如何训练你的LLM
塑造一个听起来智能的大型语言模型(LLM)助手,可以想象成一个迭代过程中的陶土雕塑。

塑造一个听起来智能的大型语言模型(LLM)助手,可以想象成一个迭代过程中的陶土雕塑。你从一块陶土开始,把它塑造成一个可操作的结构,然后开始修剪细节,直到你得到一个更接近最终产品的结果。你越接近最终产品,那些精细的修饰就越重要,区分了杰作和诡异谷的结果。
在你开始处理细节之前,你必须先在早期步骤中塑造陶土。同样地,你不能直接将一个没有预训练的LLM架构投入到偏好优化和推理中。需要有足够的基础让模型达到甚至最低的奖励,以朝着一个相对良好的方向移动。
这个“塑造”过程仍然是一个活跃的研究领域,我们还没有完全达到超级对齐、寻求真理和有意识的助手这一圣杯,但我们已经在这门技艺的理解上取得了巨大的进步。
Kimi 和 Deepseek 论文都向世界揭示了大量关于如何进行预训练以及添加监督微调和强化学习作为层来持续提高LLM有用性的宝贵信息。
参考,Deepseek V3 在 14.8万亿个标记 上进行了训练。这大约相当于 1.23 亿本平均长度的小说文本。为了提供一个规模感,Google 估计 在 2010 年时,人类总共写了 1.29 亿本书。
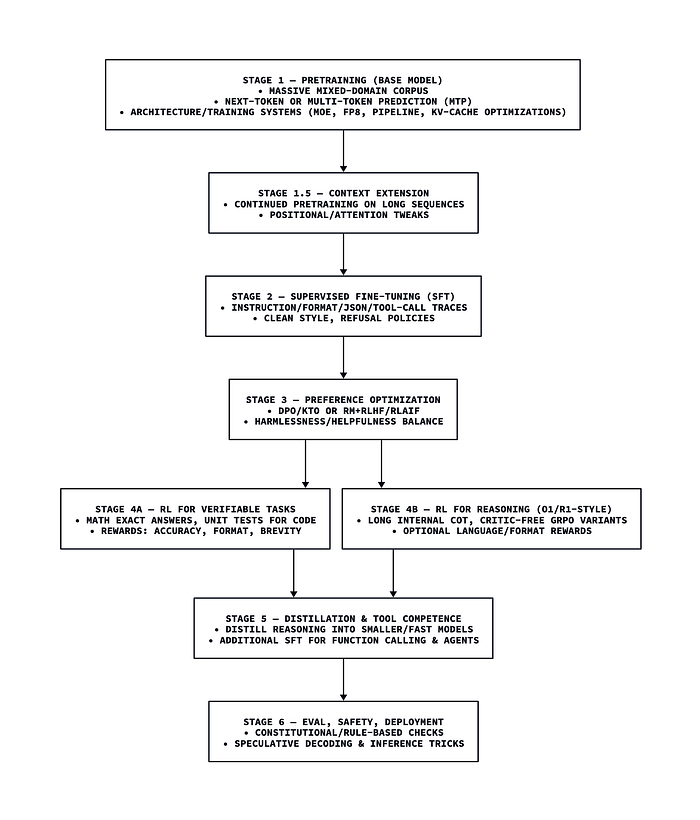
大型语言模型端到端训练的通用概述。并非所有阶段都适用于所有模型,但最全面的流程通常会遵循一个或多个预训练后的阶段和对齐步骤。
1、模型训练技术:LLM雕塑家的工具
为了获得链式思维(CoT)推理和工具使用等复杂的语言模型行为,LLM会在三个耦合循环中进行训练。
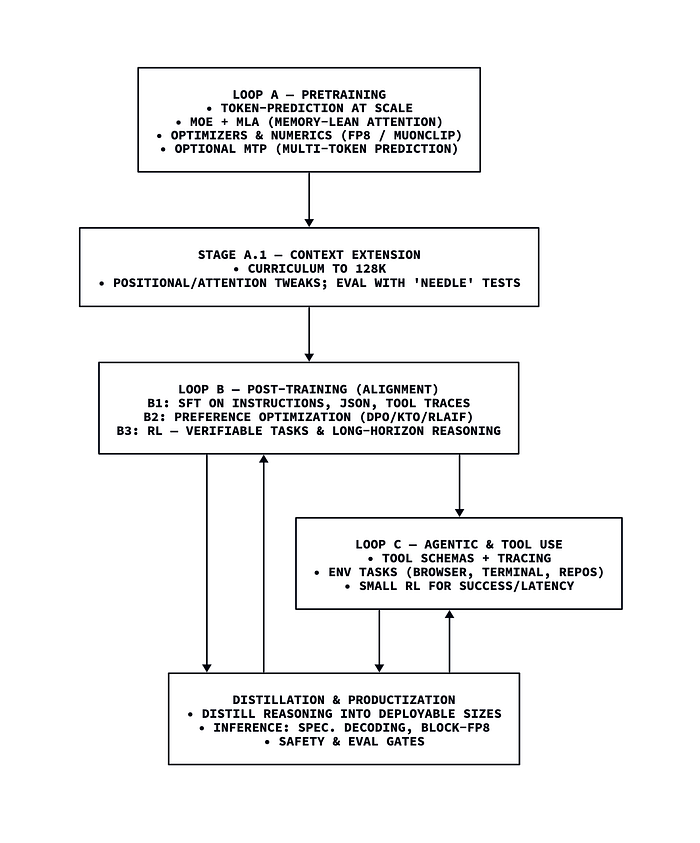
1.1 自监督预训练
就像你不能在陶土塑形之前就开始雕刻一样,你也不能在语言模型上获得复杂的推理行为,除非它们有一个对人类语言的工作模型。在你开始引导它们的文本进入对话式互动和推理之前,它们需要能够从某种数据分布中生成连贯的文本。
第一个循环是预训练阶段,通过大规模的自监督学习在混合领域数据上带来原始能力和一般先验知识。模型被喂食来自各种来源的大规模原始文本数据:代码、百科全书、教科书、网页等。通过在文本中创建空白并迫使模型学习如何填补这些空白,并学习人类语言的倾向来进行自监督学习。
现代堆栈依赖于架构和系统技巧:专家混合(MoE) 用于在不增加密集成本的情况下扩展容量,多头潜在注意力(MLA) 用于缩小注意力内存,FP8/MuonClip 用于稳定的高吞吐量数值计算,有时还有 多标记预测(MTP) 以密集目标并实现更快的推测解码。这可以看作是教模型“如何理解语言”,同时通过工程训练使其不会烧毁GPU或爆掉损失曲线。
1.2 预训练后微调
