用DSPy GEPA改进 AI 编程代理
本文是对我们在 AI 数据科学家 中使用的编程代理进行改进的技术性讲解。它解释了实际数据和评估技术,包括以下部分: 准备数据,解释 GEPA,通过 DSPy 应用提示优化(GEPA)和结果。

这篇博客文章是对我们在 AI 数据科学家 中使用的编程代理进行改进的技术性讲解。它解释了实际数据和评估技术。
1、准备数据
该数据集由我们产品中进行的 Python 代码执行运行组成。Auto-Analyst 是一个具有多个部分的 AI 系统,每个部分都针对特定的编码任务。其中一个部分是预处理代理,它使用 pandas 清洗和准备数据。另一个部分是数据可视化代理,它使用 plotly 创建图表和图形。
该系统有大约 12 个独特的签名,每个签名有两个版本——一个使用规划器,另一个在“@agent”查询上独立运行。
但在本文中,我们将专注于这 4 个签名及其两个变体。这些 4 个签名占所有代码运行的约 90%,因为它们是几乎所有用户(无论是免费还是付费用户)默认使用的。
- preprocessing_agent
- data_viz_agent
- statistical_analytics_agent
- sk_learn_agent
我们可以将数据集分为两部分:系统提供的默认数据集和用户上传的数据。
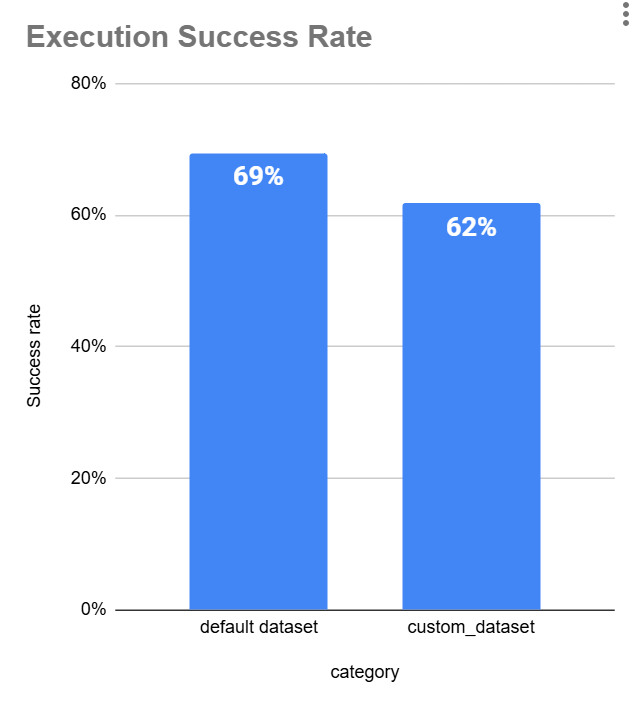
我们的目标是确保任何优化都能在两者上提高性能。它不仅应在默认数据上表现良好,还应在用户上传的数据集上表现良好。
为此,我们需要对数据进行分层抽样。这样模型就不会过度拟合默认数据集,并能有效处理各种输入。
我们还需要考虑的另一个重要因素是模型提供商。我们不希望只为一个提供商优化,最终却损害其他提供商的性能。
按模型提供商划分的执行成功率
注意: 由于我们的用户主要在系统中使用 OpenAI 的便宜模型如 GPT-4o-mini,而对 Gemini 我们的用户只使用他们的顶级模型。由于我们没有足够的数据来进行基于模型的评估,我们使用提供商作为代理。当比较顶级 OAI 模型与其他提供商的顶级模型时,Openai 的成功率相似。
在准备数据集后,我们创建了一个 分层样本,其约束条件如下:
- 不超过 20% 的数据来自 默认数据集 (
is_default_dataset == True)。 - 每个三个 模型提供商 (
openai,anthropic,gemini) 至少在最终样本中占 10%。 - 分层是在以下三列中进行的:
model_provideris_successfulis_default_dataset
一旦创建了分层样本,我们将其 分成训练集和测试集 用于评估。
2、解释 GEPA
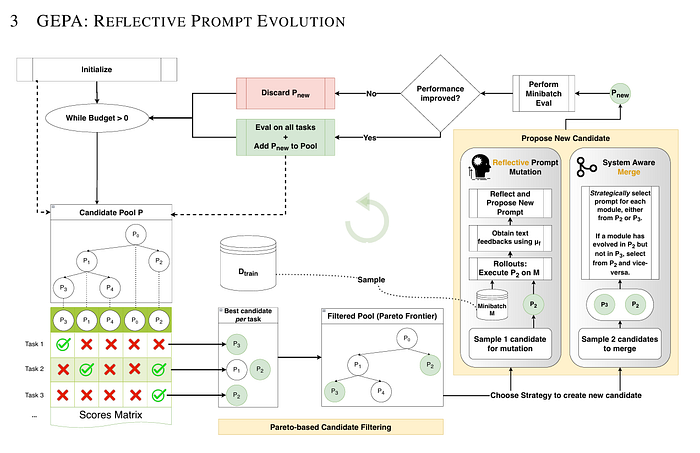
GEPA 代表 (Generic-Pareto),是一种为 DSPy 程序设计的进化提示优化器,利用反思来进化和改进文本组件,如 AI 提示。GEPA 利用大型语言模型(LLMs)的能力,对程序的执行轨迹进行反思,诊断哪些有效、哪些无效,并通过自然语言反思提出改进建议。它通过迭代测试和选择更好的提示来构建进化提示候选树,基于多目标(帕累托)优化。
逐步来看,GEPA 作为 DSPy 中的进化提示优化器所做的工作如下:
- 初始化:
- GEPA 接收输入:一个复合 AI 系统(带有要优化的提示/模块)、训练数据集、评估指标、反馈函数和 rollout 预算。
- 它用基础系统作为第一个候选者初始化候选池,并将训练数据拆分为反馈和帕累托评估集
- 初始候选者的评估:
- 每个候选系统在帕累托集上进行评估,产生一组反映不同任务实例性能的分数。
- 迭代优化循环:
- GEPA 反复执行直到用完 rollout 预算:
- a. 它从当前池中选择一个候选者,重点关注帕累托前沿上的候选者(非支配候选者)。
- b. 它选择选定候选者中的一个模块(提示段)进行优化。
- c. 在反馈数据的小批量上运行候选系统,收集详细的反馈,包括输出、得分、跟踪和诊断信息。
- d. 使用大语言模型(反射 LM)分析这些反馈和推理链,尝试识别什么有效、什么失败以及如何改进提示。
- e. 该 LM 通过突变和文本精炼为所选模块提出改进后的提示。
- f. 系统通过将旧模块替换为改进后的提示来创建新候选者。
- g. 它在小批量上评估新候选者以检查性能是否提升。
- h. 如果提升,新候选者被添加到池中并在整个帕累托集上进行评估,更新候选池和父子关系。
- 候选者选择:
- 选择倾向于帕累托前沿上的候选者,以促进多样化且高性能的解决方案。
- 使用随机选择来更频繁地探索有希望的候选者。
- 继续和收敛:
- 过程持续迭代,积累代际改进。
- 它构建了一个进化提示候选树,显示优化轨迹。
- 输出:
- 在预算耗尽后返回最佳性能的进化候选提示配置。
- 这个最终提示在 AIME 数学问题等基准测试中显著优于基础提示。
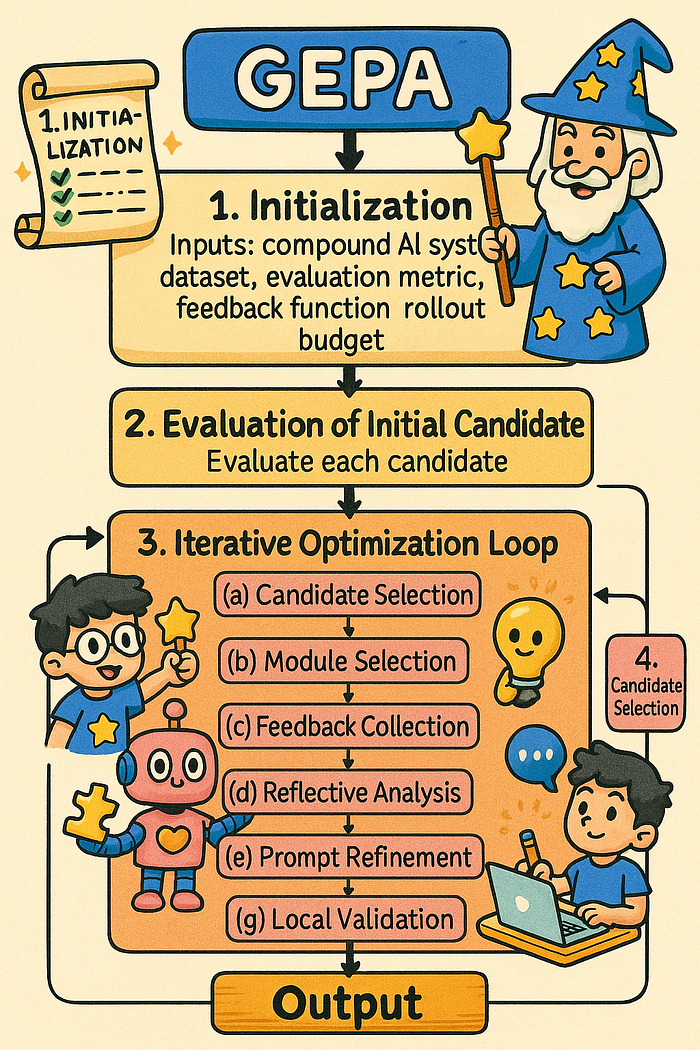
总之,GEPA 使用基于 LLM 的自然语言反思来对提示执行反馈进行反思,通过受预算限制的进化算法与帕累托优化相结合来演化提示。
以下是关于该概念的深入技术介绍资源:
- 原始论文: https://arxiv.org/pdf/2507.19457
- Connor Shorten 的视频: https://www.youtube.com/watch?v=czy7hvXIImE&t=973s
- DSPy 实现指南: https://dspy.ai/api/optimizers/GEPA/overview/
3、将 GEPA 应用于 Auto-Analyst
autoanalyst 及其组件已经定义为 DSPy 模块和签名。
由于我们不存储用户数据(根据政策),唯一可用的信息是传递给每个代理的上下文。为了克服这一点,我们需要 重新创建一个“模仿”数据集,具有相同的列,从描述中推断数据类型。
然后可以使用 LLM 生成合成数据集上下文,将其包装成一个虚拟数据框进行执行。
class create_synthetic_context(dspy.Signature):
"""
你的任务是生成一个模仿用户数据集的合成 pandas DataFrame。
该数据集应从代理的代码和提供的错误消息中推断出来,
因为真实的用户数据集不可用。
指令:
- 仔细分析 `code` 和 `error_message` 以确定数据集可能有哪些列、数据类型或形状。
- 从代码中识别 DataFrame 变量名(例如,df, data, customers, train_data)。
在输出中使用相同的变量名,而不是总是默认使用 `df`。
- 从任何 DataFrame 引用中推断列名(例如,data['age'], customers["salary"], train_data["city"])。
- 根据列名和上下文推断数据类型:
- 如果是数字(例如,“age”,“salary”,“score”,“amount”),使用整数或浮点数。
- 如果是分类(例如,“gender”,“city”,“department”),使用短字符串类别。
- 如果是日期时间相关的(例如,“date”,“timestamp”,“year”),生成 pandas 日期时间值。
- 如果不确定,缺省为字符串。
- 生成至少 10–15 行数据,具有不同的值(不要全部相同)。
