Kilo Code本地代码库索引
如果你想快速、私有地搜索代码而无需发送任何字节到第三方 API,本指南展示了如何设置一个完整的本地栈:Kilo Code 作为 UI,Qdrant(Docker) 用于向量,以及通过 llama.cpp 在 OpenAI 兼容模式下提供的 nomic-embed-code。

如果你使用过 Roo Code 或 Cline,Kilo Code 就像是两者的智能结合:Roo 的代理重构/PR 工作流 + Cline 的目标导向任务规划和文件/终端操作 —— 但内置了 代码库索引器 和一个 OpenAI 兼容的嵌入设置。这种组合使得将 Kilo Code 指向 本地模型(llama.cpp) 和 Qdrant 变得非常简单,这样你的搜索和编辑仍然完全在设备上进行,同时你仍能获得现代的多步骤“代理”操作体验。
我使用 Z AI 的 GLM 4.5 模型与 kilo code
以本地优先的 AI 最终感觉“生产级”。如果你想快速、私有地搜索代码而无需发送任何字节到第三方 API,本指南展示了如何设置一个完整的本地栈:Kilo Code 作为 UI,Qdrant(Docker) 用于向量,以及通过 llama.cpp 在 OpenAI 兼容模式下提供的 nomic-embed-code。它在 MacBook Pro (M4 Max, 128 GB RAM) 上进行了调整,但在较小的机器上也可以运行,只需调整下面的量化级别。你将获得复制粘贴命令、完整性检查(包括 3,584 维验证)和故障排除,以便在几分钟内从零开始完成“绿色 DB 标记”索引——没有消耗任何 token,没有速率限制,没有数据离开你的笔记本电脑。
目标: 使用以下工具在本地对大型代码库进行索引,不调用任何外部 API:
- 嵌入器:
nomic-embed-code(7B,代码优化)通过 llama.cpp 在 服务器模式 下提供 - 向量数据库: Qdrant(Docker)
- 编辑器/代理: Kilo Code 配置为 “OpenAI 兼容” 嵌入
本指南重现了我在 MacBook Pro (Apple M4 Max, 128 GB RAM) 上运行的设置,但它也适用于较小的机器(请调整下面的量化/批量大小)。
1、快速摘要
- 运行 Qdrant Docker
- 使用
nomic-embed-code(Q6_K_L)运行llama.cpp服务器 - 创建一个具有 3584 维 余弦向量的 Qdrant 集合
- 将 Kilo Code 指向
http://127.0.0.1:<PORT>/v1作为 OpenAI 兼容 - 索引;享受本地语义代码搜索
1、安装并运行 Qdrant (Docker)
docker run -d --name qdrant \
-p 6333:6333 -p 6334:6334 \
-v qdrant_storage:/qdrant/storage \
qdrant/qdrant:latest
健康检查:
curl -s http://localhost:6333/ | jq
2、获取 llama.cpp 和模型
构建 llama.cpp(Apple Silicon):
brew install cmake
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp && mkdir build && cd build
cmake ..