第二个循环是预训练后,它为基模型提供了可调节性和风格。团队通常从监督微调(SFT) 开始,使用指令、JSON格式和工具调用痕迹来教模型如何遵循指示与用户互动。没有微调,LLM只会无限地完成文本并重复其训练堆栈中的标记。我们需要将这种流引导到与用户的更简洁互动中,通过合成脚本般的聊天互动数据集来引导模型的标记生成朝向“指令”格式。这就是所谓的指令微调。
在模型被塑造成能够以对话方式响应之后,我们可以应用更细腻的强化学习(RL)技术,如直接偏好优化和组相对策略优化(GRPO),以塑造语气、安全性和对模式的遵守。这就是对齐过程的部分,我们开始塑造模型以生成人类认为有用的内容。
最后,我们可以应用特定的行为强化学习技术。一种这样的技术是具有可验证奖励的强化学习,用于数学/代码/格式,其中自动评分器根据答案是否正确给予模型清晰的奖励。另一种是针对链式思维(CoT)的推理导向强化学习(o1/R1风格),它推动文本中出现类似人类的思考模式和自我反思,以增强问题解决能力,通过更长的生成和测试时计算。
1.3 工具使用训练
就像通过强化学习指导来培养思考行为一样,工具使用是另一种生成模式,当模型被调整时会自然地出现。
为了让LLM生成正确的输出以使用系统集成,我们进行代理/工具循环,其中模型学习在世界上做事情。在这里,实验室扩大了高覆盖率的工具调用痕迹,并强制执行严格的模式,然后在沙盒环境中(浏览器、终端、仓库)进行训练,以弥合“知道”和“做”的差距。少量的联合RL提高了工具成功率并减少了延迟,但大部分可靠性仍然来自于优秀的痕迹和纪律性的模式。
最近,OpenAI 的 o3 类推理模型据报道成功地结合了工具调用训练循环和推理微调,使模型能够自发地在推理文本和工具使用之间交替生成。
开源领域有两个具体的例子可以给我们提供真实的见解。DeepSeek-V3 使用一个 671B参数 MoE,每标记约有 37B 激活参数,预训练在 14.8T 标记 上,加入 FP8 和 MTP 来稳定训练并加速推理。Kimi K2 扩展到一个 ~1.04T 参数 MoE,每标记约有 32B 激活参数,预训练在 15.5T 标记 上,并且 依赖于 MuonClip 以避免在万亿参数规模下出现损失峰值。然后它高度依赖于 代理/工具循环,包括大规模的工具使用合成和联合 RL。
实际上:预训练创建了一个对语言有稳定理解的模型,而预训练后则赋予了模型能够使用工具、推理和在聊天中扮演角色的行为属性。
1.4 微调 vs 提示
作为本节的最后一点:为什么我们应该微调,而不是仅仅向一个经过指令微调的模型提供完整的指令集并让它遵循提示?
原因在于指令微调只能走这么远。提示中的潜在指令空间非常大,模型需要平衡早期关于工具调用的指令与来自新数据源的后续信息。很快,上下文就会变得非常混乱,注意力也会受到压力。
如果没有一些关于如何以正确的方式理解和注意哪些信息的学习,指令微调的模型在代理工具使用场景中会迅速崩溃。虽然可以围绕非工具调用模型的限制进行工程设计,但通常更有效的方法是插入一个已经被奖励成功导航复杂指令遵循、推理和工具使用空间的模型。
2、塑造之手:数据看起来是什么样的?