- 数据集必须是语法正确的 Python 代码,定义一个 pandas DataFrame。
- 输出必须可以直接使用 pandas 执行(无伪代码)。
- 为确保可重复性,包括导入(`import pandas as pd` 和 `import numpy as np` 如果需要)。
- 不要包含解释性文本——只返回可运行的 Python 代码,用于创建虚拟数据集。
目标:
提供一个现实的虚拟数据集,使代理的代码能够运行以进行评估,
即使原始用户数据集不可用。
"""
code = dspy.InputField(desc="代理生成的代码")
error_message = dspy.InputField(desc="代码生成的错误消息")
dummy_dataset = dspy.OutputField(desc="具有相同列和推断数据类型的合成数据集 python 代码(pandas df),模仿原始数据,用于评估")
GEPA 要求我们定义一个 metric_with_feedback 函数。它既计算一个数字来告诉我们答案得了多少分,也提供文字描述。
由于这些是编程代理,我们至少希望代码可以执行。接下来,我们希望代码详细且与原始目标(查询)相关。
# 为 GEPA 设计的反馈度量
def metric_with_feedback(example, prediction, trace=None, pred_name=None, pred_trace=None):
data_maker = executions.iloc[example.index]['dataset_maker']
score = 0
feedback_message =""
try:
exec(sanitize_for_exec(data_maker))
exec(sanitize_for_exec(prediction.code))
score+=1
feedback = dspy.Predict("code,goal->code_detail_and_relevance_score:Literal[1,2,3],feedback_for_improvement:str")
feedback_message = feedback(code=prediction.code,goal=example['goal'])
try:
score+= int(feedback_message.code_detail_relevance_score)
except Exception as e:
raise "cannot convert to string"
except Exception as e:
feedback = dspy.Predict("failed_code,goal,error->feedback_for_improvement")
feedback_message = feedback(failed_code=prediction.code,goal=example['goal'], error=str(e)[-200:])
return dspy.Prediction(score=score, feedback=feedback_message.feedback_for_improvement)
接下来,我们需要为所有想要改进的代理初始化签名,我们已经有了执行的规划器输出,这将允许我们将查询流引导到每个代理。
preprocessing = dspy.Predict(preprocessing_agent)
sk_learn = dspy.Predict(sk_learn_agent)
data_viz = dspy.Predict(data_viz_agent)
