从数据中挖掘规则
在本文中,我们探讨了如何从数据中提取简单的“规则”,并将其用于业务决策。

在处理产品时,我们可能会遇到需要引入一些“规则”的情况。让我用实际例子来解释一下我所说的“规则”:
- 假设我们在我们的产品中看到了大量的欺诈行为,我们希望限制特定客户群体的注册以降低这种风险。例如,我们发现大多数欺诈者使用了特定的用户代理和来自某些国家的IP地址。
- 另一种选择是向客户发送优惠券以在我们的网上商店使用。然而,我们只想针对可能流失的客户发放优惠券,因为忠诚的用户会无论如何返回产品。我们可能会发现最可行的群体是那些加入不到一年并且上个月花费减少了30%以上的客户。
- 交易型业务常常有一部分客户群体是亏损的。例如,一位银行客户通过了验证,并经常联系客户服务(因此产生了启动和维护成本),但几乎不做任何交易(因此不产生任何收入)。银行可能会对账户余额低于1000美元的客户收取小额月费,因为他们很可能不盈利。
当然,在所有这些情况下,我们都可以使用复杂的机器学习模型来考虑所有因素并预测客户成为欺诈者或流失的概率。然而,在某些情况下,我们可能更喜欢使用一组静态规则,原因如下:
- 实施的速度和复杂性。 在生产环境中部署机器学习模型需要时间和努力。如果你现在正在经历一场欺诈浪潮,那么快速实施一组静态规则可能比全面解决方案更可行。
- 可解释性。 机器学习模型是黑盒子。即使我们能够在高层次上理解它们的工作原理以及哪些特征最重要,但要向客户解释它们仍然很困难。例如,在对非盈利客户收取订阅费用的情况下,与客户分享一组透明的规则很重要,以便他们能够理解定价。
- 合规性。 某些行业,如金融或医疗保健,可能要求审计和基于规则的决策以满足合规要求。
在这篇文章中,我想向你展示如何使用这样的规则来解决业务问题。我们将通过一个实际的例子深入探讨这个主题:
- 我们将讨论可以用来从数据中挖掘这些规则的模型,
- 我们将从头开始构建一个决策树分类器以了解其工作原理,
- 我们将拟合
sklearn决策树分类器模型以提取数据中的规则, - 我们将学习如何解析决策树结构以获得最终的细分,
- 最后,我们将探索不同的类别编码选项,因为
sklearn实现不支持分类变量。
我们有很多话题要讨论,所以让我们直接进入正题。
1、案例
通常,用实践例子更容易学习某些东西。所以,让我们先讨论本文将解决的任务。
我们将使用银行营销数据集。该数据集包含一家葡萄牙银行的直接营销活动的数据。对于每个客户,我们知道许多特征以及他们是否订阅了定期存款(我们的目标)。
我们的商业目标是在有限的运营资源下最大化转换(订阅)的数量。因此,我们不能呼叫整个用户群,而是希望在现有资源下取得最佳结果。
第一步是查看数据。所以,让我们加载数据集。
import pandas as pd
pd.set_option('display.max_colwidth', 5000)
pd.set_option('display.float_format', lambda x: '%.2f' % x)
df = pd.read_csv('bank-full.csv', sep = ';')
df = df.drop(['duration', 'campaign'], axis = 1)
# 删除了与当前营销活动相关的列,因为它们会引入数据泄漏
df.head()
我们对客户知道很多信息,包括个人数据(如职业类型或婚姻状况)以及他们的先前行为(如是否有贷款或平均年余额)。

下一步是选择机器学习模型。当我们需要易于解释的模型时,通常有两种类型的模型可供选择:
- 决策树,
- 线性或逻辑回归。
这两种选择都是可行的,并且可以给我们提供良好的模型,这些模型易于实施和解释。然而,在这篇文章中,我更倾向于使用决策树模型,因为它会产生实际的规则,而逻辑回归则会给出特征加权和的概率。
2、数据预处理
正如我们在数据中看到的那样,有许多分类变量(如教育程度或婚姻状况)。不幸的是,sklearn决策树实现无法处理分类数据,所以我们需要做一些预处理。
让我们首先将yes/no标志转换为整数。
for p in ['default', 'housing', 'loan', 'y']:
df[p] = df[p].map(lambda x: 1 if x == 'yes' else 0)
下一步是转换month变量。我们可以为月份使用独热编码,引入标志如month_jan、month_feb等。然而,可能存在季节效应,我认为将其按顺序转换为整数更为合理。
month_map = {
'jan': 1, 'feb': 2, 'mar': 3, 'apr': 4, 'may': 5, 'jun': 6,
'jul': 7, 'aug': 8, 'sep': 9, 'oct': 10, 'nov': 11, 'dec': 12
}
# 我让ChatGPT帮我做了这个映射,节省了5分钟
df['month'] = df.month.map(lambda x: month_map[x] if x in month_map else x)
对于其他所有分类变量,让我们使用独热编码。我们将在后面讨论不同类别的编码策略,但现在让我们坚持默认方法。
使用pandas中的get_dummies函数进行独热编码是最简单的方法。
fin_df = pd.get_dummies(
df, columns=['job', 'marital', 'education', 'poutcome', 'contact'],
dtype = int, # 转换为0/1标志
drop_first = False # 保留所有可能的值
)
此函数将每个分类变量转换为每种可能值的一个单独的1/0列。我们可以看到它对poutcome列的工作方式。
fin_df.merge(df[['id', 'poutcome']])\
.groupby(['poutcome', 'poutcome_unknown', 'poutcome_failure',
'poutcome_other', 'poutcome_success'], as_index = False).y.count()\