LLM训练过程中最关键的部分当然是数据。在获取足够的语言建模数据背后有一个复杂的流程;存储它、引用和注释它,以及将其分块为固定长度序列以供模型使用。
在我从事生物信息学工作的时间里,我发现自己将这个过程与DNA测序有机械上的相似之处。要让DNA达到可以读取的程度,有一个漫长而敏感的预处理协议,一旦有了溶液在测序仪中,测序仪对序列长度和质量有特定的要求才能实际读取数据。
对于LLM来说,这有些类似。为了高效,我们需要能够将整个文本语料库分块,并在训练期间将经过质量控制的、带有注释的固定长度输入给模型,以便能够利用大规模的并行处理。
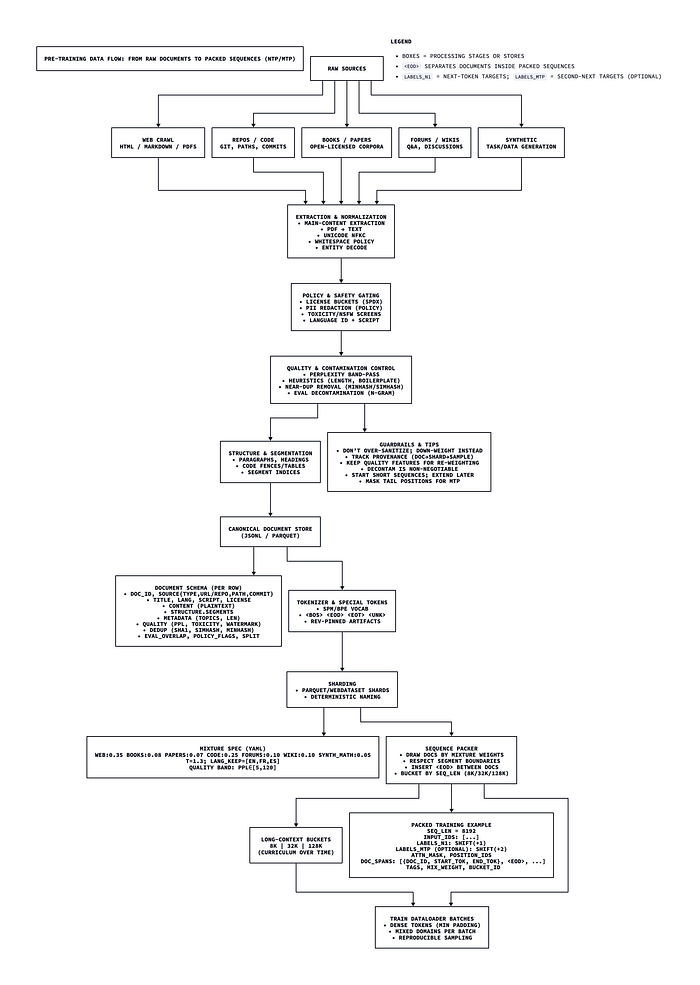
从“原始来源”中找到的各种格式的数据,一直到可以轻松加载到Python DataLoader中的固定长度序列的端到端数据处理路径。
我将在另一篇文章中详细介绍这个漫长的流程。在本文范围内,我将突出一些在进行预训练之前所需的的关键数据处理阶段:
- 数据来源:编写爬虫,购买许可证,访问公共文本数据包。数据不会来自一个单一的语料库,它很可能分散在许多不同的地方。数据需要作为一个时间快照捕获,在预训练开始后,模型只能通过工具使用和上下文工程来访问新信息。
- 提取、标准化和QA:文本需要尽可能以高质量的格式提取出来。这是防止“垃圾进,垃圾出”的过滤器。通常会有各种自动化算法来从PDF、HTML网站、GitHub代码和其他来源中提取文本,并确保文本正文不受噪声污染。不可能完全无噪声,但大多数数据应该是逻辑和合理的,使模型能够在自监督学习下达到收敛(稳定训练)。
- 注释和结构化:使用自动化算法遍历清理后的文本样本,进行注释和存储。这通常涉及添加诸如段落框架、文档长度、模式注释(markdown、javascript、plain text、HTML)和其他在训练期间有用的标签,这些标签可以为训练团队提供有价值的汇总统计数据以进行故障排除。
- 分块、分片和填充:文本内容随后会被“切碎”成带有特殊标记的块,这些标记表示文档的结束、文件的结束和其他注释信息,被标记为数字ID,并填充以确保每个序列长度相同。一旦你有相同长度的序列,就更容易将它们对齐成组,并一次将许多序列输入到模型训练循环中,并在大规模上并行化训练过程。
示例文档模式:
{
"doc_id": "01J2Y2G2F6X9S7J3SYZ3QW6W0N", // ULID/UUID
"source": {
"type": "web|book|paper|code|forum|wiki|synthetic",
"url": "https://example.com/post", // for web
"repo": "github.com/org/repo", // for code
"commit": "0f3c1a...", // for code
"path": "src/utils/math.py" // for code
},
"title": "A Gentle Intro to FFT",
"lang": "en", // ISO 639-1
"script": "Latn", // ISO 15924
"license": "CC-BY-4.0", // SPDX id or policy bucket
"created_at": "2023-04-12T09:21:37Z",
"collected_at": "2025-07-25T14:03:11Z",
"content": "Plaintext body with paragraphs...\n\n## Section\nText continues...",
"structure": {
"format": "markdown|plaintext|html|latex|rst",
"segments": [
{"start_char":0,"end_char":128,"type":"paragraph"},
{"start_char":129,"end_char":180,"type":"heading","level":2},
{"start_char":181,"end_char":420,"type":"code","lang_hint":"python"}
]
},
"metadata": {
"domain": "example.com",
"topics": ["signal_processing","math"],
"reading_level": 11.2,
"length_chars": 4231,
"length_tokens_est": 950
},
"quality": {
"ppl_small_lm": 28.7, // perplexity filter signal
"toxicity": 0.004, // [0,1]
"pii": {"email":1,"phone":0,"ssn":0}, // counts
"watermark_prob": 0.01 // LLM-written detector
},
"dedup": {
"raw_sha1": "0e5b4...8f",
"text_sha1": "a1c2d...9a",
"simhash": "9b7a3f12",
"minhash": [121, 9981, 733, 4211, 5901] // 5× 64-bit or more
},
"policy_flags": {
"nsfw": false,
"copyright_sensitive": false,
"allowed_for_training": true
},
"eval_overlap": {
"mmlu": 0.0, "gsm8k": 0.0, "humaneval": 0.0 // n-gram/regex decontamination
},
"split": "train|val|test"
}
示例打包和填充模式:
{
"sample_id": "01J2Y3AZ7X12P5...",
"seq_len": 8192,
"tokenizer": "sentencepiece_v5_en_32k",
"input_ids": [1017, 42, 1337, "..."],
