用代码生成优化MCP调用成本
Anthropic 和 Cloudflare 的工程团队独立地发现了大幅降低MCP调用成本的相同解决方案:停止让模型直接调用MCP工具,而是让它们编写代码。

Anthropic 最近发表的论文探讨了 MCP 的最大问题——他们的 AI 代理需要处理 15 万个令牌才能加载工具定义,甚至在读取用户请求之前就需要处理这些令牌。而同样的功能现在只需要 2000 个令牌——成本降低了 98.7%。
随着人工智能代理从概念验证阶段扩展到生产阶段,将它们连接到数十个拥有数百种工具的 MCP(模型上下文协议)服务器已成为标准做法,这一点至关重要。但一个显而易见的问题却隐藏其中:每个工具定义都会预先加载到上下文窗口中,并且每个中间结果都会流经模型。
Anthropic 和 Cloudflare 的工程团队独立地发现了相同的解决方案:停止让模型直接调用工具,而是让它们编写代码。
1、传统 MCP 的陷阱
模型上下文协议彻底改变了人工智能代理连接外部系统的方式。自 2024 年 11 月发布以来,社区已经构建了数千个 MCP 服务器,使代理能够访问从数据库到云服务的各种资源。
但标准实现存在一个根本性的效率低下问题。
以下是您要求代理“分析此文档、提取关键词、生成摘要并保存结果”时发生的情况:
步骤 1:加载所有工具定义
{
"read_file": {
"description": "Reads content from a file...",
"inputSchema": { /* detailed schema */ },
"outputSchema": { /* detailed schema */ }
},
"extract_keywords": {
"description": "Extracts important keywords...",
"inputSchema": { /* detailed schema */ },
"outputSchema": { /* detailed schema */ }
},
// ... all other tools
}成本:1,304 个 token(模型甚至还没有开始运行)
步骤 2:模型调用 read_file
{
"tool": "read_file",
"arguments": {"filepath": "document.txt"}
}成本:30 个 token
步骤 3:完整文档返回模型
{
"content": "Cloud Infrastructure Cost Optimization Report\n\nExecutive Summary...",
"size": 2510,
"lines": 45
}成本:689 个 token(整个文档现在都在上下文中)
步骤 4:模型调用 extract_keywords
{
"tool": "extract_keywords",
"arguments": {
"text": "Cloud Infrastructure Cost Optimization Report\n\nExecutive Summary..."
}
}成本:700 个 token(完整文档再次经过上下文)
你可以看出其中的问题。同一个 2510 个字符的文档会三次流经模型的上下文:一次作为 read_file 的输出,一次作为 extract_keywords 的输入,还有一次作为 generate_summary 的输入。
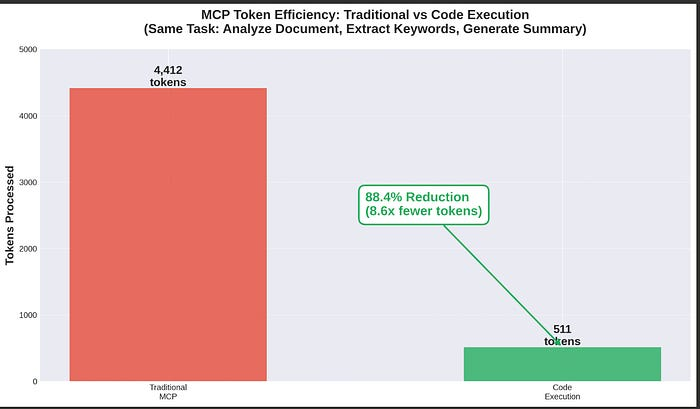
传统方法总计:4,412 个令牌
2、实际影响
Anthropic 在其生产系统中测量了令牌数量的减少——从 150,000 个令牌减少到 2,000 个令牌,改进了 98.7%。这种模式在大规模应用时会变得非常糟糕:
- 会议记录:一个 2 小时的销售电话(50,000 个令牌)被处理两次 = 浪费了 100,000 多个令牌
- 上下文窗口污染:数百个工具定义 = 在模型读取您的请求之前需要 150,000 个令牌
- 成本倍增:每个中间结果都要经过模型,从而增加 API 成本
- 延迟螺旋式下降:更多令牌 = 更慢的响应 = 用户沮丧
为了证明这并非只是理论上的,我构建了一个更简单的实际演示:分析一份云成本优化报告。即使是这种基本的工作流程,结果也令人震惊。
3、代码执行方法
Anthropic 和 Cloudflare 都得出了相同的结论:LLM 模型非常擅长编写代码,但在调用工具方面却表现平平。
正如 Cloudflare 团队所说:
“LLM 模型见过大量的代码,但很少见过‘工具调用’。事实上,它们见过的工具调用可能仅限于 LLM 自身开发者构建的训练集。而它们见过来自数百万个开源项目的真实代码。”
这就像让莎士比亚在参加了一个月的语言课程后用普通话写剧本一样。他或许能做到,但这绝不会是他的最佳作品。
4、更好的方法
与其将 MCP 工具直接作为函数调用公开,不如将它们转换为编程语言 API,然后让模型编写代码。
以下是使用代码执行的相同任务:
步骤 1:加载最小 TypeScript API
interface FileContent {
content: string;
size: number;
lines: number;
}
interface Keyword {
term: string;
score: number;
frequency: number;
}