.rename(columns = {'y': 'cases'})\
.sort_values('cases', ascending = False)
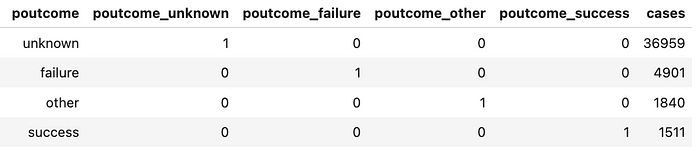
我们的数据现在已经准备好了,是时候讨论决策树分类器的工作原理了。
3、决策树分类器:理论
在本节中,我们将探讨决策树分类器背后的理论,并从头开始构建算法。如果你更感兴趣于实践示例,请随时跳到下一节。
最容易理解决策树模型的方法是看一个例子。所以,让我们基于我们的数据构建一个简单的模型。我们将使用sklearn中的DecisionTreeClassifier。
feature_names = fin_df.drop(['y'], axis = 1).columns
model = sklearn.tree.DecisionTreeClassifier(
max_depth = 2, min_samples_leaf = 1000)
model.fit(fin_df[feature_names], fin_df['y'])
下一步是可视化树形结构。
dot_data = sklearn.tree.export_graphviz(
model, out_file=None, feature_names = feature_names, filled = True,
proportion = True, precision = 2
# 显示类别的比例而不是绝对数量
)
graph = graphviz.Source(dot_data)
graph
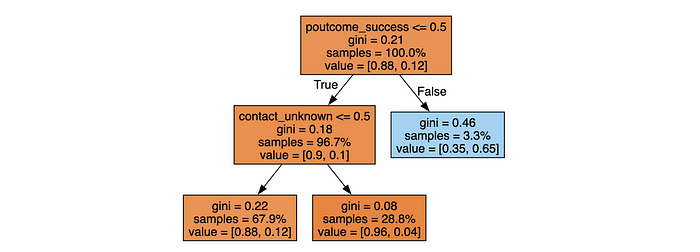
因此,我们可以看到模型很简单。它是一组二元分裂,我们可以将其作为启发式方法使用。
让我们弄清楚分类器是如何工作的。通常,最好的方法是从头开始构建逻辑。
任何问题的核心都是优化函数。默认情况下,在决策树分类器中,我们优化的是Gini系数。想象一下从样本中随机获取一个项目,然后再获取另一个。Gini系数等于这两个项目属于不同类别的概率。因此,我们的目标将是最小化Gini系数。
在只有两类的情况下(如我们的例子中,市场营销干预要么成功要么失败),Gini系数仅由一个参数p定义,其中p是获取一类项目的概率。以下是公式:
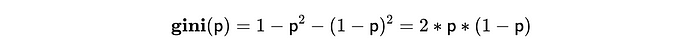
如果我们的分类是理想的,并且我们能够完美地分离类别,那么Gini系数将等于0。最坏的情况是p = 0.5,此时Gini系数也等于0.5。
有了上面的公式,我们可以计算树中每个叶子节点的Gini系数。为了计算整个树的Gini系数,我们需要组合二元分裂的Gini系数。为此,我们可以得到加权和:
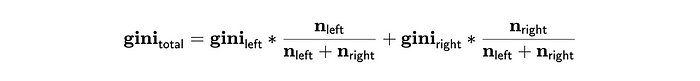
现在我们知道了要优化的值,只需要定义所有可能的二元分裂,迭代它们并选择最佳选项。
定义所有可能的二元分裂也很简单。我们可以逐一针对每个参数进行操作,对可能的值进行排序,并在它们之间选择阈值。例如,对于月份(整数从1到12)。
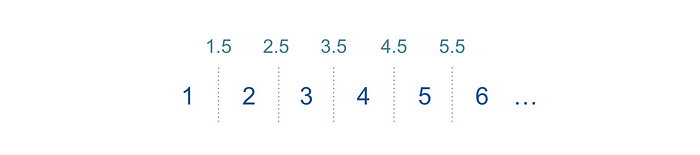
让我们尝试编写代码并看看我们是否会得到相同的结果。首先,我们将定义计算单个数据集Gini系数和组合的函数。
def get_gini(df):
p = df.y.mean()
return 2*p*(1-p)
print(get_gini(fin_df))
# 0.2065
# 接近我们在决策树根节点看到的结果
def get_gini_comb(df1, df2):
n1 = df1.shape[0]
n2 = df2.shape[0]
gini1 = get_gini(df1)
gini2 = get_gini(df2)
return (gini1*n1 + gini2*n2)/(n1 + n2)
下一步是获取一个参数的所有可能阈值并计算它们的Gini系数。
import tqdm
def optimise_one_parameter(df, param):
tmp = []
possible_values = list(sorted(df[param].unique()))
print(param)
for i in tqdm.tqdm(range(1, len(possible_values))):
threshold = (possible_values[i-1] + possible_values[i])/2
gini = get_gini_comb(df[df[param] <= threshold],
df[df[param] > threshold])
tmp.append(
{'param': param,
'threshold': threshold,
'gini': gini,
'sizes': (df[df[param] <= threshold].shape[0], df[df[param] > threshold].shape[0]))
}
)
return pd.DataFrame(tmp)
最后一步是遍历所有特征并计算所有可能的分裂。
tmp_dfs = []
for feature in feature_names:
tmp_dfs.append(optimise_one_parameter(fin_df, feature))
opt_df = pd.concat(tmp_dfs)
opt_df.sort_values('gini', asceding = True).head(5)
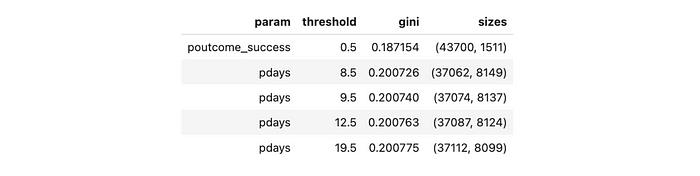
太棒了,我们得到了与DecisionTreeClassifier模型相同的结果。最优分裂是poutcome = success或不是。我们已经将Gini系数从0.2065减少到了0.1872。
要继续构建树,我们需要递归地重复这个过程。例如,进入poutcome_success <= 0.5分支:
tmp_dfs = []
for feature in feature_names:
tmp_dfs.append(optimise_one_parameter(
fin_df[fin_df.poutcome_success <= 0.5], feature))
opt_df = pd.concat(tmp_dfs)
opt_df.sort_values('gini', ascending = True).head(5)
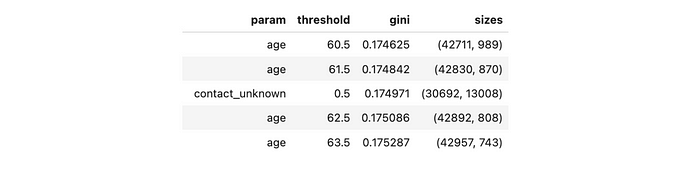
我们还需要讨论的最后一个问题是停止条件。在我们的初始示例中,我们使用了两个条件:
max_depth = 2——它只是限制了树的最大深度,min_samples_leaf = 1000防止我们得到少于1K样本的叶节点。由于这个条件,我们选择了contact_unknown的二元分裂,尽管age导致了更低的Gini系数。
此外,我通常会限制min_impurity_decrease,这样如果收益太小,我们就不会继续下去。所谓收益,是指Gini系数的减少。
所以,我们已经了解了决策树分类器的工作原理,现在是时候在实践中使用它了。
如果你想详细了解决策树回归器的工作原理,你可以查阅我的上一篇文章。
4、决策树:实践
我们已经构建了一个简单的两层树模型,但这肯定不够,因为它太简单了,无法从数据中获得所有见解。让我们通过限制叶节点的样本数量和减少不纯度(减少Gini系数)来训练另一个决策树。
model = sklearn.tree.DecisionTreeClassifier(
min_samples_leaf = 1000, min_impurity_decrease=0.001)
model.fit(fin_df[features], fin_df['y'])
dot_data = sklearn.tree.export_graphviz(
model, out_file=None, feature_names = features, filled = True,
proportion = True, precision=2, impurity = True)
graph = graphviz.Source(dot_data)
# 将图形保存为png文件
png_bytes = graph.pipe(format='png')
with open('decision_tree.png','wb') as f:
f.write(png_bytes)
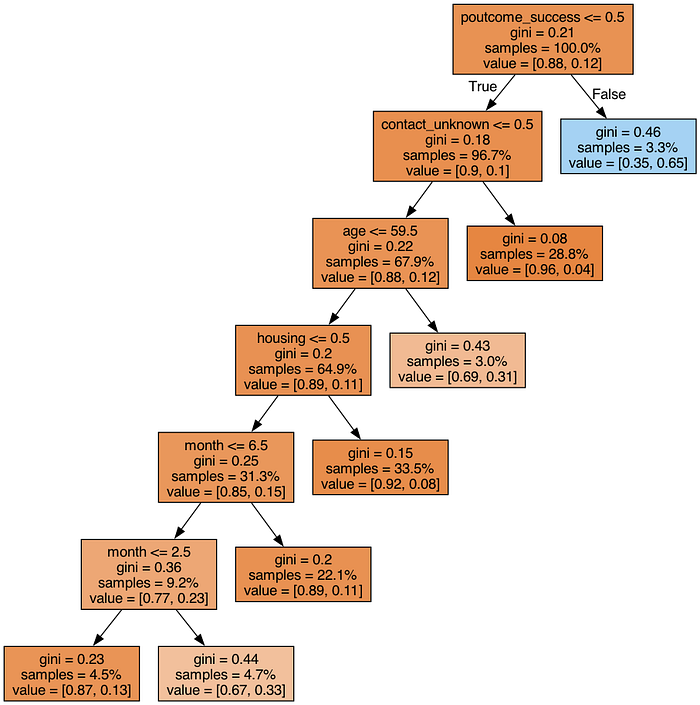
就这样。我们得到了用于将客户分成组(叶节点)的规则。现在,我们可以遍历这些组并查看我们想要联系哪些客户群。尽管我们的模型相对较小,但复制图像中的所有条件还是令人望而生畏。幸运的是,我们可以解析树结构,并从模型中获取所有组。
决策树分类器有一个属性tree_,这将允许我们访问树的底层属性,例如node_count。
n_nodes = model.tree_.node_count
print(n_nodes)
# 13
tree_变量还存储了整个树结构的并行数组,其中第i个元素存储了关于节点i的信息。对于根节点i等于0。
以下是表示树结构的数组:
children_left和children_right——左右节点的ID;如果是叶节点,则为-1。feature——用于分割节点i的特征。threshold——用于节点i二元分割的阈值。n_node_samples——到达节点i的训练样本数。values——每个类别的样本份额。
让我们保存所有这些数组。
children_left = model.tree_.children_left
# [ 1, 2, 3, 4, 5, 6, -1, -1, -1, -1, -1, -1, -1]
children_right = model.tree_.children_right
# [12, 11, 10, 9, 8, 7, -1, -1, -1, -1, -1, -1, -1]
features = model.tree_.feature
# [30, 34, 0, 3, 6, 6, -2, -2, -2, -2, -2, -2, -2]
thresholds = model.tree_.threshold
# [ 0.5, 0.5, 59.5, 0.5, 6.5, 2.5, -2. , -2. , -2. , -2. , -2. , -2. , -2. ]
num_nodes = model.tree_.n_node_samples
# [45211, 43700, 30692, 29328, 14165, 4165, 2053, 2112, 10000,
# 15163, 1364, 13008, 1511]
values = model.tree_.value
# [[[0.8830152 , 0.1169848 ]],
# [[0.90135011, 0.09864989]],
# [[0.87671054, 0.12328946]],
# [[0.88550191, 0.11449809]],
# [[0.8530886 , 0.1469114 ]],
# [[0.76686675, 0.23313325]],
# [[0.87043351, 0.12956649]],
# [[0.66619318, 0.33380682]],
# [[0.889 , 0.111 ]],
# [[0.91578184, 0.08421816]],
# [[0.68768328, 0.31231672]],
# [[0.95948647, 0.04051353]],
# [[0.35274653, 0.64725347]]]
对我们来说,以层次视图的形式处理树结构会更方便,所以让我们遍历所有节点,并为每个节点保存父节点ID以及它是左分支还是右分支。
hierarchy = {}
for node_id in range(n_nodes):
if children_left[node_id] != -1:
hierarchy[children_left[node_id]] = {
'parent': node_id,
