MedGemma:医学多模态模型
MedGemma 4B是一组经过训练以在与医学文本和图像理解相关的任务中表现良好的Gemma 3变体。本文介绍如何使用MedGemma模型结合医学图像和文本提示生成有意义的临床输出。
MedGemma 4B是一组经过训练以在与医学文本和图像理解相关的任务中表现良好的Gemma 3变体。它涵盖了医学图像分类、医学图像解释、医学文本理解以及临床推理。它可以解释多种放射学模态,包括X光片、CT、MRI、组织病理学、眼底和皮肤图像。它还可以根据图像回答问题并生成医学报告。MedGemma 4B的功能详细描述可以在Hugging Face模型卡页面找到,或者,你可以通过Google Cloud模型园页面访问该模型,在这里。
在这篇文章中,我们将重点探讨该模型在医学图像解释方面的能力。
1、加载模型
最近,Hugging Face和Kaggle整合了它们的生态系统。从Hugging Face模型卡片中,您可以快速打开一个已在Kaggle资源上预置和预编辑的Kaggle笔记本,用于测试Hugging Face模型。为此,请选择菜单使用模型,然后选择笔记本|Kaggle菜单项。
2、生成访问令牌
MedGemma模型是免费使用的,但仅限于签署协议的人。因此,您首先需要签署协议,然后登录Hugging Face以验证您的身份。在Kaggle环境中,最方便的是使用身份验证令牌。这可以轻松地从您的帐户生成,只需遵循几个简单步骤:
- 选择您的个人资料菜单,然后选择访问令牌菜单项
- 按下创建新令牌按钮
- 从精细、读取和写入选项中选择创建读取访问令牌
- 输入一个令牌名称(我使用了HUGGINGFACE_TOKEN),并复制生成的访问令牌
3、定义Kaggle秘密并登录Hugging Face
生成令牌后,将其值复制并粘贴到Kaggle秘密库中:
- 创建一个新的秘密,命名为HUGGINGFACE_TOKEN
- 将访问令牌的值粘贴为值
在您的笔记本中,使用以下代码登录Hugging Face:
from kaggle_secrets import UserSecretsClient
from huggingface_hub import login
user_secrets = UserSecretsClient()
hugging_face_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hugging_face_token)
定义模型管道
一旦认证完成,我们可以使用transformers中的pipeline来初始化模型。在管道初始化时,我们指定模式为image-text-to-text。我们将加载一张图像以及用户指令,模型输出将只包含文本。我们还指定了模型(MedGemma 4B指令调优版)。
pipe = pipeline(
"image-text-to-text",
model="google/medgemma-4b-it",
torch_dtype=torch.bfloat16,
device="cuda",
)
4、测试模型
我们将使用各种医学图像测试模型。对于每次测试,我们将加载图像,准备消息,运行管道并显示输出。图像可以从网络加载,也可以从本地挂载的存储加载——就像我们在加载Kaggle数据集时所做的那样。
这是从URL加载图像的一个代码示例:
image_url = "https://upload.wikimedia.org/wikipedia/commons/c/c8/Chest_Xray_PA_3-8-2010.png"
image = Image.open(requests.get(image_url, headers={"User-Agent": "example"}, stream=True).raw)
如果图像存储在本地挂载的文件夹中,加载它的代码更简单:
image_path = "/kaggle/input/melanoma-skin-cancer-dataset-of-10000-images/melanoma_cancer_dataset/train/malignant/melanoma_5003.jpg"
image = Image.open(image_path)
可以使用简单的代码显示图像:
plt.imshow(image)
plt.axis('off')
plt.show()
以下是一个消息样本:
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "你是一位经验丰富的放射科医生。"}]
},
{
"role": "user",
"content": [
{"type": "text", "text": "分析这张图像。"},
{"type": "image", "image": image},
]
}
]
使用以下代码,我们可以用之前定义的消息运行管道,其中包括系统提示以及用户输入文本和输入图像。
output = pipe(text=messages, max_new_tokens=256)
display(Markdown(output[0]["generated_text"][-1]["content"]))
让我们检查一些使用MedGemma模型的例子。
4.1 皮肤黑色素瘤图像
第一个测试将使用来自Melanoma数据集的皮肤黑色素瘤图像,该数据集包含 10,000 张黑色素瘤皮肤癌图像。下图是皮肤黑色素瘤的示例:
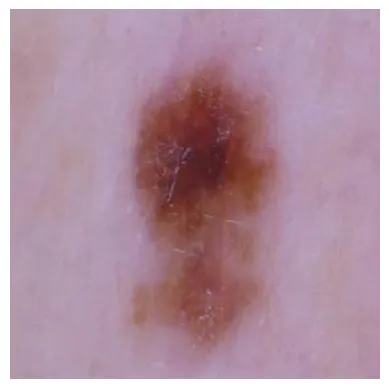
下图展示了模型输出的摘录:

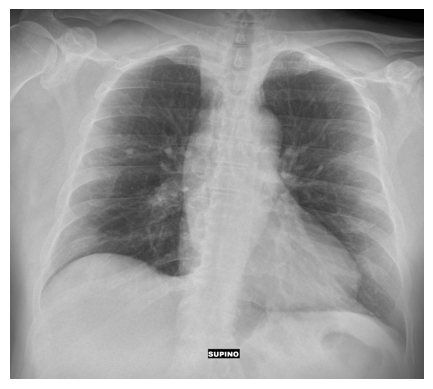
4.2 胸部X光片图像
接下来,我们分析一位因新冠引起的肺炎患者的胸部X光片图像。我们要求模型分析图像,并且我们还指定希望它验证是否为肺炎。数据集链接。
下面的图像是X光片,之后我们将展示模型提示此图像后的完整输出。

4.3 脑肿瘤MRI图像
下一个测试是使用脑肿瘤MRI图像数据集中的图像。
我们选择了一张脑膜瘤的MRI图像:
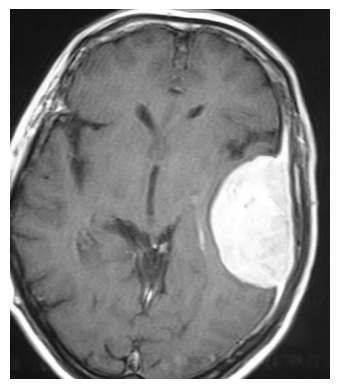
模型提示解释MRI图像的输出如下:

图像解释准确,识别了模态、协议和病理,并提供了有价值的评论。
4.4 乳腺癌组织病理学图像
接下来要分析的模态是一张组织病理学图像,来自乳腺癌图像数据集。
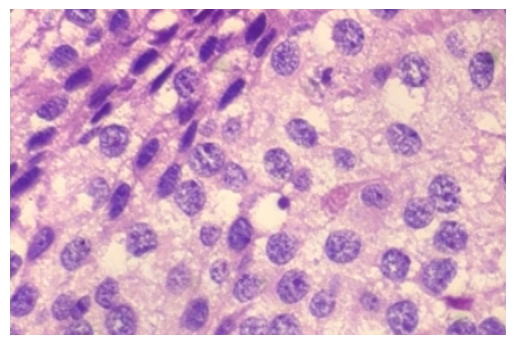
图像解释非常详细且准确,识别出它是显微镜图像,明确了染色类型(切片制备)和病理:
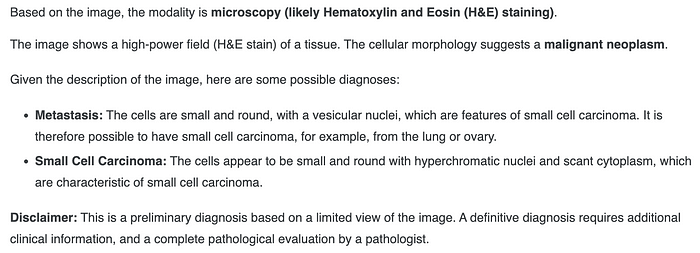
模型提示解释乳腺癌组织病理学图像的输出——作者图片
完整的Kaggle笔记本包含模型加载和各种测试。
5、结束语
Google DeepMind的这款专用模型允许解释各种医学图像,涵盖X光片、MRI、CT、皮肤、组织病理学等。图像解释准确,正确识别了图像模态、医疗协议等。当需要诊断时,诊断也是正确的,模型在答案中还包括了其输出不能作为最终医学诊断的说明,并建议用户寻求适当的医疗检查。
原文链接:From X-rays to Insights: Exploring MedGemma 4B’s Medical Multimodality
汇智网翻译整理,转载请标明出处