"labels_n1": [42, 1337, 9001, "..."], // next-token labels
"labels_mtp": { // optional for MTP
"depth": 2,
"n2": [1337, 9001, 7, "..."] // second-next token labels
},
"attn_mask": "...",
"position_ids": "...",
"doc_spans": [
{"doc_id":"01J...W0N","start_tok":0,"end_tok":2500},
{"separator":"<eod>"},
{"doc_id":"01J...9KX","start_tok":100,"end_tok":5600},
{"separator":"<eod>"},
{"doc_id":"01J...2Q3","start_tok":0,"end_tok":92}
],
"tags": ["web","math","code_block_present"],
"mix_weight": 0.85, // used by sampler
"long_context_bucket": 0 // e.g., 0:8k, 1:32k, 2:128k
}
3、预训练:塑造粘土
我们将研究两个通过公开预印本共享的预训练案例研究,来自 Deepseek 和 Kimi。
3.1 DeepSeek-V3
DeepSeek V3 是一个 6710亿 参数的 MoE 模型,每标记约有 370亿 激活参数。它使用 MLA 注意力来缩小 KV 并改善内存/延迟,无辅助损失 的负载平衡,以及 FP8 混合精度在极端规模下验证。
它在 14.8万亿个标记 上进行了训练;工程协同设计带来了总 端到端成本 ≈ 2.788M H800-GPU 小时,涵盖预训练、上下文扩展和预训练后。
我之前在另一篇文章 这里 中用直观的视角介绍了完整的架构。
3.2 Kimi K2
Kimi K2 是一个 1.04万亿 参数的 MoE,每标记约有 320亿 激活参数。它还利用 MLA 作为一种更节省内存的注意力机制,并拥有 384 个专家,每标记选择 8 个。它支持一个 128K 标记的上下文窗口。
Kimi K2 模型在 15.5 万亿个标记 上进行了预训练,使用 MuonClip(Muon + QK-Clip)来消除在万亿参数 MoE 规模下的损失峰值。它将令牌效率作为首要的扩展系数。
与 Deepseek V3 不同,该模型的预训练后明确是 代理:大规模工具使用合成和 联合 RL 对抗真实和模拟环境。
4、上下文扩展:管理感官过载
我之前写过 关于旋转位置编码 (RoPE) 在 DeepSeek V3 架构的注意力机制中是如何用来传达标记位置的相对信息的。这些位置编码是模型区分输入文本中相同标记的重要部分。
存在一种训练机制可以暴露相对距离,这意味着如果输入文本的长度发生变化,那么模型就无法可靠地关注超过其最大训练注意力的文本。
这个问题在训练过程中通过 上下文扩展 来处理,可以看作是一种“训练课程”,其中模型从简单开始,最初在 8000 个标记的短序列上学习,然后被重新校准以处理逐渐更大的 16000 个标记、32000 个标记和更大的块。
前沿模型通常通过分阶段的课程(从短到长)扩展到 128K 或更长,进行位置/注意力调整和“针”式压力测试以避免在长序列上的回归。DeepSeek V3 技术论文报告了从 8k 到 32k 再到 128k 的两阶段扩展。
然而,Kimi K2 是一个反例:截至 2025 年 7 月,Kimi K2 技术论文直接导出 128K,管理在万亿参数规模下的训练,使用 MLA、长序列 RoPE 和 MuonClip。这是一个在一年内实现的训练创新,可能淘汰了之前的长上下文预训练前沿范式。
5、预训练后:雕刻细节
在“预训练后”阶段,模型的行为形成。在预训练之前,模型只是一个文本补全工具,可以自回归地生成文本并预测下一个标记。在预训练后,我们可以尝试通过监督和强化学习技术来强制某些行为,这些行为不在训练数据中。这个阶段是指令遵循、聊天角色扮演、推理和工具使用出现的地方。
6、监督微调(SFT)
SFT 只是 教师强制的下一个标记预测 在精选的对话和演示中。"奖励"是隐式的:您最小化 交叉熵 在您希望模型发出的标记上。这意味着您最奖励模型生成与示例数据相同的文本。
您通过以下方式控制模型学习什么:
- 哪些标记被标记(按角色/字段的损失掩码)。
- 某些模式出现的频率(混合权重,课程)。
- 结构被强制执行的严格程度(数据构建期间的验证器)。
具体来说,您将对话序列化为标记,并仅对您想要模仿的部分计算损失。这通常是助理的回复和(对于工具)函数调用对象,而不是用户文本或原始工具输出。
通常我们从 指令微调 开始,这是 SFT 的一部分,我们塑造模型以表现得像一个助手并遵循用户指令和系统提示。用于指令微调的 SFT 数据输入如下:
{
"id": "sft-0001",
"system": "You are a concise assistant.",
"messages": [
{"role": "user", "content": "Explain dropout in one paragraph."},
{"role": "assistant", "content": "Dropout randomly zeros units ..."}
],
"loss_mask": {
"assistant": true, // label these tokens
"user": false // don't compute loss here
},
"tags": ["instruction", "science.explain", "concise"]
}
在训练过程中,结构化的数据将被序列化为一个单独的标记序列,并对用户标记进行掩码,以使模型塑造自己以符合对话中助手的行为。
单字符串对话的 ChatML 样式模板如下:
<BOS>
<|system|>
You are a concise assistant.
<|eot|>
<|user|>
Explain dropout in one paragraph.
<|eot|>
<|assistant|>
Dropout randomly masks units ...
