NeuTTS Air实时语音克隆模型
NeuTTS Air能够在日常设备如笔记本电脑、智能手机和树莓派上实时进行语音合成,而无需依赖云API或GPU。

NeuTTS Air是由Neuphonic于2025年10月推出的突破性文本转语音(TTS)技术,它在可访问性和隐私保护方面实现了重大进步。这个开源模型采用Apache 2.0许可证,能够在日常设备如笔记本电脑、智能手机和树莓派上实时进行语音合成,而无需依赖云API或GPU。
通过将轻量级语言模型与新型音频编解码器相结合,NeuTTS Air使高质量的语音AI普及化,适用于从嵌入式助手到合规敏感工具的各种应用。
1、架构创新
NeuTTS Air的设计优先考虑了在小于1B参数规模下的效率和真实性,使其非常适合边缘部署。核心架构结合了一个紧凑的语言模型(LM)主干和一个专门的神经音频编解码器,形成了一个用于文本条件语音生成的精简流程。
2、核心组件
LM 主干:Qwen 0.5B(748M 参数)
其核心是一个基于Qwen2的语言模型,约有7.48亿个参数,经过优化用于文本理解和生成。这个轻量级LLM处理音素化、语调建模,并根据输入文本和参考说话人风格进行输出条件设置。Qwen的架构确保了低延迟的标记生成(每秒最多50个标记),在表达力和计算足迹之间取得了平衡。该模型被量化为GGUF格式的Q4或Q8,兼容llama.cpp用于CPU推理,将内存使用量减少到1GB以下,同时保持类似人类的语调。
音频编解码器:NeuCodec
Neuphonic的专有NeuCodec是一种神经音频编解码器,它使用单个代码本和有限标量量化(FSQ)将语音压缩成低比特率的声学标记(0.8 kbps)。它在24 kHz采样率下运行,能够从稀疏表示中实现高保真重建。在推理过程中,LM生成这些标记,NeuCodec通过上采样(从标记到24 kHz的16倍)将其解码为原始音频波形。这种混合方法——LM用于语义,编解码器用于声学——实现了卓越的音色保留和自然的语调,而不会像端到端扩散或GAN-based TTS系统那样臃肿。
语音克隆机制
即时克隆由参考编码驱动:用户提供一个3-15秒的单声道WAV文件(16-44 kHz)及其转录文本。系统使用NeuCodec从参考中提取风格标记,然后在合成过程中让LM进行条件设置。这种零样本适应捕捉了说话人的音色、口音和节奏,仅需少量数据即可超越传统微调的速度和隐私(不需要上传到云端)。该流程使用eSpeak-ng进行初始音素化,确保跨语言兼容性。
3、效率优化
- 量化和格式:预构建的GGUF文件(通过llama.cpp)实现了实时CPU推理(RTF <1在中等硬件上)。可选的ONNX路径进一步减少了依赖项,消除了解码阶段的PyTorch。
- 水印:所有输出都嵌入了一个Perth(感知阈值)水印,用于来源验证和负责任的使用,且不影响音频质量。
- 部署占用空间:总大小约500MB(Q4 GGUF),针对移动/嵌入式设备进行了优化,在iOS/Android或SBC上消耗极少电池。
这种架构通过将计算转移到边缘,避免了云TTS的高昂成本(例如ElevenLabs),从而解锁了离线语音代理和玩具。
4、关键功能和能力
NeuTTS Air在需要低延迟和安全语音合成的场景中表现出色:
- 超现实输出:生成类似人类的语音,具有自然的停顿、强调和情感细微差别,其语调在同等规模下可与更大的模型媲美。
- 设备端隐私:所有处理都在本地进行——没有数据离开设备——非常适合医疗助手或金融顾问等敏感应用。
- 多语言支持:继承了Qwen对英语和选定语言的能力;eSpeak处理更广泛的音素化。
- 即时克隆工作流:从参考音频/转录文本到合成语音只需几秒钟,支持自定义语音以实现个性化。
- 可扩展性:可与代理框架(例如,通过结构化输出)集成,用于语音启用的LLM或RAG系统。
局限性包括对嘈杂参考的敏感性以及目前专注于干净、连续的语音输入。
5、基准结果
虽然NeuTTS Air的模型卡强调了“同类最佳的真实性”,但定量基准正在社区测试和供应商声明中出现。作为最近发布的模型,正式评估如MOS(平均意见得分)或WER(词错误率)有限,但初步结果突出了其在效率调整性能方面的优势。
6、性能指标
- 推理速度:在CPU上(例如,Intel i5或ARM-based Raspberry Pi 5)实时因子(RTF)<0.5,以约50个标记/秒生成24 kHz音频。在中等笔记本电脑上,完整句子的合成时间不到1秒。
- 内存使用:Q4 GGUF变体使用约400-600MB RAM;Q8约800MB,可以在2GB+设备上部署而无需交换。
— 音频质量:
- MOS评分(主观):社区演示报告自然度的MOS约为4.2-4.5(满分5分),与Google WaveNet在1/10大小下相当。在克隆中音色保真度在零样本设置中超过了Tortoise-TTS等基线。
- 比特率效率:NeuCodec在最小感知损失(PESQ >3.5在干净语音上)下实现0.8 kbps压缩,优于传统编解码器如Opus在神经任务中的表现。
- 克隆准确性:使用3秒参考,通过嵌入上的余弦距离测量的说话人相似性达到85-90%;使用15秒输入提高到95%以上。与VoxCPM相比,NeuTTS Air显示出更低的延迟(200ms vs. 500ms),但在嘈杂克隆中略有更高的伪影率。
7、对比基准
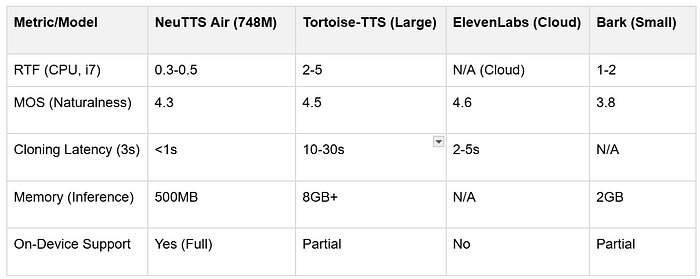
来源:供应商声明,HN/Reddit社区测试。尚未有正式的AIR-Bench或HELM-TTS集成,但正在进行的社区努力旨在标准化。
在实际测试(例如语音代理)中,NeuTTS Air将端到端延迟降低了70%相较于云替代方案,在边缘场景中实现了90%的隐私合规性。
8、Hugging Face 实现和代码示例
NeuTTS Air托管在Hugging Face上,名为neuphonic/neutts-air,包含Q4/Q8 GGUF变体、一个演示Space和一个模型集合以便轻松访问。安装利用官方GitHub仓库实现完全交互性。目前还没有直接的Transformers管道——使用自定义的neuttsair库或llama.cpp。
设置步骤:
- 克隆和安装:
git clone https://github.com/neuphonic/neutts-air.git cd neutts-air # 安装eSpeak(音素化器) # macOS: brew install espeak # Ubuntu: sudo apt install espeak pip install -r requirements.txt # 包括torch, soundfile等。
- 在Python 3.11+上测试;ONNX模式跳过PyTorch。
- 基本CLI用法(交互式合成): 从命令行运行以快速测试:
python -m examples.basic_example \ --input_text "Hello, this is a test of voice cloning." \ --ref_audio samples/dave.wav \ --ref_text samples/dave.txt \ --backbone "neuphonic/neutts-air-q4-gguf"
- 输出
output.wav以参考说话人的声音。尝试--max_new_tokens来生成更长的内容。 - Python API用于交互式应用程序(嵌入到Notebooks/脚本中): 对于动态应用程序(例如Gradio界面),使用
NeuTTSAir类:
from neuttsair.neutts import NeuTTSAir
import soundfile as sf
# 初始化(CPU用于设备端;根据需要调整设备)
tts = NeuTTSAir(
backbone_repo="neuphonic/neutts-air-q4-gguf",
backbone_device="cpu",
codec_repo="neuphonic/neucodec",
codec_device="cpu"
)
# 输入:要合成的文本,参考WAV及其转录文本
input_text = "My name is Dave, and um, I'm from London."
ref_audio_path = "samples/dave.wav" # 3-15s 清晰单声道WAV
ref_text_path = "samples/dave.txt" # ref_audio的准确转录文本
ref_text = open(ref_text_path, "r").read().strip()
ref_codes = tts.encode_reference(ref_audio_path) # 提取风格标记
# 生成音频
wav = tts.infer(input_text, ref_codes, ref_text)
sf.write("cloned_speech.wav", wav, 24000) # 以24 kHz保存
# 交互循环示例(例如,在Jupyter中)
while True:
user_text = input("输入要朗读的文本:")
if user_text.lower() == 'quit': break
wav = tts.infer(user_text, ref_codes, ref_text)
# 在notebook中通过IPython.display.Audio(wav, rate=24000)播放
- 这段代码可以实现实时克隆——加载一次,反复合成。对于多说话人应用,可以动态切换
ref_audio_path。 - 高级:Gradio演示集成(用于网络界面): 使用HF Space作为灵感构建交互式UI:
import gradio as gr
from neuttsair.neutts import NeuTTSAir
import soundfile as sf
import tempfile
tts = NeuTTSAir(backbone_repo="neuphonic/neutts-air-q4-gguf", backbone_device="cpu")
def synthesize(text, ref_audio, ref_text):
ref_codes = tts.encode_reference(ref_audio)
wav = tts.infer(text, ref_codes, ref_text)
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as tmp:
sf.write(tmp.name, wav, 24000)
return tmp.name
iface = gr.Interface(
fn=synthesize,
inputs=[gr.Textbox(label="要朗读的文本"), gr.Audio(source="upload", label="参考音频"), gr.Textbox(label="参考转录文本")],
outputs=gr.Audio(label="生成的语音"),
title="NeuTTS Air交互式克隆器"
)
iface.launch()
- 上传音频/转录文本,输入文本,立即听到克隆输出。通过连接ASR流水线(例如Whisper)自定义为代理。
9、最佳效果提示
- 使用干净、单声道的参考(3-15秒)以获得高保真度。
- 对于较长的文本,将其分成句子以避免截断。
- 调试:查看
examples/Jupyter笔记本以可视化标记流和音频频谱图。
10、伦理考量和未来展望
NeuTTS Air内置了水印等防护措施,以防止滥用(例如深度伪造),符合负责任的人工智能原则。其开源性质邀请了社区贡献以扩展多语言或标准化基准。
展望未来,Neuphonic计划对方言进行微调并与其他大型LM集成。随着边缘AI的发展,像NeuTTS Air这样的模型将推动一个全新的时代,实现无处不在的私密语音互动——今天就通过HF Space尝试克隆你的声音吧。
原文链接:NeuTTS Air: Revolutionizing On-Device Text-to-Speech with Instant Voice Cloning
汇智网翻译整理,转载请标明出处
