尽可能高效地运行AI模型。由于它们是为特定工作而设计的,比如驱动神经网络,所以它们节省能源并且运行得很快。
1.2 分布式AI系统
一旦你选择了优化的硬件并根据需求确定了模型架构,我们进入下一阶段,涉及如何规划AI的分布式系统。
分布式系统的主原则是……
将一个大任务分成小块,并让多个计算机同时处理它们。
在AI中,这通过共享工作负载来加速数据处理和模型训练。
因此,要创建一个分布式系统,我们需要牢记一些重要因素。让我们先可视化一下,然后理解其流程。
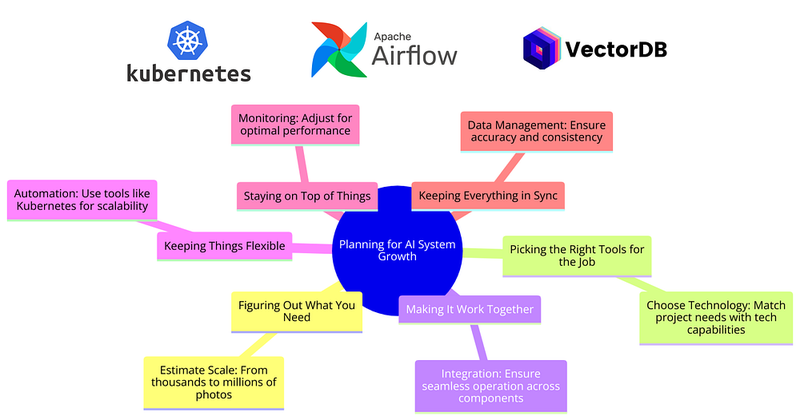
在将分布逻辑应用到我们的AI系统时,我们需要记住各种因素。让我们看看流程是如何进行的:
- 首先,我们需要了解规模。 我们是在处理几百、几千还是几百万个数据点?早期知道这一点有助于我们平滑地规划系统。
- 接下来,我们需要选择合适的工具。 根据项目的大小和类型,我们需要正确组合处理能力、内存和通信方式。云平台使管理这一切变得更加容易。
- 然后,确保一切协同工作。 系统的不同部分可能需要并行运行或在单独的机器上运行。我们的目标是避免减速并保持平稳运行。
- 之后,保持灵活性。 不再手动调整资源,而是自动化。像Kubernetes这样的工具可以帮助系统随着负载的变化自动调整。
- 我们还需要监控性能。 保持对系统的监控有助于我们及早发现问题,无论是数据分布不均还是网络瓶颈。
- 最后,确保一切都保持同步。 随着系统的扩展,关键在于数据和模型在所有部分之间保持一致。
1.3 优化网络
一旦你决定了AI系统的分布式部分,就需要确保所有组件都能正确连接。
它们必须能够顺畅且无故障地彼此通信
如果分布式组件无法有效通信,可能会破坏你的训练或生产代码。
让我们看看如何让对话流畅而不中断:
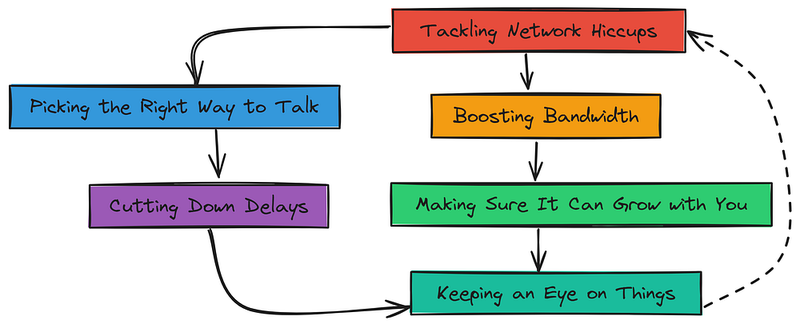
让我们分解一下:
- 首先,寻找潜在的减速点。 延迟、容量限制或丢失的数据都会严重影响性能,因此尽早识别这些风险很重要。
- 然后,减少延迟。 为了加快速度,我们使用更快的连接,将机器放在一起,或者甚至将一些处理转移到边缘。
- 接下来,增加带宽。 狭窄的网络路径会导致交通堵塞。我们通过压缩数据、优先处理重要信息或升级网络来解决这个问题。
- 之后,选择正确的通信方法。 有些协议在处理大量负载方面表现更好。挑选正确的协议可以确保系统运行得又快又高效。
- 我们还需要计划未来的发展。 随着系统的扩展,网络必须跟上。使用灵活的设置以便随需扩展是关键。
- 最后,监控网络。 定期检查有助于我们及早发现潜在问题。监控工具可以在问题减缓之前发出警报。
1.4 AI存储解决方案
因此,在决定训练或推理的硬件以及背后的分布逻辑之后,下一步就是存储,用于保存训练好的模型以及用户与AI模型交互的数据。
我们存储数据的方式必须智能,以满足今天的需求,并为明天更多的数据做好准备
我们有三种类型的数据存储系统:
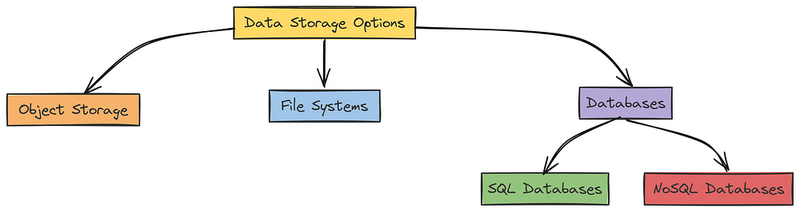
- 对象存储最适合大数据。 它是你可以不断添加文件而不用担心结构的地方。当你从多个来源获取数据并在以后合并时,它非常完美。
- 文件系统更适合较小的、有组织的设置。 它们有点像电脑上的文件夹。它们帮助保持整洁,当你的数据有限且结构良好时非常理想。
第三种类型是数据库,在数据有结构时很有用。以下是选择合适类型的技巧:
- SQL数据库适合有组织、有联系的数据。 当你的数据有明确的关系时,如用户、订单和产品,使用它们。它们非常适合复杂任务,其中准确性和一致性至关重要。
- NoSQL数据库适用于灵活或变化的数据。 如果你的数据不适合整齐的表格或快速增长,NoSQL选项如MongoDB或Cassandra提供了你需要的自由度和扩展性。
虽然工具本身很重要,但如何使用它们同样重要:
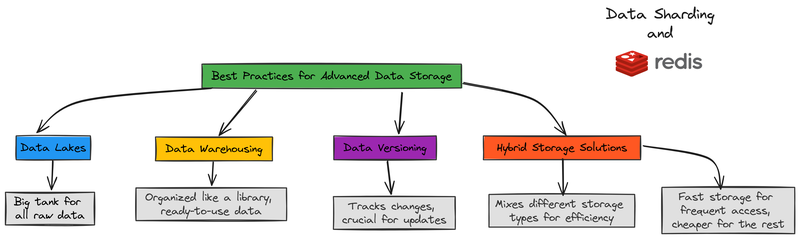
- 数据湖以原始形式保存所有内容。 它是一个巨大的容器,用于保存各种类型的数据,你可以稍后对其进行分类和处理。
- 数据仓库存储干净、随时可用的数据。 这就像一个井然有序的图书馆,你可以快速找到你需要的确切内容。
- 数据版本控制跟踪更改。 这在更新模型或处理随时间变化的数据时非常重要。它有助于保持条理清晰并防止错误。
- 混合存储结合速度和节约。 你对常用数据使用快速存储,其余数据使用廉价存储。这样你既能省钱又能快速访问必要的内容。
快速的数据访问对AI性能至关重要。
使用Redis等内存存储进行快速检索,并应用数据分片以分散负载并防止减速。
在某个时刻,你需要决定哪种存储设置最适合自己:云、本地还是两者的混合。
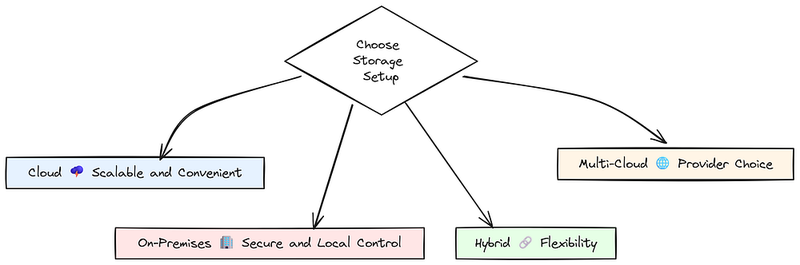
- 混合存储提供灵活性。 你可以将敏感数据保留在自己的服务器上,同时使用云进行其他所有操作。这有助于平衡安全性和可扩展性。
- 多云策略提供更多选择。 通过使用多个云提供商,你可以避免被锁定在一个供应商上。这就像有不同的菜单可供选择,具体取决于你的需求。
