Kyutai实时TTS模型
我见过很多AI语音工具,但Kyutai是我见过的第一个真正感觉像你可以用在实时循环中的声音。

现在市面上大多数AI语音模型都说自己是“实时”的。其实不是。
你给它一段文本,它会思考一会儿,然后开始说话。这只是快速的TTS——不是真正的实时。
1、Kyutai TTS登场
你输入几个词,它就开始说话。不是等整句话,也不是等整个段落。就在你的LLM还在输入下一部分的时候,它已经开始说话了。这是第一次。
目前它只支持英语和法语
Kyutai最初为他们内部的助手Moshi构建了这个模型。然后他们清理了一下并开源了。你可以在unmute.sh上尝试,这是一个小演示,模型像主持播客或单口相声一样说话。感觉非常自然,就像有人在背后操作一样。
他们实际发布的模型叫做kyutai/tts-1.6b-en_fr。它大约有16亿个参数,目前支持英语和法语。
1.1 与众不同之处
我们先说清楚:它不需要完整的文本。 这是主要的不同点。
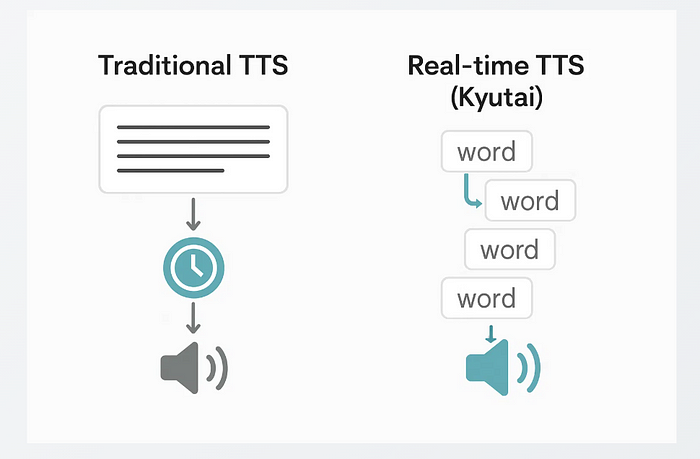
我试过的其他流式TTS都声称是流式的,但仍然需要完整的文本。
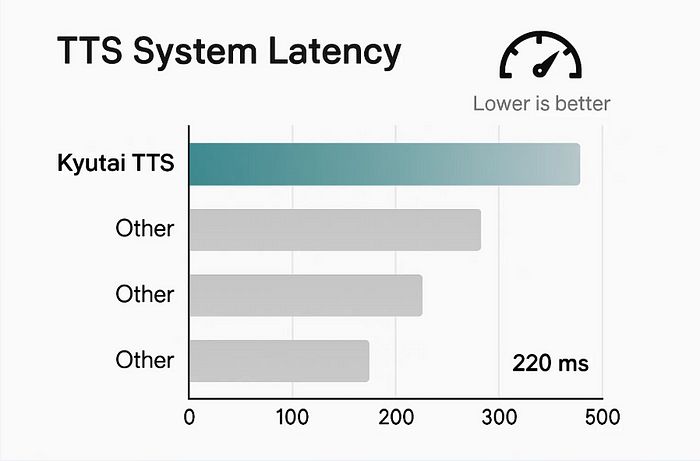
它们只流式传输音频输出,而不是文本输入。因此,如果你的LLM仍在生成内容或者你在使用一个实时聊天机器人,总会有一个延迟。Kyutai TTS不关心这些,它从第一个词开始,并随着文本的流入继续前进。
另外,输入和音频之间的延迟非常短——大约220毫秒。这足够快,可以感觉自然。当他们在单个GPU上进行批量处理(32个请求)时,它保持在350毫秒左右。依然表现良好。
1.2 它也能克隆声音——但有限制
你可以给它一个10秒的某人声音的音频片段,它就会用那个声音说话。它能很好地捕捉语气、节奏,甚至麦克风的质量。
但这里有一个限制:你不能克隆任何声音。 实际学习声音的部分没有发布。他们只允许你使用预设集合中的声音——来自公共数据集的内容。或者,你也可以匿名捐赠自己的声音。
也没有水印。 他们尝试过,但每次重新编码音频时水印都会被清除。所以他们放弃了水印,而是直接限制了克隆流程。