<|eot|>
请注意,这个阶段被称为 监督 微调的原因是我们显式地提供未遮罩的标记作为标签,并要求助手生成精确的这些标记以实现目标(最小化未遮罩标记生成的损失函数)。
7、偏好优化(廉价、稳定控制)
直接偏好优化(DPO)是一种基于偏好的预训练后方法,它从比较中学习,而不是黄金答案。
对于每个提示,您提供一个 选定 的响应和一个 拒绝 的响应。模型被训练使得选定的响应在策略下比拒绝的响应更有可能,相对于固定的 参考策略(通常是 SFT 检查点)。这里没有提供评论者/奖励模型,也没有 PPO 循环;只有一个稳定、离线的目标。
与其教 说什么(SFT),DPO 教的是 哪两个可能的东西更好(语气、安全、简洁性、格式准确性)。它便宜、稳健且易于迭代。
由于稳定性、灵活性和降低成本,许多堆栈现在默认使用 DPO(可能在二元替代方案 KTO 之前或代替)全强化学习与人工反馈(RLHF)。
DPO 的数据输入通常如下所示:
{
"id": "dpo-00421",
"prompt": "<BOS>\n<|system|>\nYou are a concise assistant.\n<|eot|>\n<|user|>\nExplain dropout in one paragraph.\n<|eot|>\n",
"chosen": "<|assistant|>\nDropout randomly masks units ... (clear, concise)\n<|eot|>\n",
"rejected": "<|assistant|>\nDropout is a technique that was first... (rambling / off-spec)\n<|eot|>\n",
"meta": {"reason": "conciseness/style", "source": "human_label"}
}
我们可以看到,由于 提示,我们正在建立在指令微调之上,这是一个 ChatML 序列化的输入,模型应该在此时理解。
下面的 Python 虚拟代码更详细地分解了 DPO 如何应用:
import torch
import torch.nn.functional as F
# This is pseudocode, but require that these exist for a real implementation:
# - dpo_loader: yields batches with fields .prompt_ids, .chosen_ids, .rejected_ids, .assistant_mask
# - policy: trainable model (θ)
# - reference_policy: frozen reference model (θ_ref), typically the SFT checkpoint
# - seq_logprob(model, prompt_ids, response_ids, mask, length_normalize=True): returns
# the sequence log-prob over ONLY the masked assistant tokens (optionally length-normalized)
beta = 0.1 # strength of preference separation
for batch in dpo_loader:
prompt_ids = batch.prompt_ids # [B, T_prompt]
chosen_ids = batch.chosen_ids # [B, T_answer]
rejected_ids = batch.rejected_ids # [B, T_answer]
assistant_mask = batch.assistant_mask # [B, T_answer] bool (loss only on assistant tokens)
# --- Sequence log-probs under the current policy (θ) ---
logp_chosen = seq_logprob(policy, prompt_ids, chosen_ids, mask=assistant_mask)
logp_rejected = seq_logprob(policy, prompt_ids, rejected_ids, mask=assistant_mask)
# --- Sequence log-probs under the frozen reference (θ_ref) ---
logp0_chosen = seq_logprob(reference_policy, prompt_ids, chosen_ids, mask=assistant_mask).detach()
logp0_rejected = seq_logprob(reference_policy, prompt_ids, rejected_ids, mask=assistant_mask).detach()
# --- DPO margin: encourage policy to widen the chosen-vs-rejected gap relative to the reference ---
margin_current = (logp_chosen - logp_rejected) # under θ
margin_reference = (logp0_chosen - logp0_rejected) # under θ_ref (no grad)
z = beta * (margin_current - margin_reference)
# Numerically stable: -log σ(z) == BCEWithLogits(z, target=1)
loss = F.binary_cross_entropy_with_logits(z, torch.ones_like(z))
# Standard optimizer step
policy.zero_grad(set_to_none=True)
loss.backward()
torch.nn.utils.clip_grad_norm_(policy.parameters(), max_norm=1.0) # optional but helpful
for p in policy.parameters():
if p.grad is not None and torch.isnan(p.grad).any():
raise RuntimeError("NaN in gradients")
policy.optimizer.step()
对于每个样本,正在训练的模型将被最大化奖励生成文本,这些文本:
- 完全与所选文本相同
- 与拒绝文本完全不同
- 与我们从其开始的参考模型生成的文本在字符上不太不同(指令微调的 SFT 检查点)
随着时间的推移,给定足够多的例子,新的模型检查点将开始根据用户偏好行为,而不是仅仅遵循监督训练数据中的特定示例,同时保留从指令微调中学到的核心行为。
通常,包含用户输入对于塑造一个在开放世界中对用户感觉有用的助手至关重要,因为指令微调数据集通常只是一组由团队内部合成或从开源研究努力中获取的预设、精心挑选的对话。
8、强化学习
强化学习(RL)在现代堆栈中出现在两个地方:可验证的端点(数学/代码/格式)中,您可以自动评分输出,以及长程推理(o系列/R1风格)。为了效率,两者通常使用 组相对、无评判者 的更新,来自 组相对策略优化(GRPO) 家族,而不是完整的近端策略优化(PPO)+价值函数循环。
8.1 组相对策略优化
GRPO 是一种程序,允许我们有效地评估模型的最佳性能,而无需提供特定的标签。
与 PPO 不同,我们不需要一个单独的评判者模型来评估模型的表现。我们反而让模型生成一组候选答案,这些答案通过自动检查进行评分,然后奖励得分最高的答案。这些检查通常是运行在生成文本上的函数,检查诸如存在精确答案、通过单元测试、有效的数据模式,有时还包括负面奖励,如对长度或延迟的惩罚。
诀窍是分数在组内是相对的,因此你可以从样本本身中“免费”获得低方差的优势信号。你不需要第二个 LLM 进行计算,因此相对于 PPO 显著降低了计算成本。
一个类似于 PPO 的剪裁步骤保持更新在信任区域内,序列级、长度归一化的对数概率确保整个生成被奖励,而不仅仅是最终的标记。结果是一个简单、稳定的循环,可以扩展:增加组大小以增强信号,模型稳步转向一致通过你的评分器的输出。
下面的 Python 虚拟代码有助于更具体地理解发生了什么:
# Hyperparams
group_size = 8 # K
clip_epsilon = 0.2
temperature = 0.8
top_p = 0.95
for prompt in prompt_batch:
# 1) Propose K candidate completions from the *old* policy
candidates = sample_candidates(old_policy, prompt, group_size,
temperature=temperature, top_p=top_p)
# 2) Score each candidate with your programmatic reward function
rewards = [compute_reward(prompt, completion) for completion in candidates]
# 3) Group-relative advantages (z-score within the K samples)
advantages = zscore(rewards) # (r_i - mean) / (std + eps)
# 4) Policy-gradient update with PPO-style clipping (sequence-level, length-normalized)
for completion, advantage in zip(candidates, advantages):
logprob_new = sequence_logprob(policy, prompt, completion,
mask="assistant", length_normalize=True)
logprob_old = sequence_logprob(old_policy, prompt, completion,
mask="assistant", length_normalize=True).detach()
likelihood_ratio = torch.exp(logprob_new - logprob_old)
loss += -torch.clamp(likelihood_ratio, 1 - clip_epsilon, 1 + clip_epsilon) * advantage
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 5) Trust-region bookkeeping (standard PPO-style: refresh the old policy)
old_policy.load_state_dict(policy.state_dict())
8.2 具有可验证奖励的强化学习
当你能编写一个程序自动决定答案是否“好”时,你可以廉价且安全地扩展 RL。通常,一个拥有数千亿参数的前沿模型需要数百万个例子,数亿次尝试(“候选轨迹”),以及数万亿个标记的生成才能显著改变模型的行为。这意味着不可能让人类眼睛看到模型经历的每个情节/轨迹以获得奖励。“可验证奖励”是指有一些自动方式确定模型模拟的任务是否正确完成。
与 SFT/DPO(完全离线)不同,RL 任务是 提示加上评分器。每个例子将有一个提示,有一个任务要完成,一个问题要解决,或者某种其他类型的完成请求,其结果可以编程验证。
对于代码,这可以是编写一个通过单元测试、linting 和其他类型的程序检查的函数。对于数学,这可以是全答案中特定表达式的精确匹配,例如方程式、引理和证明解释。
最小 JSON 的样本用于 数学 任务和 代码 任务如下:
数学
{
"id": "rl-math-0007",
"prompt": "<BOS>\n<|system|>Answer with just the number.<|eot|>\n<|user|>What is 37*91?<|eot|>\n",
"rewarders": [
{"type": "exact_answer", "target": "3367"},
{"type": "format_regex", "pattern": "^[0-9]+$"},
{"type": "length_penalty", "alpha": 0.001}
]
}
编码
{
"id": "rl-code-1031",
"prompt": "<BOS>\n<|system|>Write a Python function solve() that reads stdin and prints the answer.<|eot|>\n<|user|>Given N, output the sum 1..N.<|eot|>\n",
"rewarders": [
{"type": "unit_tests", "tests": ["tests/sum_to_n_*.txt"], "timeout_ms": 2000},
{"type": "runtime_penalty", "beta_ms": 0.0005},
