LMCache:大模型的Redis
有一个名为 LMCache 的项目。它是开源的,可以提升 LLM 的速度。

如果您曾经使用大型语言模型处理过任何重要的任务,那么您一定对等待的过程很熟悉。
输入一个问题,按下回车键,然后……什么都没有。
只是光标旋转,直到第一个单词最终出现。
这种延迟被称为第一个词法单元时间 (TTFT),它可能会令人沮丧。
有一个名为 LMCache 的项目。它是开源的,可以提升 LLM 的速度。
1、LMCache 是什么?

LLM 会执行大量重复性工作。
每次输入文本时,它们都会构建所谓的 KV 缓存(键值缓存)。
可以将其想象成模型在阅读时所做的笔记。
问题是,它们不会重复使用这些笔记。因此,如果您再次输入相同的文本,它会从头开始重建整个内容。
LMCache 解决了这个问题。
它不仅会保存 KV 缓存,还会保存在 GPU 内存中,还会保存在 CPU RAM 甚至磁盘中。当模型再次看到相同的文本(不仅仅是前缀,而是任何重复使用的文本)时,它只需获取已保存的缓存即可。不会浪费 GPU 周期,也无需额外等待。
结果如何?使用 vLLM,在许多标准设置(例如多轮聊天或检索增强生成)中,响应速度可以提高 3 到 10 倍。
看看这个:
# Old way: Slow as molasses
def get_answer(prompt):
memory = build_memory_from_zero(prompt) # GPU cries
return model.answer(memory)
# With LMCache: Zippy and clever
import lmcache
def get_answer(prompt):
if lmcache.knows_this(prompt): # Seen it before?
memory = lmcache.grab_memory(prompt) # Snag it fast
else:
memory = build_memory_from_zero(prompt)
lmcache.save_memory(prompt, memory) # Keep it for later
return model.answer(memory)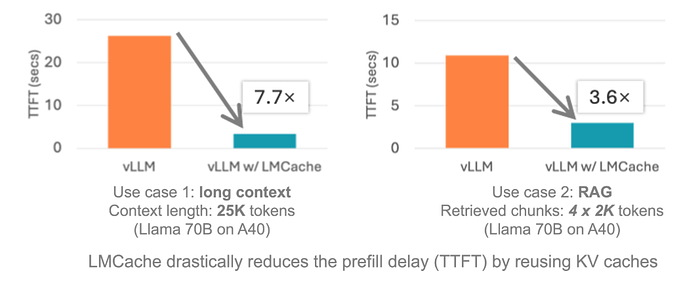
2、LMCache 为何如此出色
我见过不少 AI 工具,但 LMCache 有一些很酷的技巧:
- 速度快:内存获取速度提升高达 7 倍,处理能力也大幅提升。它不关心文本位置,而是会重复使用。
- 存储位置随处:内存可以存储在 CPU、磁盘,甚至是 NIXL 等高端设备上。GPU 可以尽情发挥。
- 支持 vLLM:与 vLLM(版本 1)完美兼容,可以执行跨设备共享工作或在系统间传递内存等便捷操作。
- 为大型任务做好准备:它专为实际应用而构建,可与 llm-d 和 KServe 等工具协同工作,而非仅仅用于车库实验。
如果你正在创建聊天机器人或搜索大型数据集的应用,LMCache 无需强大的计算机即可保持高速运行。
3、如何设置
开始之前,请注意 LMCache 在 Linux 上表现最佳。Windows 用户需要 WSL 或社区插件。此外,你还需要:
- Python 3.9 或更高版本
- NVIDIA GPU(例如 V100 或 H100)
- CUDA 12.8 或更高版本
没有 Wi-Fi?没问题,它一旦准备就绪即可离线运行。
3.1 简单方法:从 PyPI 获取
只想让它工作?运行以下命令:
pip install lmcache它附带最新的 Torch。如果您遇到奇怪的错误,请尝试使用源选项。
3.2 想尝试一下?试试 TestPyPI
想要最新的东西吗?获取预发布版本:
pip install --index-url https://pypi.org/simple --extra-index-url https://test.pypi.org/simple lmcache==0.3.4.dev61
检查是否正确:
import lmcache
from importlib.metadata import version
print(version("lmcache")) # Should be 0.3.4.dev61 or newer将版本号替换为 LMCache GitHub 上的任何最新版本。
3.3 自行构建
喜欢自己动手修改吗?克隆并运行:
git clone https://github.com/LMCache/LMCache.git
cd LMCache
pip install -r requirements/build.txt
# Pick one:
# A: Choose your Torch
pip install torch==2.7.1 # Good for vLLM 0.10.0
# B: Get vLLM with Torch included
pip install vllm==0.10.0
pip install -e . --no-build-isolation确保安装顺利:
python3 -c "import lmcache.c_ops"没有崩溃?那就没问题了。
3.4 使用 uv 快速设置
如果您喜欢快速工具,请尝试 uv:
git clone https://github.com/LMCache/LMCache.git
cd LMCache
uv venv --python 3.12
source .venv/bin/activate
uv pip install -r requirements/build.txt
# Same Torch/vLLM choices
uv pip install -e . --no-build-isolation3.5 Docker
想要更简单?使用 Docker:
# Stable
docker pull lmcache/vllm-openai
# Nightly
docker pull lmcache/vllm-openai:latest-nightly对于 AMD GPU(例如 MI300X),请从 vLLM 镜像开始,并添加:
PYTORCH_ROCM_ARCH="gfx942" \
TORCH_DONT_CHECK_COMPILER_ABI=1 \
CXX=hipcc \
BUILD_WITH_HIP=1 \
python3 -m pip install --no-build-isolation -e .4、将其插入 vLLM
LMCache 和 vLLM 就像烧烤聚会上的好朋友。对于 vLLM v1:
pip install vllm测试:
python3 -c "import vllm.distributed.kv_transfer.kv_connector.v1.lmcache_connector"
使用 vLLM v0?请查看其代码库中的示例脚本。
原文链接:LMCache: The Fastest Open-Source Serving Engine for LLMs
汇智网翻译整理,转载请标明出处
