MCP:从AI代理到模块化执行
要将智能转化为现实世界的执行,需要模块化、标准化以及强大的接口。这就是 模型上下文协议(MCP)的作用所在。
AI代理非常棒。它们可以思考、计划并以极少量的代码执行任务。它们为将复杂的存储库和API分解为更功能化的实现提供了巨大的机会。但要将这种智能转化为现实世界的执行,需要模块化、标准化以及强大的接口。这就是 模型上下文协议(MCP)的作用所在。
在这篇文章中,我将探讨:
- 什么是好的代理,为什么传统的工具链会遇到扩展限制
- 协调器和函数工具在早期代理系统中的作用
- 如何通过MCP将代理架构转变为可发现、可替换、生产级的管道
- 构建符合MCP标准的工具服务器的实际代码,并从任何AI代理中调用它们(本文技术性较强)。
1、什么造就了一个出色的代理?
构建代理时起初很简单:你为LLM编写专门的指令来完成任务,并且可以选择性地为其提供访问函数工具的权限,以便它能够调用外部API。
但真正出色的代理是:
- 模块化:每个任务都独立定义并且可重用
- 可组合:代理可以智能地委托或链接任务
- 接地:它们通过工具与真实世界的数据交互
- 协调:根据输入和上下文路由动作序列
- 可维护:逻辑和工具分别演进
在之前的一篇文章中,我写过我是如何构建一个应用程序来处理我的文档处理的。这些原则指导了我构建一个多代理管道,该管道:
- 读取文档(PDF/图像)
- 提取原始文本
- 摘要
- 提取元数据
- 存储
- 在存储的数据上回答用户的问题
让我们分解一下我最初是如何设计这个系统的——以及它在哪里遇到了限制。
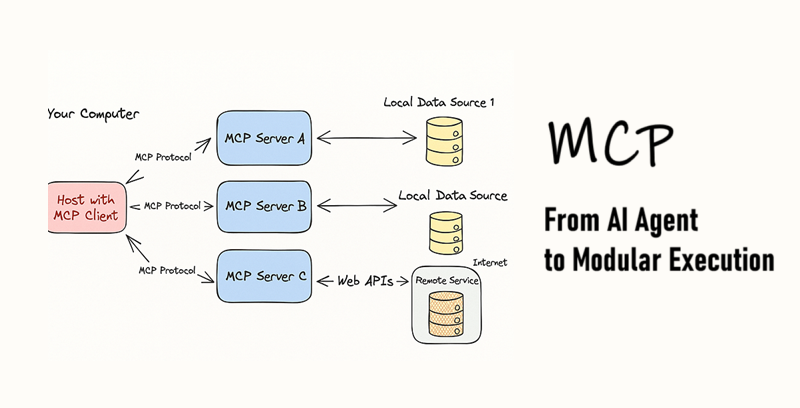
2、MCP客户端-主机-服务器架构的工作原理
为了理解我的文档助手是如何从独立脚本发展为模块化系统的,了解MCP的实际操作很有帮助。本质上,MCP遵循一种客户端-主机-服务器模型,该模型抽象了工具集成,同时保留了灵活性和控制权。
- 主机是操作的核心,通常是像Claude、ChatGPT或我们自己的协调器应用程序这样的AI接口。它负责启动MCP客户端,执行安全性和权限策略,并决定何时调用外部工具。在我的案例中,您之前看到的协调器逻辑可以充当此主机,根据用户输入或自动化工作流选择调用OCR或Firestore服务器。
- 客户端充当主机与单个服务器之间的桥梁。一旦启动,它将处理所有通信,格式化结构化请求,将其传递给适当的服务器,并将结果返回给主机。您不需要编写太多自定义代码,因为客户端SDK处理了大部分复杂性。
- 服务器是发生魔法的地方。它是您作为开发人员构建的组件,例如我的OCR微服务,并且它暴露特定的功能。例如,我的
ocr_server可能提供一个名为extract_text的工具。如果我稍后构建了一个检索服务器,它可以提供诸如query_documents或semantic_lookup之类的工具。
服务器可以暴露三种类型的能力:
- 提示:预定义的模板或指令,用于引导模型(例如法律备忘录模板或状态更新格式)。
- 资源:结构化的上下文数据,如PDF、数据库记录或向量嵌入。
- 工具:可调用的函数,允许模型采取行动,如总结文本、更新文档或发送Slack消息。
将MCP视为连接代理与外部能力的纽带,通过标准化、可检查和互操作的接口。乍一看,它可能类似于传统API,但有一个关键区别:API直接暴露功能供使用,而MCP允许代理动态地通过JSON模式发现、描述和调用工具。
例如,我的Firestore服务器可以用MongoDB版本替换,而不必修改协调器。或者我可以将我的OCR服务器插入另一个项目中,只要它符合MCP清单,它就会正常工作。
这种职责分离以及它解锁的模块化正是使MCP成为开发构建AI原生系统的强大升级路径的原因。
3、使用OpenAI代理和函数工具进行构建
使用像OpenAI代理SDK或LangChain这样的框架,您可以将工具定义为Python函数并将其传递给代理。
这是一个OCR工具的例子:
@tool
def extract_text(file_bytes: bytes) -> str:
image = vision.Image(content=file_bytes)
response = client.document_text_detection(image=image)
return response.full_text_annotation.text