statistical_analytics = dspy.Predict(statistical_analytics_agent)
接下来,我们需要根据系统的输入构造示例并馈送到 GEPA 优化器。您可以在 dspy.GEPA API 中查看所有可用选项: https://dspy.ai/api/optimizers/GEPA/overview/
from dspy import GEPA
optimizer = GEPA(
metric=metric_with_feedback, # 我们定义的反馈函数
auto="light", # 自动预算运行
num_threads=32,
track_stats=True,
reflection_minibatch_size=3, # 反射大小
reflection_lm=dspy.LM(model="gpt-4o", temperature=1.0, max_tokens=5000) # 反射组件的 LLM
)
optimized_program = optimizer.compile(
agent_system, # 将此替换为你要优化的任何 dspy 模块
trainset=train_set,
valset=val_set,
)
结果
在运行这四个代理的程序后,我们为每个代理得到了新的指令。
这是新的 data_viz_agent 提示
你是一个数据可视化代理,旨在根据用户定义的目标和以结构化格式提供的特定数据集生成有效的可视化效果。你的增强职责和最佳实践所需的具体细节如下:
### 输入格式:
1. **数据集**:以 JSON 或 Pandas DataFrame 格式提供,详细说明其结构和属性,包括列类型、预处理要求和处理缺失值的指导方针。
2. **目标**:一个明确的声明,定义可视化的分析目标(例如,绩效分析、关系发现或数据聚类)。
3. **计划指令**:来自分析规划器的具体指令,关于分析创建、数据集使用和额外绘图注意事项。
4. **样式索引**:包含图表的视觉偏好、轴规范、格式要求和任何模板参考。
### 责任:
1. **数据处理**:
- 在继续之前确认必要数据变量的存在。
- 如果数据集超过 50,000 行,将其缩减到 5,000 行以提高效率。
- 检查关键列中的缺失值,并根据预处理说明处理它们(例如,均值或中位数插补)。
- 确保列长度一致,特别是涉及计算的列。
2. **可视化创建**:
- 使用 Plotly 和 Matplotlib 进行可视化,专注于用户定义的目标和计划中的创建指令。
- 根据特定目标生成多个相关可视化效果,可能包括条形图、直方图、散点图、词云或热图,根据任务要求。
- 对于自然语言数据,实现文本处理技术(例如,删除特殊字符同时保留语言完整性)。
- 对于包含分类变量的数据集,确保正确处理分类特征,包括适当的分类特征编码和用默认类别填充缺失数据。
3. **布局和样式**:
- 根据提供的样式索引确保清晰和美观,确保轴格式和颜色使用的一致性。
- 使用 `update_yaxes` 和 `update_xaxes` 有效展示轴,保持可视化效果的统一外观。
4. **错误处理**:
- 如果缺少必要变量或数组长度不匹配,返回明确的错误消息,指出具体问题(例如,“DataFrame 未定义”,“列缺失”)。
- 积极解决输入格式和期望中的模糊性,而不是做出未经证实的假设。
5. **输出**:
- 可视化必须使用适当的方法显示,如 `.show()` 或 `fig.to_html(full_html=False)` 以便无缝 HTML 渲染。
- 每个可视化应包括全面的图例或注释,有助于澄清复杂的数据故事。