在选择硬件时,直接跳到GPU并不总是正确的做法,因为我们通常假设它们无论是在数据预处理、微调还是LLM推理方面都能自动提高性能。
然而,性能强烈依赖于……
模型架构+基础设施选择
- 在AI架构方面,一种有用的技术是模型量化,许多现代开源模型API提供商如Together AI或Nebius AI已经在使用这种方法。这意味着减少AI模型在计算时使用的细节量,例如使用更小的数字(例如8位而不是32位)。
- 在基础设施方面,云服务和虚拟化通常是最佳解决方案。与其购买昂贵的硬件,不如从AWS、Google Cloud或Azure等提供商租用强大的机器。这给你提供了根据项目灵活扩展或缩减的能力,既省钱又避免浪费。
看看谷歌提供的比较图,展示了不同模型架构在各种GPU上的表现。
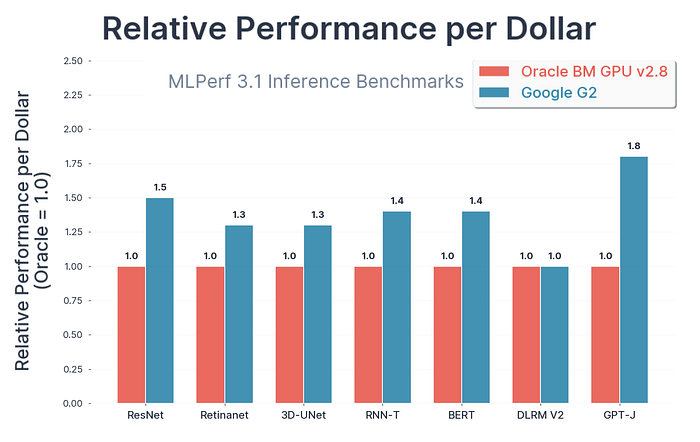
谷歌在MLPerf 3.1基准测试中进行了这项测试(主要用于衡量系统处理输入的速度)。
- 使用强大H100 GPU的A3 VM比旧的A2 VM在艰难的AI任务中快1.7到3.9倍。
- 使用L4 GPU的G2 VM是一个不错的选择,如果你想要在节省成本的同时获得良好的AI性能。
- 测试显示,L4 GPU每美元的性能提升可达1.8倍,与其他云服务相比。
像Bending Spoons这样的公司已经在使用G2 VMs,以高效地为用户提供新的AI功能。
2、高级模型训练技术
到目前为止,我们已经涵盖了硬件、存储以及如何充分利用它们。现在是时候看看训练技术的工作原理以及我们可以如何优化它们。
2.1 优化神经网络训练的策略
AI模型通常基于神经网络构建,虽然许多模型开始时使用基本的梯度下降法,但在现实世界场景中,还有更多先进的选项表现更好。
Adam优化是一个明智的选择。 它结合了AdaGrad和RMSprop的优点。它很好地处理了嘈杂的数据和稀疏梯度,使其成为流行的默认选择。
optimizer = optim.Adam(model.parameters(), lr=0.001)
RMSprop有助于学习稳定性。 它根据近期梯度行为调整学习率,适用于非平稳问题。
optimizer = optim.RMSprop(model.parameters(), lr=0.001, alpha=0.99)
Adagrad适应你的数据。 它为每个参数改变学习率,这对稀疏数据很好,但随着时间推移可能导致学习率过小。
optimizer = optim.Adagrad(model.parameters(), lr=0.01)
让我们有一个简单的表格,这将给我们一个高层次的概览,我们有什么优化器以及它们如何配合。
所以,这种比较可以帮助机器学习工程师决定选择哪个优化器。
我们可以安全地从Adam开始。尽管优化器之间存在差异,但重要的是从实用的东西开始并获得一些初步见解。
2.2 大规模训练的框架和工具
接下来是正则化技术,这是防止过拟合并确保模型在新数据上泛化良好的关键。这里有一些常见的方法可以帮助你的模型很好地泛化到新数据。
L2正则化与权重衰减通过阻止大权重来帮助,保持模型简单。
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5)
Dropout层在模型中随机丢弃神经元在训练过程中减少了过拟合的可能性。
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 第一层线性层:输入大小784(例如28x28图像)到256个神经元
self.layer1 = nn.Linear(784, 256)
# Dropout层,概率为50%,用于减少过拟合
self.dropout = nn.Dropout(0.5)
# 第二层线性层:256到10个输出类别(例如数字0-9)
self.layer2 = nn.Linear(256, 10)
def forward(self, x):
# 应用第一层线性变换
x = self.layer1(x)
# 应用dropout进行正则化
x = self.dropout(x)
# 应用第二层线性变换以生成输出logits
x = self.layer2(x)
return x
基于验证损失的早期停止。 如果验证损失不再改善,就没有必要继续训练。
best_loss = float('inf') # 初始化最佳损失为无穷大
patience = 10 # 在没有改进的情况下等待的轮数
trigger_times = 0 # 计算没有改进的轮数
for epoch in range(max_epochs):
val_loss = validate(model, val_loader) # 在验证集上评估
if val_loss < best_loss:
best_loss = val_loss # 更新最佳损失
trigger_times = 0 # 如果有改进,重置计数器
else:
trigger_times += 1 # 没有改进,增加计数器
if trigger_times >= patience:
print('Early stopping') # 如果连续'patience'轮没有改进,则停止训练
break
处理非常大的模型带来了新的挑战。这里有几种方法可以让它变得可控。
模型并行性将模型分割到多个GPU上。 模型的不同部分在不同的设备上处理。
# 定义一个顺序块并将其移到GPU 0
self.seq1 = nn.Sequential(
# 层在这里,例如nn.Linear(...)、nn.ReLU()等
).to('cuda:0')
# 定义另一个顺序块并将其移到GPU 1
self.seq2 = nn.Sequential(
# 层在这里
).to('cuda:1')
# 定义一个全连接(或其他)层并将其移到GPU 1
self.fc = nn.Linear(...).to('cuda:1')
数据并行性将数据分布在多个GPU上。 PyTorch DataParallel 自动管理这个过程。
model = DataParallel(MyModel())
model.to('cuda')
梯度累积允许更大的批量。 当内存受限时,它通过累积梯度在更新之前进行。
# 在开始累积之前重置梯度
optimizer.zero_grad()
for i, (inputs, labels) in enumerate(training_set):
# 正向传递
outputs = model(inputs)
# 计算损失
loss = loss_function(outputs, labels)
# 反向传递(累积梯度)
loss.backward()
# 每隔'accumulation_steps'次迭代执行一次优化器步骤
if (i + 1) % accumulation_steps == 0:
optimizer.step() # 更新模型参数
optimizer.zero_grad() # 重置梯度以供下次累积
联邦学习保持数据在本地设备上。 模型分别在各个设备上训练,只有更新会被共享。
for round in range(num_rounds):
model_updates = [] # 收集所有设备权重更新的列表
# 每个设备在其数据上本地训练
for device in devices:
updated_model = train_on_device(model, device.data) # 本地训练
model_updates.append(updated_model.get_weights()) # 收集权重
# 聚合更新(例如取平均值)并更新全局模型
model.set_weights(aggregate(model_updates))
为了在不失去太多性能的情况下使大型模型更高效,知识蒸馏是一个很好的方法。
使用大型教师模型训练小型学生模型。 这样可以减小模型大小,同时保持良好的准确性。
def knowledge_distillation_loss(outputs, labels, teacher_outputs, temp=2.0, alpha=0.5):
# 硬损失:标准交叉熵,学生预测与真实标签之间的交叉熵
hard_loss = F.cross_entropy(outputs, labels)
# 软损失:KL散度,学生和教师预测的概率分布之间的KL散度
# 温度应用于软化概率分布
soft_loss = F.kl_div(
F.log_softmax(outputs / temp, dim=1), # 学生logits(软化)
F.softmax(teacher_outputs / temp, dim=1), # 教师logits(软化)
reduction='batchmean' # 批量平均
)
# 最终损失:硬损失和软损失的加权和
# 按照原始KD论文推荐的方法,乘以温度的平方
return alpha * hard_loss + (1 - alpha) * soft_loss * (temp ** 2)
通过结合适当的优化器、正则化方法和训练策略,我们可以构建出既强大又高效的模型,即使在大规模情况下也是如此。
让我们有一个比较表来更好地理解这一点。
2.3 使用TensorFlow和PyTorch扩展规模
框架在大规模AI工作中起着重要作用。以下是一些流行的选择:
- TensorFlow 提供了TensorFlow Distributed Strategies,帮助在GPU和TPU上高效扩展训练。
- PyTorch 以其PyTorch Distributed闻名,支持在多个GPU和多台机器上扩展。
- Horovod 与TensorFlow、PyTorch和Keras一起工作,提高了在GPU和CPU上的可扩展性。
- Kubernetes 在运行大规模时帮助部署和管理AI工作负载。
- CUDA和cuDNN 加速GPU计算和深度学习性能。
- NeMo 专注于构建语音和自然语言处理模型。
2.4 模型扩展和高效处理