然后将其包装为代理:
extract_text_agent = Agent(
instructions="Extract text using OCR.",
tools=[extract_text],
model="gpt-4o-mini"
)
您可以使用协调器将这些代理链接在一起:
orchestrator = Agent(
instructions="""
1. Use the OCR tool to extract text
2. Summarize the text
3. Extract metadata
4. Store everything
""",
tools=[
extract_text_agent.as_tool("ocr"),
summarizer_agent.as_tool("summarize"),
metadata_agent.as_tool("extract_metadata"),
firestore_agent.as_tool("store")
]
)
这有效了,而且我仍然相信这是一种可行的组合,但它紧密耦合了代码、代理和服务。如果我想:
- 将OCR从GCP切换到Azure
- 从Firestore迁移到PostgreSQL
- 添加缓存层
我需要修改核心代理逻辑和协调器指令。这可能需要额外的工作并限制我们的可扩展性。
4、MCP登场:模型上下文协议
模型上下文协议(MCP) 是由Anthropic(Claude的创造者)引入的一种标准,用于通过结构化的基于JSON的接口向LLM暴露工具。它实现了:
- 可发现性:模型通过清单文件自我检视工具能力
- 解耦:工具是服务器,而不是内联函数
- 标准化:输入和输出使用类型化的模式
- 可替换性:通过指向新的清单文件来交换工具
- 兼容性:适用于GPT、Claude、Llama以及其他LLM主机
将MCP视为工具与AI运行时之间的契约。现在,您不是构建函数工具,而是构建带有清单的REST服务器。
LLM的有用程度取决于其训练数据或可立即访问的数据。如果我们没有一个能够连接互联网或数据库的功能工具,那么它的功能将受到严重限制。但MCP为AI工具提供了一种标准化的方法来发现其他API和工具。它允许我们的AI工具找到新的信息来源并执行操作,而不仅仅是给我们见解,从而让我们的应用程序变得更加强大。
以前,这意味着我们需要创建自定义集成,以便我们的AI应用程序能够连接到外部工具(例如,在调用OpenAI之前先击打Google Cloud端点,存储该信息并将其传递到提示中)。MCP大大简化了开发人员构建工具集成的过程,也使得开发人员更容易在不同工具之间切换,从而让我们能够更加模块化和可扩展。
5、构建符合MCP标准的工具服务器
让我们逐步构建一个遵循MCP标准的OCR工具。
5.1 将OCR工具构建为服务器
# ocr_mcp_server.py
from typing import Any
from mcp.server.fastmcp import FastMCP
from google.cloud import vision
import base64
# 初始化MCP服务器
mcp = FastMCP("ocr")
# OCR工具
@mcp.tool()
async def extract_text(file_content: str) -> str:
"""从base64编码的PDF或图像内容中提取文本。"""
client = vision.ImageAnnotatorClient()
image_bytes = base64.b64decode(file_content.encode("utf-8"))
image = vision.Image(content=image_bytes)
response = client.document_text_detection(image=image)
if not response.full_text_annotation.text:
return "未在文档中找到文本。"
return response.full_text_annotation.text
# 运行服务器
if __name__ == "__main__":
mcp.run(transport="stdio")
5.2 定义MCP清单
{