{"type": "format_regex", "pattern": "def solve\\("}
],
"sandbox": {"image": "py3.11", "mem_mb": 512}
}
rewarders 是用于对生成文本进行评估的程序,以确定给予模型的奖励量。这些程序应提供高奖励,如果结果与人类期望一致,并惩罚不符合预期的结果。
注意: 对模型 对齐 的研究特别审查了奖励者和预期行为之间的匹配。由于可能的生成数量很多,实现真正的对齐往往很困难,因为许多生成可能会“黑客”奖励者并获得高奖励,而实际上并不符合人类期望。 当模型记住一个方程而不正确展示工作时,或者编写一个刚好通过单元测试但因缺乏常识条件而在生产中脆弱的功能时,会出现这种情况的例子。
8.3 链式思维推理 RL(o-series / R1-style)。
为了优化最终正确性(以及轻度格式约束)在长期问题上,我们需要诱导模型的基本行为进行更深层次的内部计算。这是通过让LLM在困难问题上学习一种结构化的思维方式来实现的,而奖励只在最终正确性上给予。
推理微调是可验证奖励RL的一个子集,你不会为特定的步骤活动提供奖励,而是只提供正确性信号。目标是旅程到最终奖励必须完全学习,我们在这一阶段的教学中“去掉了训练轮子”。
两种常见的补充:
- 语言/格式奖励。 例如,“用英语回答;最后一行是
Final Answer: ...”。 - 过程塑造(可选)。 对于通过中间检查(子目标、无工具推导)的小奖励,但在推理时不透露逐步解决方案。
DeepSeek 的 R1 表明,纯推理 RL 从强大的预训练基础(没有 SFT 冷启动)可以激发长期推理。他们后来通过一个小的 SFT 传递和另一个 RL 轮次清理了推理 RL。
V3 然后 将 R1 的推理 回传到它的聊天模型中。OpenAI 的 o1 系列同样以大规模 RL 为中心进行隐藏的链式思维。
使用 GRPO 的 CoT 训练样本如下:
{
"id": "rl-reason-2203",
"prompt": "<BOS>\n<|system|>Provide only the final numeric answer after thinking.\n<|eot|>\n<|user|>If f(x)=..., compute ...<|eot|>\n",
"rewarders": [
{"type":"equality_modulo","target":"(2*sqrt(3))/5"},
{"type":"format_regex","pattern":"^Final Answer: "},
{"type":"language","lang":"en", "gamma": 0.05}
],
"sampling": {"K": 8, "temp": 0.9}
}
我们可以看到,这个模式与可验证奖励的模式非常相似,不过我们增加了难度,要求模型通过使用内部逻辑自行到达最终答案。
在可验证奖励中,模型很容易直接生成答案而不思考,但推理训练的目标是注入一组特殊的、非标准的问题,需要长时间的思考要求。结果是,思维链独白成为从训练过程中涌现出来的。LLM从未被明确教导如何生成思维独白,但它们需要这样做以在这些任务上获得奖励。
这些任务需要比可验证奖励样本更仔细地策划,并且预期每个样本的模型生成的标记数量更多。
注意: 你可能已经注意到这里推理导向的 RL 和 RL 与可验证奖励之间有很多相似之处。有一个称为超对齐的领域,涉及“不可验证”的奖励,我们试图让 LLM 生成我们没有简单解决方案的答案。 更具体地说,它涉及在奖励者不再是透明函数且容易评估的情况下,将模型与人类期望的行为和安全性对齐。最终,这超出了本文的范围,但这是一个非常有趣的话题,值得进一步阅读,因为它处于后训练研究的前沿。
9、让 LLM 与现实世界互动:工具使用
大多数“工具使用对齐”发生在 RL 之前:你教模型模式和痕迹,然后用强化学习打磨边缘。
我们首先需要在 SFT 中教工具使用直觉,通过添加要求 LLM 生成特定工具使用模式(通常是 XML 或 JSON)的样本,然后在对话中添加一个“工具”角色以捕捉来自工具的真实世界反馈。
一般来说,我们要求模型生成特定的结构化模式以与程序、集成或代码在其环境中(“工具”)进行交互,并期望这种行为推广到各种工具和各种模式。指令微调应允许模型在特定工具和模式周围的一般用户提示上进行泛化,这些模式应遵循特定业务用例的特定规则。
一个外汇汇率查询的示例可能如下所示:
{
"id": "sft-tool-0219",
"system": "You can call tools. Prefer JSON answers.",
"tools": [{"name":"fx.lookup","schema":"fx.lookup.input_schema"}],
"messages": [
{"role":"user","content":"What's the EUR→CAD rate right now?"},
{"role":"assistant","tool_call":{"name":"fx.lookup","arguments":{"base":"EUR","quote":"CAD"}}},
{"role":"tool","name":"fx.lookup","content":{"rate":1.47,"timestamp":"2025-08-09T10:22:01Z"}},
{"role":"assistant","content":"{\"pair\":\"EUR/CAD\",\"rate\":1.47}"}
],
"loss_mask": {
"assistant.tool_call": true, // learn name+args JSON
"assistant.text": true, // learn final summary/JSON
"user": false,
"tool.content": false // don't memorize raw tool output
}
}
这将被序列化为以下形式,模型必须精确学习完成助理消息:
<BOS>
<|system|> You can call tools. Prefer JSON answers. <|eot|>
<|user|> What's the EUR→CAD rate right now? <|eot|>
<|assistant|><|tool_call|>{"name":"fx.lookup","arguments":{"base":"EUR","quote":"CAD"}}<|eot|>
<|tool|><|fx.lookup|>{"rate":1.47,"timestamp":"2025-08-09T10:22:01Z"}<|eot|>
<|assistant|>{"pair":"EUR/CAD","rate":1.47}<|eot|>