cmake --build . --config Release
下载模型(GGUF):
从可靠的镜像中获取 nomic-embed-code-Q6_K_L.gguf(良好的速度/质量),例如 [bartowski](https://huggingface.co/bartowski/nomic-ai_nomic-embed-code-GGUF/blob/main/nomic-ai_nomic-embed-code-Q6_K_L.gguf) 构建。将其放在某个位置,例如:
~/models/nomic-embed-code-Q6_K_L.gguf
3、启动嵌入服务器(OpenAI 兼容)
./build/bin/llama-server \
-m ~/models/nomic-embed-code-Q6_K_L.gguf \
--embedding \
--ctx-size 4096 \
--port 8082 \
--threads 12 \
--n-gpu-layers 999 \
--parallel 4 \
--batch 1024 --ubatch 1024
为什么使用这些标志(简短):
--embedding暴露/v1/embeddings(OpenAI 风格)--ctx-size 4096对于函数/类块来说足够快(比 32k 更快)--parallel+--batch/--ubatch提高索引时的吞吐量
完整性检查:
bashcurl -s http://127.0.0.1:8082/health
测试维度(应打印 3584):
curl -s http://127.0.0.1:8082/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"model": "nomic-embed-code",
"input": " <|im_start|>system\nYou are a model that outputs embeddings for retrieval. <|im_end|>\n<|im_start|>user\nRepresent this query for searching relevant code:\nfind users by email in postgres<|im_end|>\n<|im_start|>assistant\n"
}' | jq '.data[0].embedding | length'
4、创建 Qdrant 集合(3584 维,余弦)
curl -X PUT "http://localhost:6333/collections/code_chunks" \
-H "Content-Type: application/json" -d '{
"vectors": { "dense": { "size": 3584, "distance": "Cosine" } },
"hnsw_config": { "m": 16, "ef_construct": 256 },
"optimizers_config": { "default_segment_number": 1 },
"shard_number": 1,
"replication_factor": 1,
"write_consistency_factor": 1
}'
添加有效负载模式(可选但有用):
curl -X PATCH "http://localhost:6333/collections/code_chunks" \
-H "Content-Type: application/json" -d '{
"payload_schema": {