'condition': 'left'
}
if children_right[node_id] != -1:
hierarchy[children_right[node_id]] = {
'parent': node_id,
'condition': 'right'
}
print(hierarchy)
# {1: {'parent': 0, 'condition': 'left'},
# 12: {'parent': 0, 'condition': 'right'},
# 2: {'parent': 1, 'condition': 'left'},
# 11: {'parent': 1, 'condition': 'right'},
# 3: {'parent': 2, 'condition': 'left'},
# 10: {'parent': 2, 'condition': 'right'},
# 4: {'parent': 3, 'condition': 'left'},
# 9: {'parent': 3, 'condition': 'right'},
# 5: {'parent': 4, 'condition': 'left'},
# 8: {'parent': 4, 'condition': 'right'},
# 6: {'parent': 5, 'condition': 'left'},
# 7: {'parent': 5, 'condition': 'right'}}
下一步是过滤掉叶节点,因为它们是终端节点,也是我们最感兴趣的节点,因为它们定义了客户细分。
leaves = []
for node_id in range(n_nodes):
if (children_left[node_id] == -1) and (children_right[node_id] == -1):
leaves.append(node_id)
print(leaves)
# [6, 7, 8, 9, 10, 11, 12]
leaves_df = pd.DataFrame({'node_id': leaves})
下一步是确定应用于每个组的所有条件,因为它们将定义我们的客户细分。第一个函数get_condition将为我们提供节点的特征、条件类型和阈值。
def get_condition(node_id, condition, features, thresholds, feature_names):
# print(node_id, condition)
feature = feature_names[features[node_id]]
threshold = thresholds[node_id]
cond = '>' if condition == 'right' else '<='
return (feature, cond, threshold)
print(get_condition(0, 'left', features, thresholds, feature_names))
# ('poutcome_success', '<=', 0.5)
print(get_condition(0, 'right', features, thresholds, feature_names))
# ('poutcome_success', '>', 0.5)
下一个函数将允许我们从叶节点递归地向上遍历并获取所有二元分裂。
def get_decision_path_rec(node_id, decision_path, hierarchy):
if node_id == 0:
yield decision_path
else:
parent_id = hierarchy[node_id]['parent']
condition = hierarchy[node_id]['condition']
for res in get_decision_path_rec(parent_id, decision_path + [(parent_id, condition)], hierarchy):
yield res
decision_path = list(get_decision_path_rec(12, [], hierarchy))[0]
print(decision_path)
# [(0, 'right')]
fmt_decision_path = list(map(
lambda x: get_condition(x[0], x[1], features, thresholds, feature_names),
decision_path))
print(fmt_decision_path)
# [('poutcome_success', '>', 0.5)]
让我们将递归执行和格式化逻辑保存在一个包装函数中。
def get_decision_path(node_id, features, thresholds, hierarchy, feature_names):
decision_path = list(get_decision_path_rec(node_id, [], hierarchy))[0]
return list(map(lambda x: get_condition(x[0], x[1], features, thresholds,
feature_names), decision_path))
我们已经学会了如何获取每个节点的二元分裂条件。剩下的逻辑就是组合这些条件。
def get_decision_path_string(node_id, features, thresholds, hierarchy,
feature_names):
conditions_df = pd.DataFrame(get_decision_path(node_id, features, thresholds, hierarchy, feature_names))
conditions_df.columns = ['feature', 'condition', 'threshold']
