TOOL ComfyUI官方支持FLUX.1 Tools ComfyUI 现在支持 Black Forest Labs 为 Flux.1 设计的新模型:Redux 适配器、Fill模型、ControlNet & LoRA(深度和 Canny边缘)。
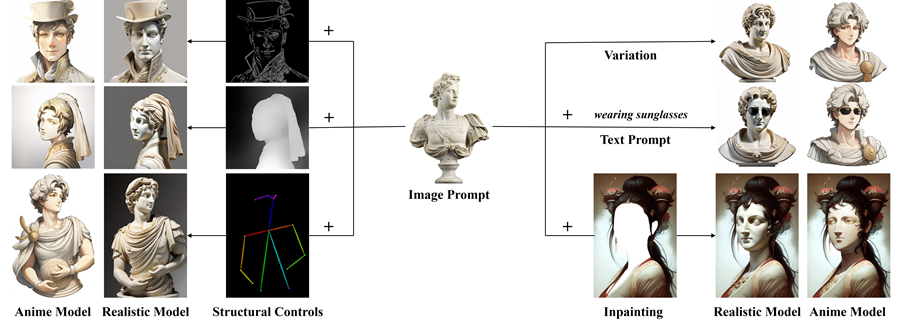
MODEL-ZOO FLUX.1 Tools 图像工具包 FLUX 背后的团队 Black Forest Labs 刚刚发布了 FLUX.1 Tools — 一套由四个强大的工具组成的套件,可增强 FLUX 的图像生成能力和可控性。
TOOL 15个电商必备虚拟试穿AI工具 本文探索15个顶级 AI 试穿解决方案,这些解决方案通过使用先进的增强现实和人工智能技术,让用户实时虚拟试穿服装、化妆品和配饰等产品,从而彻底改变虚拟购物体验。
LIBRARY FireCrawl 网页抓取平台 Firecrawl 是一个以 REST API 形式公开的网络抓取引擎。你可以通过 cURL 从命令行使用它,也可以使用 Python、Node、Go 或 Rust 语言 SDK 之一使用它。
TOOL ComfyUI服装更换工作流 将 IPAdapter 的风格提取与 Grounding Dino 和 Segment Anything 模型的精确分割相结合时,可以获得非常准确且轻松的服装更换。
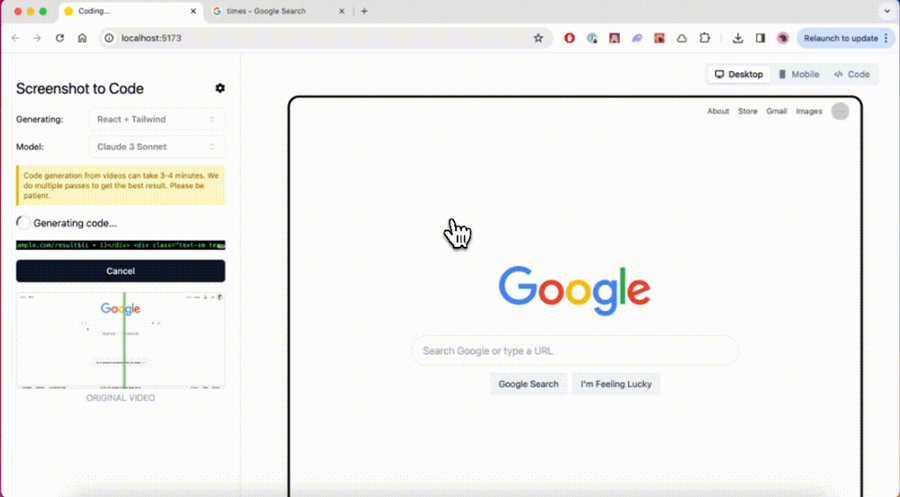
TOOL 屏幕截图生成代码 Screenshot-to-code是一个简单的工具,可使用 AI 将屏幕截图、模型和 Figma 设计转换为干净、实用的代码。现在支持 Claude Sonnet 3.5 和 GPT-4o!