扩展模型 是处理大数据集和复杂任务的关键。让我们探索一些简单的方法来并行化模型和数据,智能地处理批次,并处理训练挑战。
模型并行性 当模型太大而无法在一个GPU上运行时,我们可以将其拆分到不同的设备上。你可以按层(垂直)或层的部分(水平)划分。目标是减少设备间的数据移动。
import torch
import torch.nn as nn
# 定义一个简单的模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.layer1 = nn.Linear(10, 20)
self.relu = nn.ReLU()
self.layer2 = nn.Linear(20, 10)
self.layer3 = nn.Linear(10, 5)
def forward(self, x):
# 手动将前向传播分成设备
x = self.layer1(x)
x = self.relu(x)
# 在继续之前将张量移动到第二个设备
x = x.to(device2)
x = self.layer2(x)
x = self.relu(x)
x = self.layer3(x)
return x
# 实例化模型
model = SimpleModel()
# 定义设备
device1 = torch.device('cuda:0')
device2 = torch.device('cuda:1')
# 将模型部分移动到相应设备
model.layer1.to(device1)
model.relu.to(device1) # 可选,因为ReLU是无状态且轻量的
model.layer2.to(device2)
model.layer3.to(device2)
# 示例输入张量在设备1上
x = torch.randn(1, 10).to(device1)
# 前向传递(在模型的forward内部处理)
output = model(x)
# output现在在设备2上
我们可以使用NCCL等快速通信库来减少数据移动时的延迟,并使用torch.cuda.synchronize()确保设备按顺序完成任务。
import torch
import torch.distributed as dist
############ NCL ############
def init_process(rank, size, backend='nccl'):
dist.init_process_group(backend, rank=rank, world_size=size)
world_size = 4
for i in range(world_size):
init_process(rank=i, size=world_size, backend='nccl')
############ 同步 ############
def synchronize_devices(devices):
for device in devices:
if 'cuda' in str(device):
torch.cuda.synchronize(device)
device1 = torch.device('cuda:0')
device2 = torch.device('cuda:2')
synchronize_devices([device1, device2])
数据并行性 我们可以在多个设备上对不同的数据块运行相同的模型。这在模型适合单个GPU但你想并行处理更多数据时非常有用。
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, Dataset, DistributedSampler
# 示例数据集
class CustomDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
# 初始化分布式训练
def setup(rank, world_size):
dist.init_process_group(backend='nccl', rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
# 创建带有分布式采样器的数据加载器
def get_dataloader(dataset, batch_size, rank, world_size):
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
return DataLoader(dataset, batch_size=batch_size, sampler=sampler)
# 示例用法
rank = 0
world_size = 2
setup(rank, world_size)
dataset = CustomDataset(torch.arange(1000))
dataloader = get_dataloader(dataset, batch_size=32, rank=rank, world_size=world_size)