1.3 长音频?没问题
大多数AI语音模型在30秒后就会崩溃。它们要么崩溃,要么开始听起来不对劲。Kyutai不会。你可以输入完整的段落——故事、采访、更长的对话——它都能干净地处理。
1.4 内置的单词时间戳

它说的每个词都有精确的时间戳。不只是粗略的猜测——是实际的单词级时间。
这对于Unmute这样的工具很有用。如果你在句子中间打断AI,应用程序就知道在哪里暂停以及在哪里继续。你不需要从头再听一遍。它记得说了什么和剩下什么。
2、架构
好了,快速介绍一下技术部分,但不要深入论文模式:
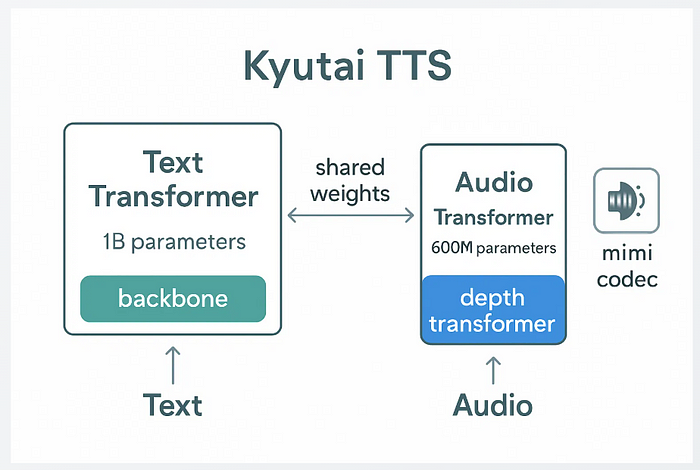
- 该模型使用Transformer构建。一部分处理文本,另一部分将其转换为音频。
- 它使用一种自定义的音频编解码器(称为Mimi),将音频分成小的标记。
- 文本和音频流之间有一点延迟——足以让模型在说话前稍微前瞻一下。
- 他们使用了250万小时的公共音频进行训练。Whisper用于生成数据的转录文本。
- 它是在32块H100 GPU上训练的。后来使用CFG蒸馏来加速。
3、指标
他们在英文和法文的新闻文章上进行了测试。以下是它的表现:
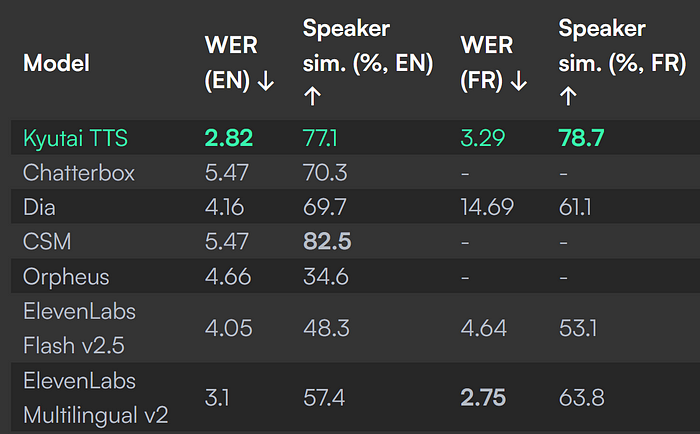
- Kyutai TTS在大多数其他模型中表现更好,具有较低的词错误率(2.82% 英文,3.29% 法文)和较高的说话人相似度(77%以上),这意味着它既准确又自然。
- 在实时使用方面尤其强大,在不需要完整文本的前提下,保持了英文和法文语音的质量。
4、结束语
该模型是开源的,可在HuggingFace上找到。也可以在这里进行测试。
我见过很多AI语音工具。大多数对于一次性使用来说已经不错了:你给他们一个剧本,他们听起来还不错。
但Kyutai是我见过的第一个真正感觉像你可以用在实时循环中的声音。
它干净、响应迅速,而且不假装比它本身更厉害。真正的实时TTS,确实是实时的。
让它说话吧。你会感受到不同。
原文链接:Kyutai TTS : 1st Real Time TTS model
汇智网翻译整理,转载请标明出处