"path": { "type": "keyword" },
"lang": { "type": "keyword" },
"symbol": { "type": "keyword" }
}
}'
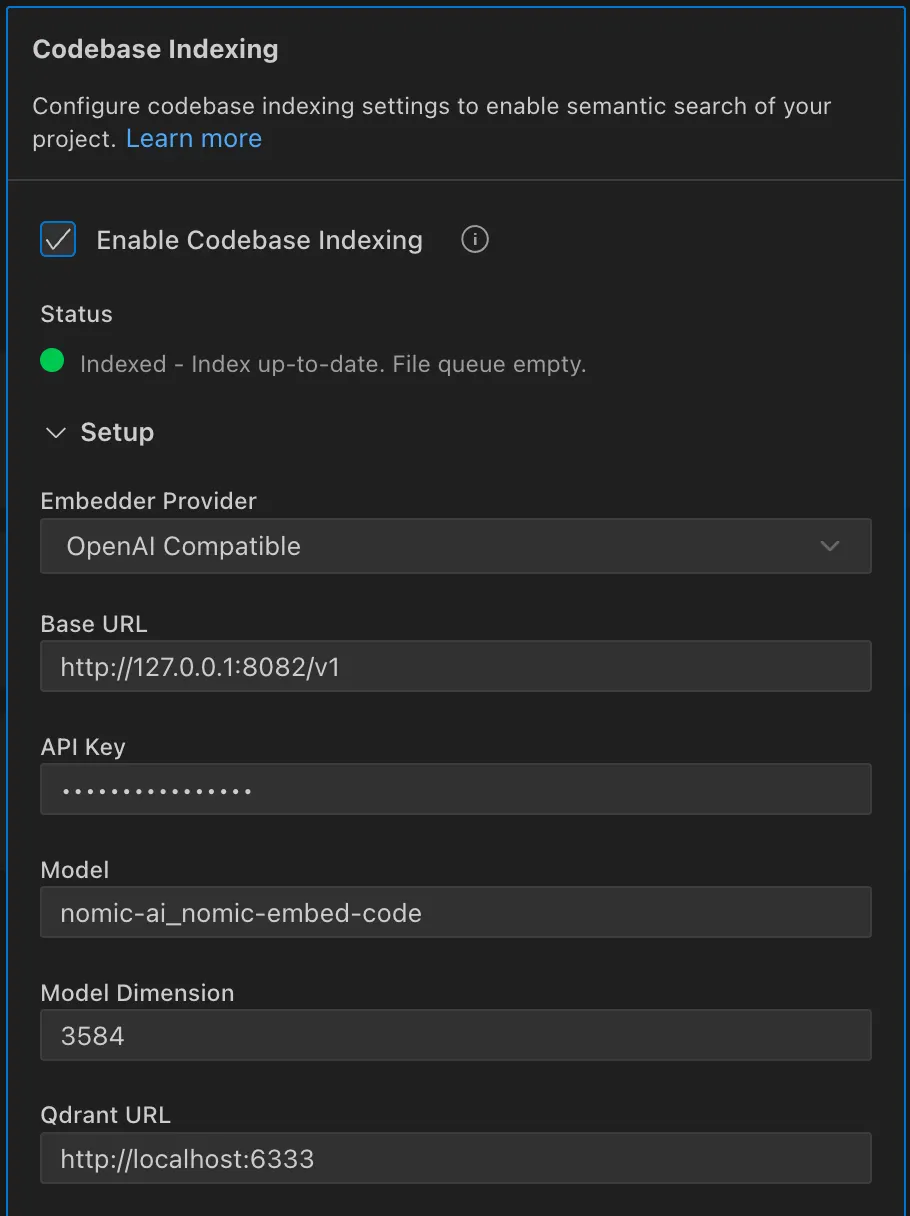
5、配置 Kilo Code(OpenAI 兼容)
设置以下值:
- 嵌入提供者: OpenAI 兼容
- 基础 URL:
<http://127.0.0.1:8082/v1> - API 密钥: 任意(例如
cem) - 模型:
nomic-ai_nomic-embed-code(或如果您的客户端需要精确匹配,则去掉.gguf*)* - 模型维度:
3584 - Qdrant URL:
<http://localhost:6333>
模拟截图(设置面板):
基础 URL http://127.0.0.1:8082/v1, 模型 nomic-embed-code, 维度 3584, Qdrant URL http://localhost:6333 带有绿色“已连接”徽章。
当索引完成后,你会看到一个绿色的数据库标记
索引期间的 llama-server
6、性能与电池提示
对于 索引运行(密集阶段):
- 使用
--ctx-size 4096(不是 32k) - 增加
--parallel(2–6)和--batch/--ubatch(1024–2048)直到稳定 - 如果你需要更快的速度,切换到 Q5_K_M 量化(轻微的质量损失)
- 批处理
/v1/embeddings请求:发送 数组 输入(例如,每调用 64–256 个)
对于 电池模式,将 --parallel 降低到 1–2,并将 --threads 降低到 6–8。
7、验证 Qdrant 中的数据
计算点数:
curl -s "http://localhost:6333/collections/code_chunks" | jq
8、故障排除
- 端口已被占用
更改--port(例如8083)或释放它:
lsof -iTCP:8082 -sTCP:LISTEN -n -P kill -9 <PID>
- 向量不是 3584 维
你使用了错误的模型/维度 —— 将 模型维度 更改为3584。 - 索引爆炸到 100k+ 个块
添加忽略的 glob;减少重叠;切换到 AST 块。 - 比 OpenAI 慢
降低--ctx-size,增加批处理,尝试 Q5_K_M,并批量请求(数组)。 - 重新索引从零开始
使用每个块的稳定确定性 ID(例如sha1(path:start-end:sha1(file))),以便 upserts 覆盖 而不是重复。
9、为什么选择 nomic-embed-code?
它是 代码优化的(多语言)并且在函数/类级别的检索中表现一致强劲。与通用文本嵌入器相比,它通常能以更少的意外检索到正确的符号/文件;这正是你想要的本地代码搜索。如果你需要更多多语言 NL↔code 灵活性或通过 MRL 更小的向量,请考虑 Qwen3-Embedding-8B;对于适度硬件上的原始速度,bge-code-v1 也非常出色。
10、结束语
当 Kilo Code 指向你的 本地 OpenAI 兼容嵌入服务器和 Qdrant 存储 3584 维 向量时,你可以获得私有、可重复且快速的语义代码搜索;没有消耗任何 token,没有速率限制,没有数据离开你的机器。
原文链接:Local, Private, and Fast: Codebase Indexing with Kilo Code, Qdrant, and a Local Embedding Model
汇智网翻译整理,转载请标明出处