然后,我们可以在沙盒中使用 GRPO 强化学习来润色可验证奖励:
{
"id": "rl-tool-0817",
"prompt": "<BOS>\n<|system|>Use tools only if needed. Respond in JSON.\n<|eot|>\n<|user|>What's the current EUR→USD rate?\n<|eot|>\n",
"tools": ["fx.lookup"],
"environment": {
"sandbox": "http",
"rate_limits": {"fx.lookup": 5},
"secrets_policy": "none_leak"
},
"rewarders": [
{"type":"tool_success", "name":"fx.lookup", "checker":"value_in_range", "range":[1.3,1.7], "weight":1.0},
{"type":"schema_valid", "target":"assistant_json", "weight":0.2},
{"type":"latency_penalty", "beta_ms":0.0003},
{"type":"no_op_penalty", "delta":0.1}, // punish unnecessary calls
{"type":"arg_semantics", "rule":"base!=quote", "weight":0.2}
],
"limits": { "max_calls": 2, "max_tokens": 512 }
}
强化学习中最棘手的部分是确保真实世界工具使用示例有清晰、可验证的奖励。这并不总是可能的,我们可以看到奖励者的数量现在已经增加,以“限制”模型到特定的行为,这些行为与人类在真实环境中集成模型时的期望相一致。
问题是,在现实世界的复杂性中,黑客奖励的方式非常多:通常比合法完成路径的数量多几个数量级。这往往是用户会见证的一种“角色扮演”行为,其中模型学会了某种非真实的路径来实现奖励,而没有准确表达核心逻辑和环境约束。
这带我们到了后训练的前沿,那里的事情模糊不清,仍在摸索中。在我看来,人工智能能力的下一次进化不会来自更多的计算或预训练规模,而是来自对后训练过程的持续改进,以防止奖励黑客并缩小模型找到真正奖励的可能轨迹。Kimi K2 是专门设计为一个代理模型,而不是仅限于聊天的模型。其内部是一个1.04T参数的MoE(专家混合模型),每个token有约32B活跃参数和MLA;该架构利用稀疏性来保持活跃FLOPs在合理范围内,同时扩展总的专家池。他们将总专家数量增加到384(k=8活跃),并将注意力头减半至64,与V3相比,这种权衡在保持吞吐量的同时,通过稀疏性扩展定律改善了验证损失。上下文长度为128K。
K2 引入了 MuonClip:Muon 加上 QK-Clip 机制,该机制重新缩放查询/键投影以防止注意力对数溢出,使他们能够在15.5T个token的预训练过程中不会出现损失峰值。如果你曾经看过因为少数头部爆炸而导致万亿级运行波动的情况,这就是一个实用的解决方案,在保留 Muon 的 token 效率的同时保持训练的平滑性。
后训练的重点是大规模使用工具。首先,K2 投资于一个大型的合成/真实代理数据管道,生成工具规范、多轮轨迹和基于评分标准的评估;然后应用一种联合强化学习(RL)方案,将可验证奖励(调用是否成功?JSON是否有效?)与自我批评评分标准结合起来,塑造超出静态轨迹所能教授的行为。
他们甚至发布了一个函数调用的token模板,并描述了一个**“强制执行者”受限解码器**,它保证在生成时调用符合声明的模式;这对任何曾与脆弱的函数调用格式作斗争的人来说都非常有用。
最后,K2 以产品形式发布。开放权重检查点(基础版和指令版)以block-FP8格式发布,并提供了vLLM、SGLang 和 TensorRT-LLM的部署示例,缩短了团队想要评估或在生产环境中运行它的“hello world”路径。如果你的堆栈已经支持 OpenAI/Anthropic 风格的 API,他们的仓库说明了兼容性细节和温度映射。
10、一页式视觉摘要
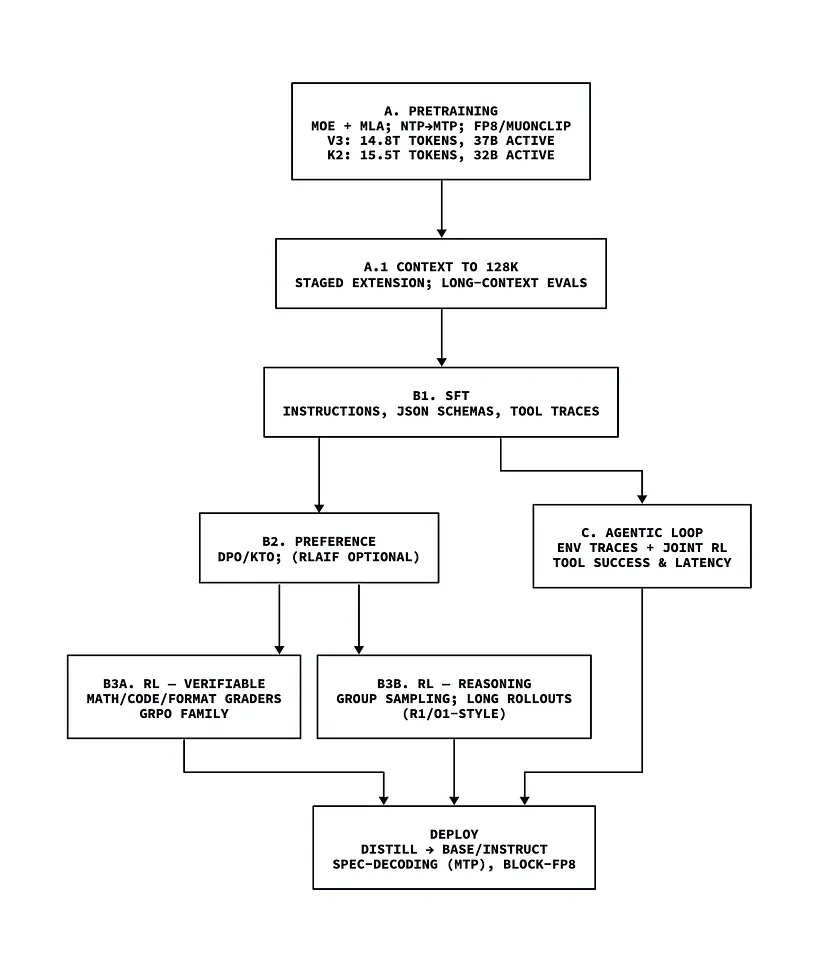
11、结束语
如果你把大语言模型(LLM)看作一件雕塑,预训练塑造了基本形状,而后训练则雕刻细节并赋予其个性。构建LLM是一项艰巨的任务:它需要丰富的资源、数据访问、计算能力和人力劳动时间。
总结从开始到结束训练LLM的旅程:
- 从来源中收集多样化数据:网站、代码、百科全书、书籍
- 进行质量检查和预处理,将其组装成带注释的片段
- 在预训练期间通过自回归的自监督学习赋予语言建模能力
- 在SFT(监督微调)期间进行指令调整,以实现聊天和工具调用行为
- 使用强化学习和奖励函数来提高在可验证奖励(如数学和编码)方面的性能
- 通过强调最终结果的推理导向强化学习,推动推理行为和高级工具使用
当这些步骤循环进行,并通过蒸馏改进基础模型时,就构成了LLM行为持续改进和优化的基础。
尽管这个过程复杂且细致,但它也有其不足之处:
- 在大规模情况下,“奖励黑客”现象很普遍,很难稳健地监督数百万个例子。我们依赖可验证奖励的稳健性来塑造更复杂的行为,但这忽略了大量现实中难以量化奖励的任务,而人类期望AI助手能够很好地完成这些任务。
- 对于长距离任务的最终完成的强调并不一定要求模型以逻辑一致的方式进行推理。一般来说,我们会看到这种模式,但我们发现CoT推理可能会崩溃,并且无法推广到分布外的任务,如此处和此处所讨论的那样。通常,推理可能陷入循环,或者产生逻辑流程不一致的思考过程。它们可能最终得出正确的结论,但原因错误,这在大规模所有训练回合中都难以评估。
- 为了推动人类知识的前沿,我们需要一种方法来为新发现和推理生成“不可验证”的奖励。在数百个百万次轨迹中为数百万个例子这样做,如果没有方法上的重大改进,将是相当困难的。这是超级对齐研究的一个活跃且持续发展的领域。
人类在智能机器的发展方面已经走了很远。几年前,拥有一个可以处理人类文本输入全部多样性的聊天机器人是难以想象的。我们面前的这段旅程是深入挑战的任务,即在众多次优代理模型中找到真正的对齐。
今天让AI用户感到沮丧的行为是缺乏真正意图和追求真相的行为,而勤奋的人类通常会表现出这些行为。真正激励模型深入挖掘问题的根源,并用无可辩驳的证据完全验证修复方案,是一个非常具有挑战性的任务,很难定义一个可扩展的奖励计划。
令人兴奋的是,我们现在有了具有丰富复杂性的架构,可以建模多模型输入和高一致性多语言文本。这表明我们已经达到了使奇迹发生的规模,但剩余的工作将需要我们继续在人类大脑中穿针引线,并以极其巧妙的方式创新,逐步缩小搜索范围,直到在万亿维空间中找到最优策略。
汇智网翻译整理,转载请标明出处