"name": "OCR MCP服务器",
"description": "使用Google Cloud Vision API从base64编码的PDF或图像文件中提取原始文本。",
"tools": [
{
"name": "extract_text",
"description": "从base64编码的文件内容字符串中提取完整的文档文本。",
"input_schema": {
"type": "object",
"properties": {
"file_content": {
"type": "string",
"description": "PDF或图像的base64编码二进制内容"
}
},
"required": ["file_content"]
},
"output_schema": {
"type": "string",
"description": "文档的完整OCR文本内容"
}
}
]
}
这允许任何模型协调器理解:
- 这个工具做什么
- 预期的输入/输出是什么
- 请求应发送到哪里
虽然FastMCP自动检视工具定义,但清单允许工具即使在客户端未见过代码的情况下也能被普遍发现。
6、MCP客户端:将工具调用为动作
现在,您的协调器不再依赖于工具——它调用MCP动作。
import base64
from mcp.client import MCPClient
import asyncio
async def main():
# 第一步:读取并编码文件
with open("sample.pdf", "rb") as f:
file_bytes = f.read()
file_content = base64.b64encode(file_bytes).decode("utf-8")
# 第二步:初始化客户端
client = MCPClient("http://localhost:8001")
# 第三步:调用OCR工具
result = await client.call_tool("extract_text", {"file_content": file_content})
# 第四步:输出提取的文本
print("提取的文档文本:\n")
print(result)
if __name__ == "__main__":
asyncio.run(main())
无需代理或工具知道其他部分是如何实现的。这就是MCP的力量。
7、MCP架构的优势
- 模块化:每个工具都是隔离的、可版本化的和可测试的
- 可组合性:代理可以通过清单混合和匹配工具
- 可维护性:工具模式更改不会破坏协调
- 可扩展性:添加新服务(如Pinecone、Langchain、Redis)无需更新代理
- 跨模型:适用于GPT、Claude、LLaMA等
8、MCP与代理API对比
AI代理是旨在无需详细说明每一步即可采取行动的智能系统。例如,在我的文档助手示例中,一旦上传文件,我不需要手动调用OCR、摘要或元数据提取。协调器代理会根据我定义的指令自动处理所有这些。它不仅决定做什么,还根据输入动态决定如何完成任务。
MCP通过为代理提供标准化访问外部服务的方式提升了这种自主性。与其在协调器中硬编码函数调用,我可以将OCR或Firestore存储等功能作为独立的MCP服务器公开。代理不需要知道它们是如何实现的——它只需调用一个像extract_text这样的动作,底层服务器就会处理其余的事情。这样可以更容易地插入新工具或更换提供商,例如从Google Vision切换到Azure OCR,而无需重写代理逻辑。
也就是说,MCP是一个面向开发者的框架。它旨在为希望精确控制代理如何与工具和数据交互的工程师设计。它通过允许AI连接到外部工具(如数据库或Google Cloud API)使其具有自主性。仅仅使用MCP并不意味着应用程序具有自主行为——即自主解决问题的能力,而不仅仅是解决什么问题。
它们为不同的人解决不同的问题,在不断发展的AI生态系统中都有其角色。在尝试创建完全自动化的系统时,最重要的考虑因素应该是模块化、可扩展性和可靠性。如何达到这一步取决于您的偏好以及您所拥有的工具。
原文链接:From Smart Agents to Modular Execution: MCP and How it Enables Agentic AI
汇智网翻译整理,转载请标明出处