left_conditions_df = conditions_df[conditions_df.condition == '<=']
right_conditions_df = conditions_df[conditions_df.condition == '>']
# 去重
left_conditions_df = left_conditions_df.groupby(['feature', 'condition'], as_index = False).min()
right_conditions_df = right_conditions_df.groupby(['feature', 'condition'], as_index = False).max()
# 合并
fin_conditions_df = pd.concat([left_conditions_df, right_conditions_df])\
.sort_values(['feature', 'condition'], ascending = False)
# 格式化
fin_conditions_df['cond_string'] = list(map(
lambda x, y, z: '(%s %s %.2f)' % (x, y, z),
fin_conditions_df.feature,
fin_conditions_df.condition,
fin_conditions_df.threshold
))
return ' and '.join(fin_conditions_df.cond_string.values)
print(get_decision_path_string(12, features, thresholds, hierarchy,
feature_names))
# (poutcome_success > 0.50)
现在,我们可以计算每个组的条件。
leaves_df['condition'] = leaves_df['node_id'].map(
lambda x: get_decision_path_string(x, features, thresholds, hierarchy,
feature_names)
)
最后一步是添加它们的大小和转换到组中。
leaves_df['total'] = leaves_df.node_id.map(lambda x: num_nodes[x])
leaves_df['conversion'] = leaves_df['node_id'].map(lambda x: values[x][0][1])*100
leaves_df['converted_users'] = (leaves_df.conversion * leaves_df.total)\
.map(lambda x: int(round(x/100)))
leaves_df['share_of_converted'] = 100*leaves_df['converted_users']/leaves_df['converted_users'].sum()
leaves_df['share_of_total'] = 100*leaves_df['total']/leaves_df['total'].sum()
现在,我们可以使用这些规则做出决策。我们可以按转换率(成功联系的概率)对组进行排序,并选择具有最高概率的客户。
leaves_df.sort_values('conversion', ascending = False)\
.drop('node_id', axis = 1).set_index('condition')
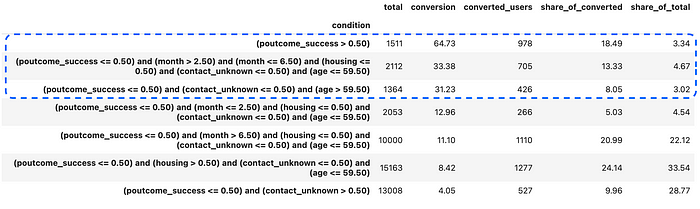
假设我们只能联系大约10%的用户基础,我们可以专注于前三个组。即使在这样的有限能力下,我们预计也会获得接近40%的转换率——这是一个非常好的结果,而且我们只用了几个简单的启发式方法就实现了这一点。
在现实生活中,部署生产环境之前测试模型(或启发式方法)也是值得的。我会将训练数据集拆分为训练集和验证集(按时间划分以避免泄漏),并在验证集上查看启发式的性能,以更好地了解实际模型的质量。
5、处理高基数类别
在这个上下文中值得讨论的另一个主题是类别编码,因为我们必须对sklearn实现中的分类变量进行编码。我们已经使用了一种简单的独热编码方法,但在某些情况下这种方法不起作用。
想象一下,我们还有数据中的地区。我人为地为每一行生成了英国城市。我们有155个独特的地区,因此特征数量增加到了190。
model = sklearn.tree.DecisionTreeClassifier(min_samples_leaf = 100, min_impurity_decrease=0.001)
model.fit(fin_df[feature_names], fin_df['y'])
所以,基本树现在有很多基于地区的条件,处理起来不方便。
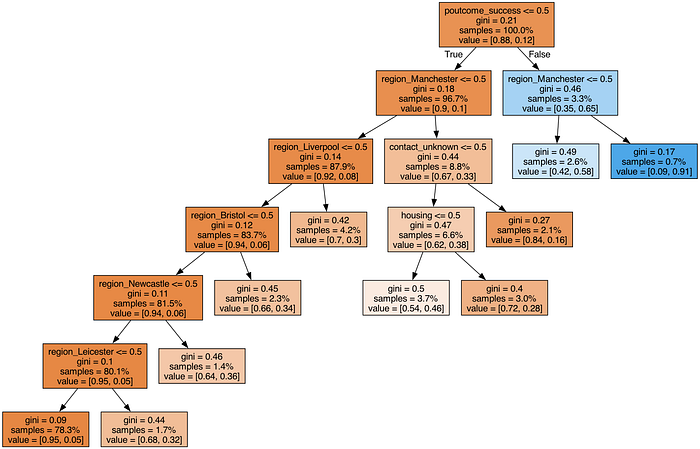
在这种情况下,扩展特征数量可能没有意义,是时候考虑编码了。有一篇综合文章,《“Categorically: 不要爆炸——编码!”》(“Categorically: Don't explode — encode!”),分享了许多处理高基数分类变量的不同选项。我认为在我们的情况下,以下两种方法最有可行性:
- 计数或频率编码,在基准测试中表现良好。这种编码假设大小相似的类别具有相似的特性。
- 目标编码,我们可以根据目标变量的平均值对类别进行编码。这将使我们优先考虑转化率高的细分市场,并降低转化率低的细分市场的优先级。理想情况下,最好使用历史数据来获取编码的平均值,但我们将在现有数据集上进行操作。
然而,测试不同的方法也很有趣,所以让我们将数据集拆分为训练集和测试集,保留10%用于验证。为了简单起见,我为除地区外的所有列使用了独热编码(因为地区具有最高的基数)。
from sklearn.model_selection import train_test_split
