MiniCPM-V 4.5:最佳边缘LLM
MiniCPM-V 4.5是MiniCPM-V系列中的最新模型。尽管体积小,但它在视觉语言任务、视频理解和OCR/文档解析方面的性能有了显著提升。

这次,原始移动AI模型带来了重大更新,MiniCPM-V 4.5已经发布,看起来可能是最适合手机和边缘设备的最佳AI。
MiniCPM-V 4.5是MiniCPM-V系列中的最新模型。它基于Qwen3–8B和SigLIP2–400M,总共有8B参数。尽管体积小,但它在视觉语言任务、视频理解和OCR/文档解析方面的性能有了显著提升。
1、视觉语言性能


在OpenCompass(一套8个基准测试)中,MiniCPM-V 4.5的平均得分为77.0。仅使用8B参数,它就超过了更大的开源模型,包括Qwen2.5-VL 72B,甚至击败了像GPT-4o-latest这样的专有模型。这使其成为目前30B参数以下最强的多模态LLM。
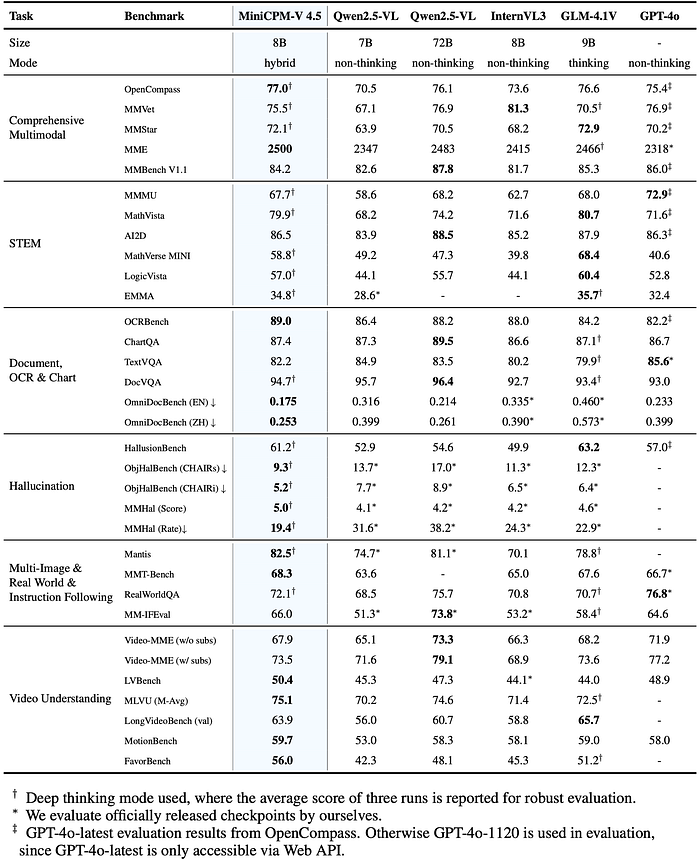
基准测试表支持这一点:
- OpenCompass: 77.0
- MMVet: 75.5
- MME: 2500(远远领先于Qwen2.5-VL和InternVL3)
- MMBench V1.1: 84.2
2、使用3D-Resampler进行视频理解
大多数MLLM在处理视频时遇到困难,因为标记数量迅速增加。MiniCPM-V 4.5引入了3D-Resampler,可以将6帧(448×448)压缩为仅64个标记。通常需要1,536个标记,因此该模型实现了96倍的压缩率。
其优势包括:
- 它可以在不增加推理成本的情况下处理长视频。
- 支持高刷新率视频(最高10 FPS)。
- 在视频基准测试如Video-MME、LVBench、MLVU、MotionBench、FavorBench中取得顶级成绩。
3、快速和深度思考模式
该模型支持两种不同的推理模式:
- 快速模式用于高效的日常任务。
- 深度模式用于更难的多步骤推理。
这种切换经过严格控制,并通过强化学习进行训练,因此快速模式不会变弱,而深度模式保持可靠。
4、强大的OCR和文档解析能力
MiniCPM-V 4.5基于LLaVA-UHD,可以处理高达180万像素的图像(例如1344×1344),使用的标记比大多数模型少4倍。
基准测试结果突显了这一优势:
- OCRBench: 89.0(领先于GPT-4o和InternVL3)
- ChartQA: 87.4
- TextVQA: 82.2
- OmniDocBench (EN): 0.175,是通用MLLM中最好的
这使其特别适合PDF解析、表格和高分辨率文档任务。
5、可靠且多语言支持
MiniCPM-V 4.5结合了RLAIF-V和VisCPM,减少了幻觉现象。在MMHal-Bench上,它甚至超越了GPT-4o-latest。它还支持30多种语言,比许多其他小型MLLM具有更广泛的应用范围。
6、部署和使用
该模型设计为灵活使用:
- 本地推理:通过
llama.cpp和ollama支持(CPU友好)。 - 量化格式:int4、GGUF、AWQ共16种大小。
- 框架:与SGLang和vLLM兼容,用于高效的服务器推理。
- 微调:可通过Transformers和LLaMA-Factory实现。
- 演示:本地测试的WebUI,优化的iOS应用,以及在线服务器演示。
该模型是开源的,权重可在此处访问。
7、结束语
MiniCPM-V 4.5展示了你可以将一个紧凑的8B参数模型推向多远。凭借最先进的OCR、高效视频理解和快速/深度推理模式,它在保持轻量级的同时持续击败更大的模型,适合本地部署。
对于任何涉及视频、文档或多语言多模态任务的人来说,这是目前最实用的模型之一。
原文链接:MiniCPM-V 4.5 : Best LLM for Mobiles
汇智网翻译整理,转载请标明出处