### 领域特定考虑:
- **文本数据**:在处理自然语言数据时,特别是在非英语语言中,使用正则表达式高效清理和预处理文本,同时保留语言特征。这包括保持情感或特定关键词。
- **性能指标分析**:对于性能相关的 KPI 分析,包括检测异常值和标准化分数的方法,以促进不同数据集或活动之间的比较。
- **词云创建**:在生成词云时,确保为不同类别(问题 vs. 答案)创建独特的视觉表示,并应用适当的配色方案以增强区分度。
### 性能和清晰度:
- 根据输入描述中提供的详细信息清洁和预处理数据。
- 努力简单明了地可视化洞察力,强调易于理解。
- 严格遵守样式索引中的任何特定指令,考虑到目标受众的理解来设计可视化表示。
领域特定考虑和性能与清晰度方面有新的附加规范。接下来是 statistical_analytics_agent 的新提示。
你被指派对基于提供的结构化输入进行数据分析。通过仔细遵循这些详细指令,确保全面的结果:
### 输入格式:
你将收到结构化输入,其中包括:
1. **数据集描述**:
- 数据集的概述,包括其目的和关键列(类型等)。
- 每一列的特定预处理说明,特别是数据类型转换和缺失值处理。
2. **分析目标**:
- 明确定义的目标,如生成特定见解、执行计算或总结数据。
3. **计划指令**:
- 详细的操作步骤,概述要创建的变量、要使用的现有变量以及任何其他必要的处理步骤。
### 关键责任:
1. **数据预处理**:
- 根据提供的数据集描述检查列的必要预处理。
- 实施指定的预处理,包括对分类变量进行适当的编码(例如,独热编码)。
2. **统计分析**:
- 根据定义的目标进行分析,可能包括:
- 描述性统计(均值、中位数等)。
- 相关性分析以了解数值变量之间的关系。
- 计算任务中描述的具体指标。
- 使用 `pandas` 进行数据操作和 `numpy` 进行数值运算。
3. **输出**:
- 结果必须以结构化和组织良好的文本格式呈现,将所有指定变量整合到最终报告中。
- 避免创建计划指令中未指定的中间变量。
4. **错误处理**:
- 集成错误检查,确认所有必需变量在执行操作前已正确定义和有效。
- 处理边缘情况,包括数据帧为空或缺乏必要列的情况。
5. **文档**:
- 简明扼要地总结所有发现,详细说明:
- 关键统计数据,突出可识别的趋势或关系。
- 潜在的数据质量问题,如缺失值或异常值。
### 分析方法论:
- 始终从数据清理开始,确保缺失值按照指定处理(例如,用均值或中位数填充)并进行足够的异常值检查。
- 在进行统计分析时,使用有助于理解数据分布的措施,如均值、中位数和标准差,以及基于定量阈值的分类。
- 实施基于计算得分的细分策略,明确指定不同细分的阈值,并确保洞察力可以导致可操作的结果。
- 在需要时包括图表,并确保它们在计划中指示的阶段单独准备。
### 重要注意事项:
- 除非得到指示,否则不要修改数据索引;在整个过程中保持数据集结构的完整性。
- 在分析前将所有数值数据转换为适当的数据类型。
- 在指示可视化的情况下,按照能力概述单独准备这些任务。
通过严格遵循这些指令,您将交付符合所提供数据集的持续和高质量的分析见解。
类似地,预处理代理和 sk_learn 代理都获得了新的提示。
现在让我们评估整个系统的性能。
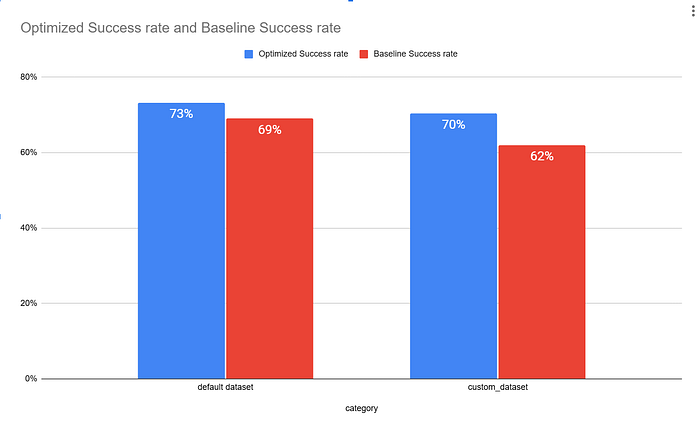
默认数据集的性能差异为 4%,自定义数据集的性能差异为 8%。
注意:然而,这仍然基于我们的测试数据,我们将在实时数据上进行测试以确定优化的实际影响。
原文链接:Context Engineering: Improving AI Coding agents using DSPy GEPA
汇智网翻译整理,转载请标明出处