fin_df = pd.get_dummies(df, columns=['job', 'marital', 'education',
'poutcome', 'contact'], dtype = int, drop_first = False)
train_df, test_df = train_test_split(fin_df,test_size=0.1, random_state=42)
print(train_df.shape[0], test_df.shape[0])
# (40689, 4522)
为了方便起见,让我们将解析树的所有逻辑整合到一个函数中。
def get_model_definition(model, feature_names):
n_nodes = model.tree_.node_count
children_left = model.tree_.children_left
children_right = model.tree_.children_right
features = model.tree_.feature
thresholds = model.tree_.threshold
num_nodes = model.tree_.n_node_samples
values = model.tree_.value
hierarchy = {}
for node_id in range(n_nodes):
if children_left[node_id] != -1:
hierarchy[children_left[node_id]] = {
'parent': node_id,
'condition': 'left'
}
if children_right[node_id] != -1:
hierarchy[children_right[node_id]] = {
'parent': node_id,
'condition': 'right'
}
leaves = []
for node_id in range(n_nodes):
if (children_left[node_id] == -1) and (children_right[node_id] == -1):
leaves.append(node_id)
leaves_df = pd.DataFrame({'node_id': leaves})
leaves_df['condition'] = leaves_df['node_id'].map(
lambda x: get_decision_path_string(x, features, thresholds, hierarchy, feature_names)
)
leaves_df['total'] = leaves_df.node_id.map(lambda x: num_nodes[x])
leaves_df['conversion'] = leaves_df['node_id'].map(lambda x: values[x][0][1])*100
leaves_df['converted_users'] = (leaves_df.conversion * leaves_df.total).map(lambda x: int(round(x/100)))
leaves_df['share_of_converted'] = 100*leaves_df['converted_users']/leaves_df['converted_users'].sum()
leaves_df['share_of_total'] = 100*leaves_df['total']/leaves_df['total'].sum()
leaves_df = leaves_df.sort_values('conversion', ascending = False)\
.drop('node_id', axis = 1).set_index('condition')
leaves_df['cum_share_of_total'] = leaves_df['share_of_total'].cumsum()
leaves_df['cum_share_of_converted'] = leaves_df['share_of_converted'].cumsum()
return leaves_df
让我们创建一个编码数据框,计算频率和转化率。
region_encoding_df = train_df.groupby('region', as_index = False)\
.aggregate({'id': 'count', 'y': 'mean'}).rename(columns =
{'id': 'region_count', 'y': 'region_target'})
然后,将其合并到我们的训练集和验证集中。对于验证集,我们还将用均值填充缺失值。
train_df = train_df.merge(region_encoding_df, on = 'region')
test_df = test_df.merge(region_encoding_df, on = 'region', how = 'left')
test_df['region_target'] = test_df['region_target']\
.fillna(region_encoding_df.region_target.mean())
test_df['region_count'] = test_df['region_count']\
.fillna(region_encoding_df.region_count.mean())
现在,我们可以拟合模型并获取它们的结构。
count_feature_names = train_df.drop(
['y', 'id', 'region_target', 'region'], axis = 1).columns
target_feature_names = train_df.drop(