TOOL Miro vs.FigJam:AI能力对比 在过去的一年里,Miro 和 FigJam 之间的竞争又增加了一层神秘感:人工智能。这两个平台都推出了AI助手,旨在让研讨会更快、更轻松、更有创意。
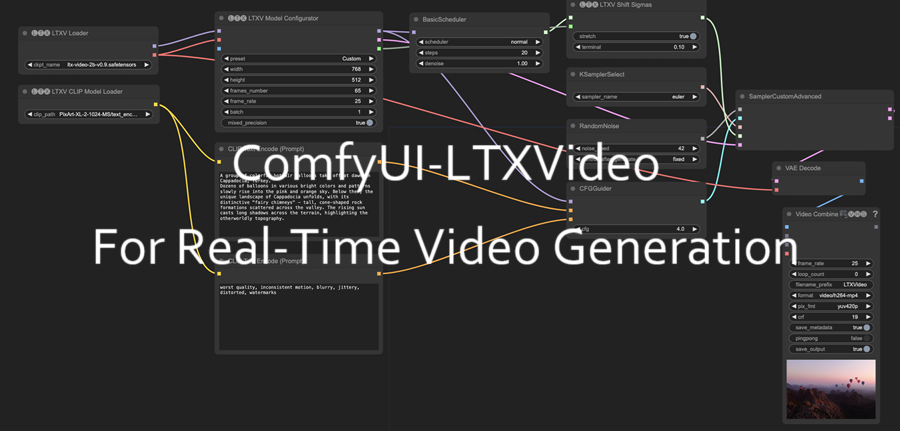
TOOL ComfyUI-LTXVideo视频生成 ComfyUI-LTXVideo 是 ComfyUI 的自定义节点集合,旨在集成 LTXVideo 传播模型。这些节点支持文本到视频、图像到视频和视频到视频生成的工作流程。
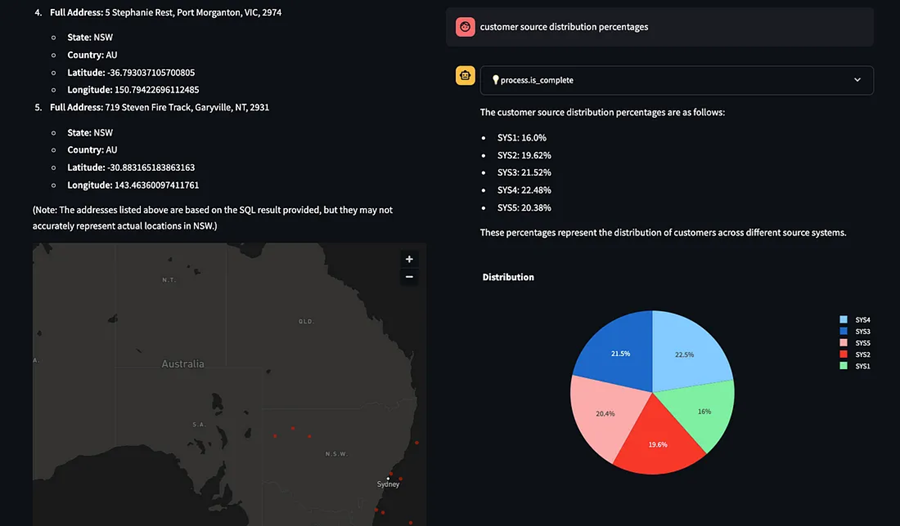
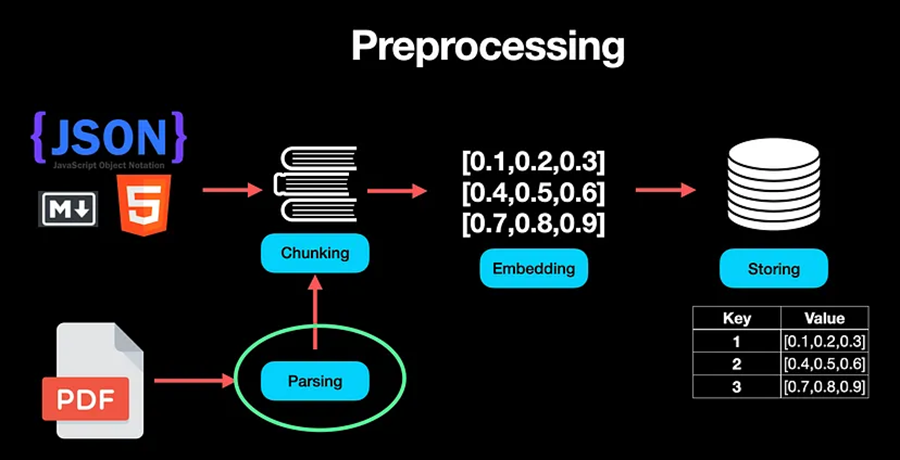
APPLICATION 构建语义搜索的弹性嵌入系统 当 ChatGPT 于 2022 年引起公众关注时,Airtable 的一小群工程师开始构思我们的平台可以利用这组新功能的不同方式。一个想法不断涌现:对客户数据进行丰富的语义搜索。