model = SimpleModel().to(rank)
model = DDP(model, device_ids=[rank])
反向传播后,DDP跨设备同步梯度,使模型权重保持一致。
我们还可以通过梯度压缩来减少通信负载。这里有一个简单的版本,使用8位量化:
def quantize_gradients(model, bits=8):
q_level = 2**bits - 1 # 量化级别数(例如,8位为255)
for param in model.parameters():
if param.grad is not None:
grad = param.grad.data # 访问梯度张量
# 计算最小值和最大值以进行归一化
min_val, max_val = grad.min(), grad.max()
# 归一化到[0, 1]并缩放到[q_level, 1]
grad_norm = (grad - min_val) / (max_val - min_val + 1e-8) * q_level
# 量化:四舍五入到最近的级别
grad_quant = torch.round(grad_norm)
# 反量化:映射回原始尺度
grad_dequant = grad_quant / q_level * (max_val - min_val) + min_val
# 替换原始梯度为量化-反量化后的版本
param.grad.data = grad_dequant
高效的批量处理 通过调整批量处理方式,我们可以提高速度和内存利用率。
- 混合精度训练 使用半精度(float16)进行更快的计算:
scaler = GradScaler() # 处理缩放以防止float16梯度下溢
for data, target in dataloader:
optimizer.zero_grad() # 清除之前的梯度
with autocast(): # 启用混合精度——在安全的情况下使用float16,否则使用float32
output = model(data) # 前向传递(某些操作在float16中)
loss = loss_fn(output, target) # 计算损失(仍在float32中)
scaler.scale(loss).backward() # 缩放损失以避免梯度下溢,然后反向传播
scaler.step(optimizer) # 如果没有溢出,则取消缩放并调用optimizer.step()
scaler.update() # 调整下一次迭代的缩放比例
- 梯度累积 如果你的GPU无法处理大批次,这会有帮助:
optimizer.zero_grad()
accum_steps = 4
for i, (data, target) in enumerate(dataloader):
output = model(data)
# 按累积步数缩放损失
loss = loss_fn(output, target) / accum_steps
loss.backward()
# 每累积accum_steps批次更新权重并重置梯度
if (i + 1) % accum_steps == 0:
optimizer.step()
optimizer.zero_grad()
# 处理剩余的梯度,如果总批次不是accum_steps的整数倍
if (i + 1) % accum_steps != 0:
optimizer.step()
optimizer.zero_grad()
让我们理解同步和异步训练的基本区别:
同步训练 所有工作者在更新权重之前等待交换梯度。确保模型一致,但最慢的工作器会拖慢所有人。
- 梯度平均
- 动态批量大小
- 预测等待时间调度
异步训练 工作者在不等待的情况下更新权重。加快速度,但梯度可能是陈旧的。
- 使用陈旧梯度校正
- 动态调整学习率
- 维护模型版本控制以跟踪更新
到目前为止我们学到的内容,让我们总结成一个表格:
3、高级模型推理技术
当我们部署ML模型并有数百万人使用它们时,肯定需要一种高效的推理方法,以便所有用户都能轻松访问。
我们经常遇到资源不像我们希望的那样容易获得的情况。在本节中,我们将探讨各种技术和策略,帮助我们优化和有效推理。
3.1 高效的大规模推理
模型量化 通过减少其数字的精度来缩小模型并加速推理,例如从32位浮点数转换为8位整数。这意味着更小的模型和更快的计算,但要注意准确性可能会有所下降。
主要有两种类型:
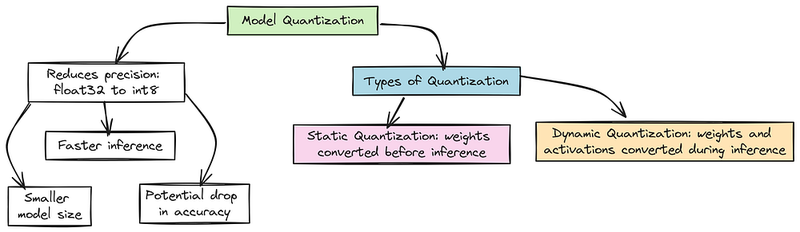
- 静态量化:在运行模型之前转换权重为低精度。
- 动态量化:在推理期间动态转换权重和激活,平衡速度和灵活性。
以下是使用PyTorch对ResNet18模型进行动态量化的示例:
# 使用ResNet18进行动态模型量化的示例
import torch
from torchvision.models import resnet18