['y', 'id', 'region_count', 'region'], axis = 1).columns
print(len(count_feature_names), len(target_feature_names))
# (36, 36)
count_model = sklearn.tree.DecisionTreeClassifier(min_samples_leaf = 500,
min_impurity_decrease=0.001)
count_model.fit(train_df[count_feature_names], train_df['y'])
target_model = sklearn.tree.DecisionTreeClassifier(min_samples_leaf = 500,
min_impurity_decrease=0.001)
target_model.fit(train_df[target_feature_names], train_df['y'])
count_model_def_df = get_model_definition(count_model, count_feature_names)
target_model_def_df = get_model_definition(target_model, target_feature_names)
让我们看看结构并选择前几类,占我们目标受众的10-15%。我们还可以将这些条件应用于验证集以在实践中测试我们的方法。
让我们从计数编码开始。
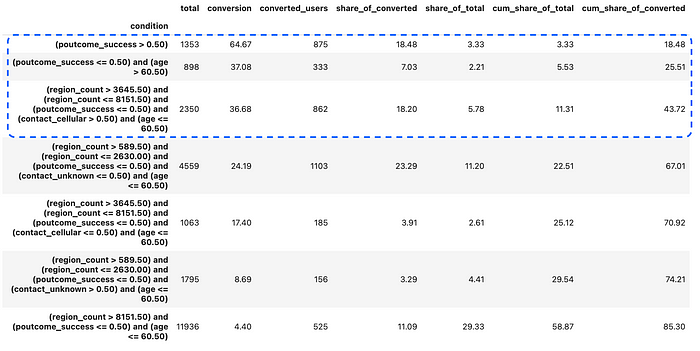
count_selected_df = test_df[
(test_df.poutcome_success > 0.50) |
((test_df.poutcome_success <= 0.50) & (test_df.age > 60.50)) |
((test_df.region_count > 3645.50) & (test_df.region_count <= 8151.50) &
(test_df.poutcome_success <= 0.50) & (test_df.contact_cellular > 0.50) & (test_df.age <= 60.50))
]
print(count_selected_df.shape[0], count_selected_df.y.sum())
# (508, 227)
我们还可以看看选中的地区,只有曼彻斯特。
region_encoding_df[(region_encoding_df.region_count > 3645.50)
& (region_encoding_df.region_count <= 8151.50)]

让我们继续使用目标编码。
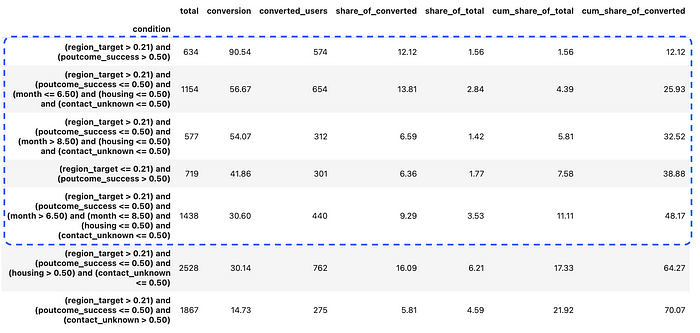
target_selected_df = test_df[
((test_df.region_target > 0.21) & (test_df.poutcome_success > 0.50)) |
((test_df.region_target > 0.21) & (test_df.poutcome_success <= 0.50) & (test_df.month <= 6.50) & (test_df.housing <= 0.50) & (test_df.contact_unknown <= 0.50)) |
((test_df.region_target > 0.21) & (test_df.poutcome_success <= 0.50) & (test_df.month > 8.50) & (test_df.housing <= 0.50)
& (test_df.contact_unknown <= 0.50)) |
((test_df.region_target <= 0.21) & (test_df.poutcome_success > 0.50)) |
((test_df.region_target > 0.21) & (test_df.poutcome_success <= 0.50) & (test_df.month > 6.50) & (test_df.month <= 8.50)
& (test_df.housing <= 0.50) & (test_df.contact_unknown <= 0.50))
]
print(target_selected_df.shape[0], target_selected_df.y.sum())
# (502, 248)
我们看到选择用于通信的用户数量略少,但转化数量显著增加:248 vs. 227(+9.3%)。
让我们看看选中的类别。我们看到模型挑选出了所有转化率高的城市(曼彻斯特、利物浦、布里斯托尔、莱斯特和纽卡斯尔),但也有一些小地区由于偶然因素转化率很高。
region_encoding_df[region_encoding_df.region_target > 0.21]\
.sort_values('region_count', ascending = False)
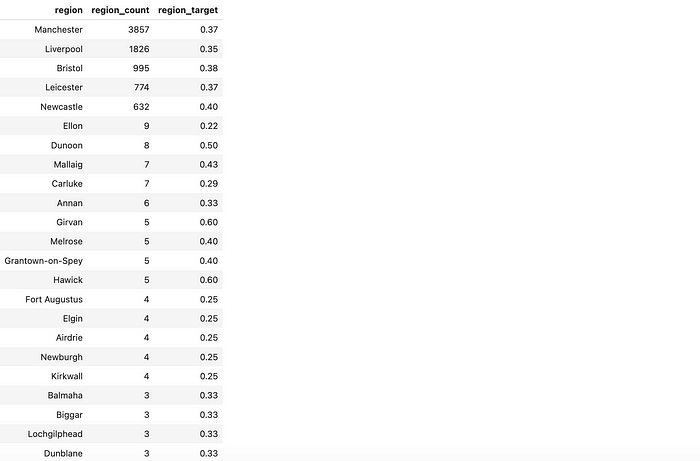
在我们的案例中,这影响不大,因为这些小城市的份额较低。然而,如果你有更多的小类别,你可能会看到过拟合的显著缺点。目标编码在这个点上可能很棘手,所以要注意你的模型的输出。
幸运的是,有一种方法可以帮助你解决这个问题。按照“编码分类变量:深入探究目标编码”一文,我们可以添加平滑处理。其理念是将群组的转化率与整体平均值相结合:群组越大,其数据的权重就越大,而群组越小,其数据则更倾向于整体平均值。
首先,我选择了一些适合我们分布的参数,并考察了多种方案。对于人数少于 100 人的群组,我选择使用整体平均值。这部分操作比较主观,因此请运用常识和您对业务领域的了解。
import numpy as np