async function readFile(filepath: string): Promise<FileContent>
async function extractKeywords(text: string, maxKeywords?: number): Promise<{keywords: Keyword[]}>
async function generateSummary(text: string, maxLength?: number): Promise<Summary>
async function saveResults(filepath: string, data: any): Promise<SaveResult>成本:184 个 token(比完整 schema 少 85%)
步骤 2:模型生成代码
async function analyzeDocument() {
// Read document (data stays in execution environment)
const doc = await readFile('document.txt');
// Extract keywords (full text doesn't go back to model)
const keywordsData = await extractKeywords(doc.content, 10);
// Generate summary (full text doesn't go back to model)
const summaryData = await generateSummary(doc.content, 100);
// Save results
const results = {
keywords: keywordsData.keywords,
summary: summaryData.summary
};
await saveResults('results.json', results);
console.log(`Analysis complete. Extracted ${results.keywords.length} keywords.`);
console.log(`Results saved successfully.`);
}
await analyzeDocument();成本:285 个 token
步骤 3:代码在沙箱中执行
文档被读取,关键词被提取,摘要被生成,结果被保存——所有操作都在执行环境中进行。模型不会看到文档内容。
步骤 4:仅日志返回给模型
Analysis complete. Extracted 10 keywords.
Results saved successfully.成本:42 个 token
代码执行总计:511 个 token
节省:3,901 个 token(减少 88.4%)
5、证明:构建实时演示
Anthropic 报告称,在生产环境中 token 减少了 98.7%。Cloudflare 使用“代码模式”独立验证了该方法。但我希望通过实际演示来验证这些数据。
我使用一个更简单、更易于理解的任务——分析一份 2510 个字符的云成本优化报告——构建了一个实际的对比。即使是这种基本的流程——读取文件、提取关键词、生成摘要、保存结果——效率提升也非常显著。
演示模拟了:
- 4 个 MCP 工具(read_file、extract_keywords、generate_summary、save_results)
- 完整的 JSON 模式及文档
- 真实的数据流
- 两种方法的令牌计数
以下是可视化结果:
代码执行胜出的五大理由
- 渐进式披露
- 基于上下文的高效数据处理
- 更佳的控制流程
- 默认隐私
- 状态持久性和技能
6、生产环境的现实检验
代码执行并非免费。您需要:
基础设施:
- 安全的执行环境(沙箱、资源限制)
- 监控和日志记录
- 错误处理和恢复
运维复杂性:
- 管理代码执行生命周期
- 调试生成的代码问题
- 处理执行超时
成本考量:
- 执行环境定价
- 生成代码的存储
- 监控基础设施
7、何时使用不同方法
在以下情况下使用传统的 MCP:
- 简单的单工具工作流程
- 工具之间数据传输量极少
- 快速原型开发
- 工具无需链式调用
在以下情况下使用代码执行:
- 多个工具调用链式执行
- 大型文档或数据集
- 需要数据过滤/转换
- 隐私要求(将数据排除在模型之外)
- 构建可重用工作流程(“技能”)
- 具有成本限制的生产环境代理
8、这对您的 AI 战略意味着什么
如果您正在构建生产环境 AI 代理,尤其是在财务或合规性限制下,代码执行不仅仅是一种优化,而是一种必需。
Anthropic 的生产成果足以证明一切:
- 减少 98.7% 的令牌 = 每次操作成本降低 98.7%
- 150,000 个令牌 → 2,000 个令牌 = 效率提升 75 倍
- 更快的响应速度 = 更佳的用户体验
- 上下文窗口效率提升 = 可处理 75 倍以上的任务
- 默认隐私保护 = 更易于合规
即使是更简单的任务(例如我们的演示),也能显著节省成本:减少 88.4% 意味着成本降低近 9 倍,响应速度也相应加快。
随着 MCP 的普及,“将所有内容加载到上下文中”的方法将无法扩展。代码执行才是代理架构的发展方向。
原文链接:We've Been Using MCP Wrong: How Anthropic Reduced AI Agent Costs by 98.7%
汇智网翻译整理,转载请标明出处