# 加载预训练的ResNet18模型
model = resnet18(pretrained=True)
model.eval() # 设置为评估模式以进行推理
# 对Linear层应用动态量化以加快推理速度并减小模型大小
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear, torch.nn.Conv2d}, dtype=torch.qint8
)
# 打印量化的模型架构
print(quantized_model)
有两种常用的训练技术在节省磁盘空间、内存以及最重要的是成本方面发挥重要作用。

- 训练后量化:您在训练后对模型进行量化。它很快,但由于模型不知道它会使用较低精度,因此可能会导致更多的准确性损失。
- 量化感知训练(QAT):模型在训练期间考虑到量化,因此它会适应并在量化后通常保持更好的准确性。
以下是使用PyTorch对ResNet18模型进行QAT的示例:
import torch
from torchvision.models import resnet18
import torch.quantization
model = resnet18(pretrained=True)
model.train()
# 融合Conv、BatchNorm和ReLU层以提高量化效果
model = torch.quantization.fuse_modules(model, [['conv1', 'bn1', 'relu']])
# 设置QAT配置
model.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
# 准备模型进行QAT(就地)
torch.quantization.prepare_qat(model, inplace=True)
# ... 添加您的训练循环以微调模型 ...
# 训练后转换为量化版本
torch.quantization.convert(model, inplace=True)
print(model)
模型剪枝 通过去除不重要的部分来缩小模型——可以通过零化单个权重或切除整个神经元或通道。
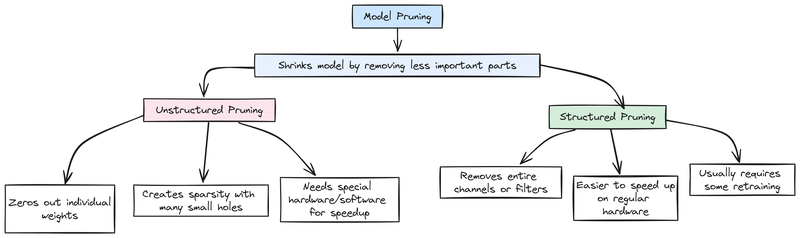
- 无结构剪两者都很重要,但有时提高其中一个可能会减缓另一个。让我们来分解一下如何在不涉及太多技术术语的情况下同时管理好两者。
在实时应用程序中,用户或系统不想等待太久。您希望您的模型能够快速给出答案。
- 修剪模型: 使用量化和剪枝(之前已介绍)等技术来缩小模型并提高其速度,同时保持准确性。
- 更智能地服务: 模型的部署方式很重要!在需要额外性能时使用GPU,或者使用工具如TorchServe来高效管理请求,这会带来巨大的差异。
吞吐量是指模型一次可以处理多少请求,在流量高峰期间这一点非常重要。
- 批量处理: 将多个传入请求组合在一起进行处理,就像用一辆巴士运送一群乘客而不是为每个人单独派一辆车一样。总体上更快,但批次需要一些时间来填满才能移动。
- 异步处理: 让系统在处理先前请求的同时接收新请求,就像在继续烹饪的同时接受新的订单一样。这样可以保持一切顺利进行。
平衡延迟和吞吐量意味着有时需要根据实时情况调整一次处理的请求数量,即批处理大小。
以下是一个简单的使用PyTorch实现的方法:
import torch
from queue import Queue
from threading import Thread
# 定义一个简单的用于推理的线性模型
model = torch.nn.Linear(10, 2)
model.eval() # 设置模型为评估模式
def inference_worker(input_queue):
while True:
# 等待从队列中获取一批输入
batch = input_queue.get()
if batch is None: # 检查退出信号
break
with torch.no_grad(): # 在推理时禁用梯度计算
output = model(batch) # 对输入批次运行推理
# (可选)根据需要处理输出
input_queue.task_done() # 标记任务已完成
# 创建一个最大容量为10的队列以保存输入批次
input_queue = Queue(maxsize=10)
# 启动一个线程来从队列中处理输入批次
worker = Thread(target=inference_worker, args=(input_queue,))
worker.start()
# 动态将批次放入队列中
for _ in range(100):
input_batch = torch.randn(5, 10) # 创建一个包含5个样本、每个样本有10个特征的批次
input_queue.put(input_batch) # 将批次添加到队列中进行处理
input_queue.put(None) # 向工作线程发送退出信号
worker.join() # 等待工作线程完成
到目前为止我们学到的东西...