import matplotlib.pyplot as plt
global_mean = train_df.y.mean()
k = 100
f = 10
smooth_df = pd.DataFrame({'region_count':np.arange(1, 100001, 1) })
smooth_df['smoothing'] = (1 / (1 + np.exp(-(smooth_df.region_count - k) / f)))
ax = plt.scatter(smooth_df.region_count, smooth_df.smoothing)
plt.xscale('log')
plt.ylim([-.1, 1.1])
plt.title('Smoothing')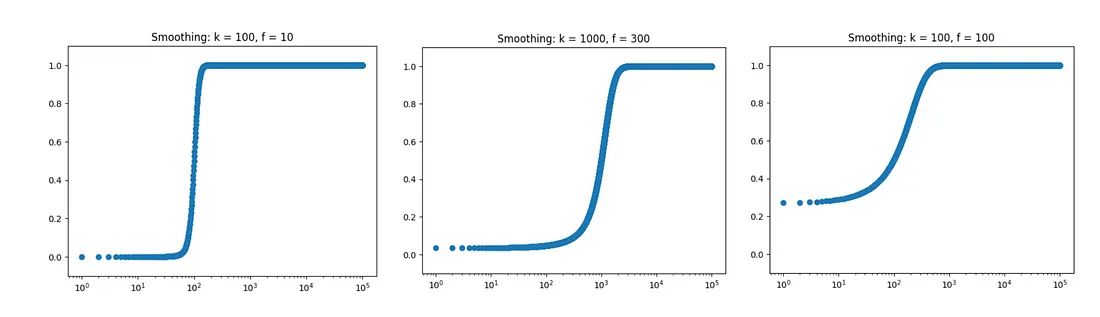
然后,我们可以根据选定的参数计算平滑系数和混合平均值。
region_encoding_df['smoothing'] = (1 / (1 + np.exp(-(region_encoding_df.region_count - k) / f)))
region_encoding_df['region_target'] = region_encoding_df.smoothing * region_encoding_df.raw_region_target \
+ (1 - region_encoding_df.smoothing) * global_mean然后,我们可以拟合另一个具有平滑目标类别编码的模型。
train_df = train_df.merge(region_encoding_df[['region', 'region_target']], on = 'region')
test_df = test_df.merge(region_encoding_df[['region', 'region_target']], on = 'region', how = 'left')
test_df['region_target'] = test_df['region_target']\
.fillna(region_encoding_df.region_target.mean())
target_v2_feature_names = train_df.drop(['y', 'id', 'region'], axis = 1).columns
target_v2_model = sklearn.tree.DecisionTreeClassifier(min_samples_leaf = 500,
min_impurity_decrease=0.001)
target_v2_model.fit(train_df[target_v2_feature_names], train_df['y'])
target_v2_model_def_df = get_model_definition(target_v2_model, target_v2_feature_names)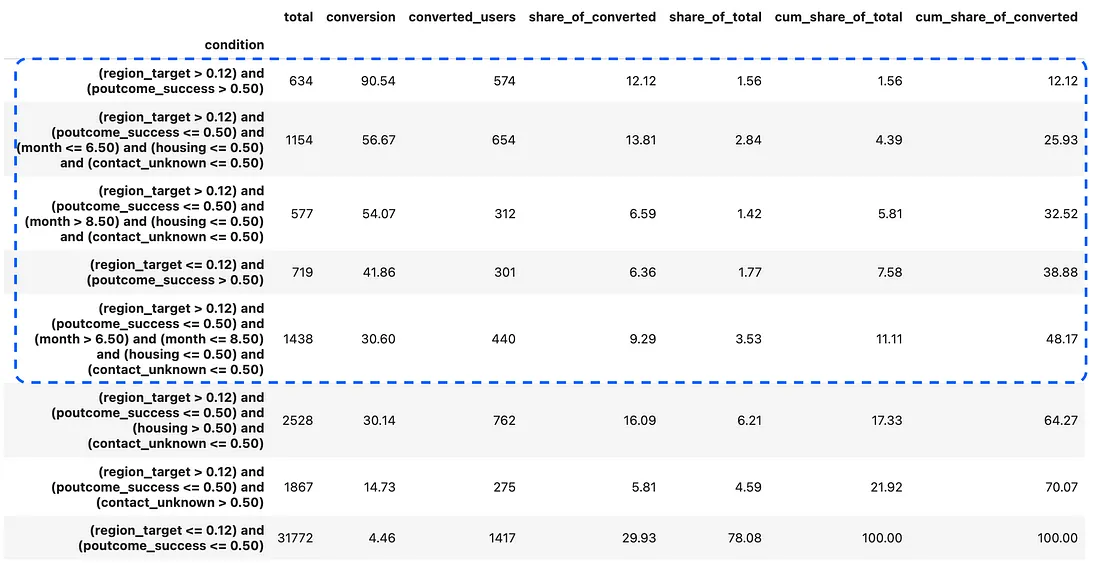
target_v2_selected_df = test_df[
((test_df.region_target > 0.12) & (test_df.poutcome_success > 0.50)) |
((test_df.region_target > 0.12) & (test_df.poutcome_success <= 0.50) & (test_df.month <= 6.50) & (test_df.housing <= 0.50) & (test_df.contact_unknown <= 0.50)) |
((test_df.region_target > 0.12) & (test_df.poutcome_success <= 0.50) & (test_df.month > 8.50) & (test_df.housing <= 0.50)
& (test_df.contact_unknown <= 0.50)) |
((test_df.region_target <= 0.12) & (test_df.poutcome_success > 0.50) ) |
((test_df.region_target > 0.12) & (test_df.poutcome_success <= 0.50) & (test_df.month > 6.50) & (test_df.month <= 8.50)
& (test_df.housing <= 0.50) & (test_df.contact_unknown <= 0.50) )
]
target_v2_selected_df.shape[0], target_v2_selected_df.y.sum()
# (500, 247)我们可以看到,我们剔除了小城市,避免了模型过度拟合,同时保持了大致相同的性能,捕获了 247 次转化。
region_encoding_df[region_encoding_df.region_target > 0.1173]你也可以使用 sklearn 的 TargetEncoder,它会根据数据段大小对类别和全局均值进行平滑和混合。但是,它也会添加随机噪声,这对于我们的启发式案例来说并不理想。

你可以在 GitHub 上找到完整代码。
6、结束语
在本文中,我们探讨了如何从数据中提取简单的“规则”,并将其用于业务决策。我们使用决策树分类器生成了启发式方法,并探讨了分类编码这一重要主题,因为决策树算法需要转换分类变量。
我们发现这种基于规则的方法效果惊人,可以帮助你快速做出业务决策。然而,值得注意的是,这种过于简单的方法也有其缺点:
我们牺牲了模型的强大功能和准确性来换取其简单性和可解释性,因此如果您要优化准确性,请选择其他方法。
即使我们使用一组静态启发式方法,您的数据仍然会发生变化,并且可能会过时,因此您需要不时重新检查您的模型。
汇智网翻译整理,转载请标明出处