这不仅仅关乎速度或容量,而是关于在保持快速响应的同时平稳处理大量负载,以保持用户满意。
3.2 边缘AI与移动部署
在智能手机和物联网设备等边缘设备上部署AI模型意味着在数据生成的地方运行AI。
这种设置减少了延迟,节省了网络带宽,并且由于数据不必离开设备,因此更加私密。
为了让AI在这些受限设备上表现良好,您需要专注于一些聪明的策略:
- 模型优化: 使用量化、剪枝和知识蒸馏等技术来缩小模型。较小的模型运行更快,更适合在性能较低的硬件上运行。
- 面向边缘的框架: 工具如TensorFlow Lite和PyTorch Mobile就是为了这个目的而构建的。它们帮助转换和优化您的模型,以便在边缘设备上高效运行。
import tensorflow as tf
# 将您的TensorFlow模型转换为TensorFlow Lite格式以进行边缘部署
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
with open('model.tflite', 'wb') as f:
f.write(tflite_model)
边缘设备通常对处理能力、内存和电池寿命有严格的限制。因此,您的AI模型需要精简且高效:
- 模型压缩: 使用剪枝或量化来缩小模型,以节省空间并加速推理。
- 节能算法: 选择或设计不会耗尽电池或过度占用处理器的算法。
- 面向边缘的架构: 使用MobileNet或EfficientNet等网络,这些网络专门设计为快速且轻量级,同时仍然保持准确。
4、性能分析与优化
在优化AI系统时,关键是要找出哪里变慢了——瓶颈,这样你就可以修复它们并提升性能。
4.1 诊断系统瓶颈
在这里有两个主要工具可以帮助:剖析和基准测试。
剖析是深入研究你的系统如何使用资源(如CPU、GPU和内存),以及代码的不同部分运行所需的时间。它就像有一张性能地图,突出显示你想改进的缓慢或沉重的部分。
- Python的cProfile: 一个方便内置工具,用来测量你的Python代码大部分时间花在哪里。
- NVIDIA Nsight Systems: 如果你使用NVIDIA GPU,这个工具可以追踪GPU性能,并帮助找到CUDA代码中的瓶颈。
基准测试着眼于更大的图景:你的整个系统的速度和效率如何,与标准或过去的版本相比。它设定一个基线,这样你就知道从哪里开始,并能衡量你的更改带来了多大影响。
- 建立基线: 在改变任何东西之前先基准测试当前系统。
- 比较: 检查你的系统与其他系统或行业基准的表现如何。
- 测量影响: 优化后再次基准测试,看看你的改进是否真的产生了效果。
瓶颈有不同的形式,如计算、内存或网络,每种都需要不同的解决方法。
计算瓶颈发生在处理器(CPU/GPU)无法跟上工作的时候。
解决方案:
- 使用并行计算:将工作分散到多个核心或GPU上以加快速度。
- 优化算法:简化计算或切换到更有效的方法以减轻负载。
内存瓶颈发生在系统无法快速移动数据或耗尽内存的时候。
解决方案:
- 缓存频繁使用的数据以避免缓慢的内存读取。
- 减少内存占用使用剪枝、量化或更轻量的数据结构。
- 示例: 如果模型太大而无法放入GPU内存,你可能需要这些技巧,因为你不能简单地增加更多RAM。
网络瓶颈出现在分布式系统中,数据需要在机器之间传输。
解决方案:
- 使用更好的数据序列化来缩小发送数据的大小。
- 切换到更高效的通信协议,以降低延迟并加速数据传输。
4.2 运营AI模型
密切关注系统健康状况和AI模型性能对于平稳、可靠的运营至关重要。良好的监控有助于及早发现问题,以免演变成更大的问题。以下是设置有效监控策略的一个简单方法:
可以使用的工具:

- Prometheus: 一个开源工具,收集和存储诸如CPU使用率、内存消耗、磁盘I/O和网络流量等指标。它非常适合跟踪AI基础设施的整体健康状况。
- Grafana: 一个强大的可视化工具,与Prometheus很好地配合使用,创建直观的仪表板。它有助于轻松发现系统数据中的异常和趋势。
模型性能监控 流行的选项包括:
- TensorBoard: 专为TensorFlow和PyTorch设计,TensorBoard允许您可视化训练和评估指标,如损失、准确率、权重分布,甚至模型架构。定期检查这些内容有助于了解模型的学习和表现情况。
- 自定义日志记录: 有时你需要跟踪TensorBoard不涵盖的应用程序特定指标。实现自己的日志记录系统可以让您捕获预测、错误或任何自定义的关键绩效指标,以进行更深入的分析。
因此,一些最佳的监控技术是:
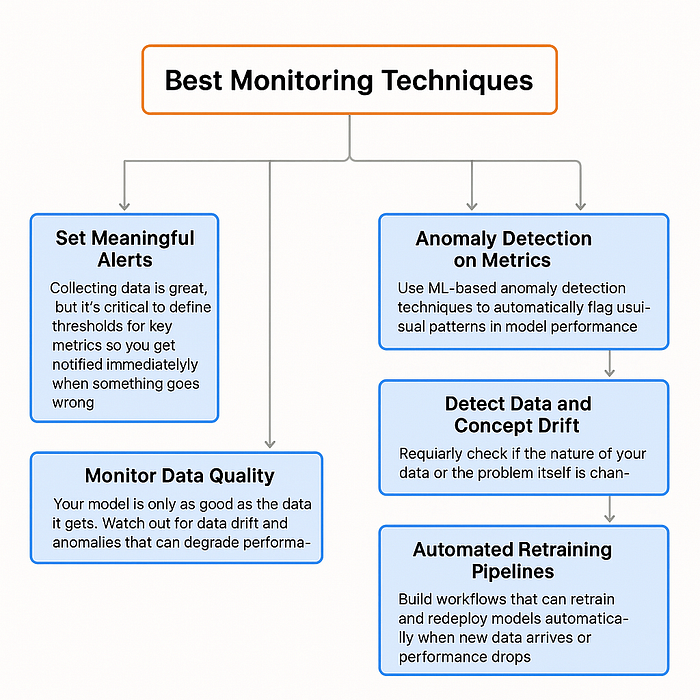
- 设置有意义的警报: 收集数据很棒,但定义关键指标的阈值至关重要,这样当出现问题时你会立即收到通知。警报帮助您快速采取行动,以免问题影响用户。
- 监控数据质量: 模型的表现取决于它接收到的数据。注意数据漂移(随时间变化的输入数据)和异常,这些都可能导致性能下降。例如,记录样本图像或数据批次可以帮助您早期检测到变化。
- 持续评估: 定期使用新鲜数据评估模型,以发现性能下降。自动触发重新训练或警报,当准确率或其他指标低于设定阈值时,确保模型保持有效性。
- 指标上的异常检测: 使用基于机器学习的异常检测技术,自动标记模型性能中的异常模式,这样您始终能够掌握潜在问题,而无需手动检查。
- 检测数据和概念漂移: 定期检查数据或问题本身是否发生变化。专用漂移检测工具可以提醒您这些变化,提示更新或重新训练模型。
- 自动重新训练管道: 构建工作流,当新数据到达或性能下降时,可以自动重新训练和部署模型。但要明智地设置严格的标准,以避免浪费资源在实际意义不大的小改进上。
4.3 调试AI系统:工具与方法
由于复杂的流程和模型,调试AI系统很棘手。使用这些工具和方法:

- PyTorch Autograd Profiler: 检查PyTorch模型的时间和内存使用情况。
- TensorFlow调试器(tfdbg): 检查张量值以发现错误,如NaN或形状错误。
- 交互式调试: 使用Jupyter笔记本进行实时数据和模型检查。
- 高级剖析: 工具如NVIDIA Nsight和PyTorch Profiler分析GPU使用情况和硬件瓶颈,以优化性能。
4.4 机器学习的CI/CD流水线
快速可靠地更新模型是AI项目的关键。CI/CD自动化测试、集成和部署,以保持模型平稳运行,减少人工干预。

能够快速测试和改进机器学习模型是构建成功AI系统的关键。通过使用CI/CD(持续集成和持续部署),我们可以自动化测试、模型更新和部署,从而最大限度地减少人工干预。这使得一切都运行得更加顺畅和可靠。
机器学习中的持续集成(CI)
CI意味着自动检查代码更改,以便及早发现问题。在机器学习中,它还包括检查数据、训练脚本和模型本身。
- 自动化测试: 设置测试以检查数据质量、模型训练和预测。使用单元测试来检查小部分,使用集成测试来检查完整管道。
- 版本控制: 使用工具如DVC来跟踪数据和模型的变化,就像对待代码一样。这有助于保持一致性,并在需要时轻松回滚。
机器学习中的持续部署(CD)
CD意味着自动将新模型投入生产,以便用户尽快获得最新改进。
- 模型服务: 工具如TensorFlow Serving或TorchServe有助于高效服务模型并管理版本。
- Docker: 使用Docker将模型及其所有依赖项打包在一起。这使得在任何地方运行模型变得容易。
- Jenkins + Kubernetes: 使用Jenkins自动化测试和部署模型的任务。结合Kubernetes来扩展和管理生产中的模型。
额外工具使其更好工作
- 实验跟踪: 工具如MLflow或Weights & Biases帮助跟踪实验、模型指标和结果。
- 环境管理: 使用工具如Conda或Pipenv来管理Python包,并与Docker结合使用,以确保开发和生产环境中的一致性。
- 模型验证: 设置自动化检查,确保每个模型在部署前达到性能标准(如准确率或精确度)。
5、结束语
我希望这篇指南能帮助你在AI工作中有所收获,无论你是开始新项目还是改进现有项目。AI的最佳状态是人们一起分享和学习。如果你有任何想法或项目,请随时分享!
原文链接:How to Design Large-Scale AI Systems
汇智网翻译整理,转载请标明出处
