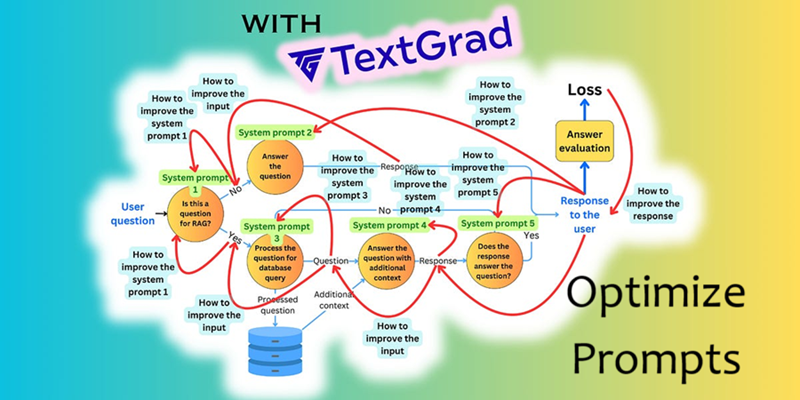
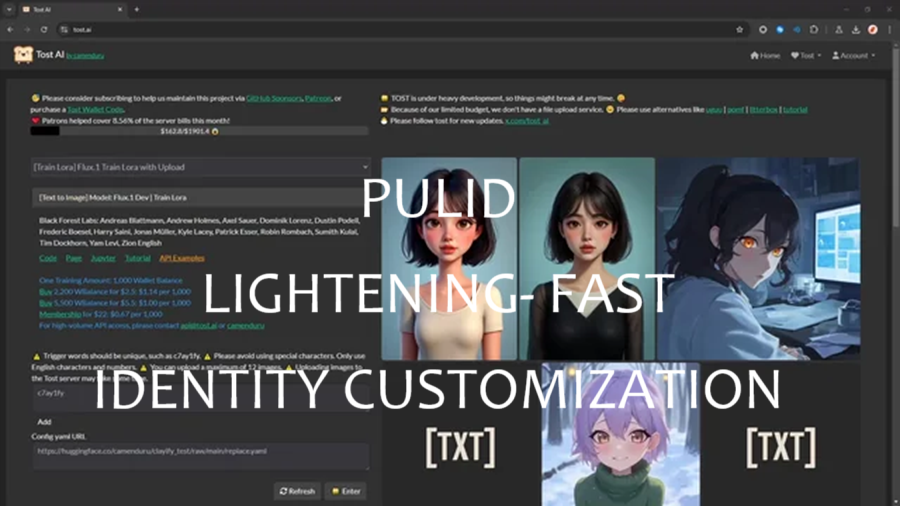
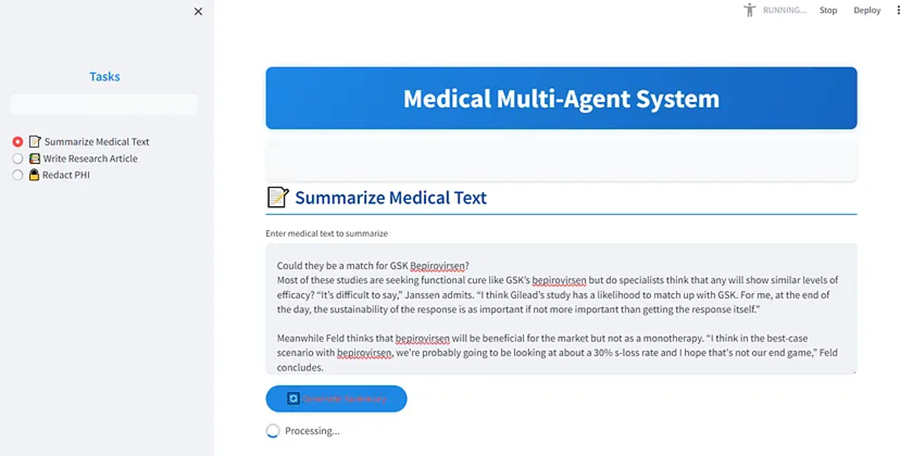
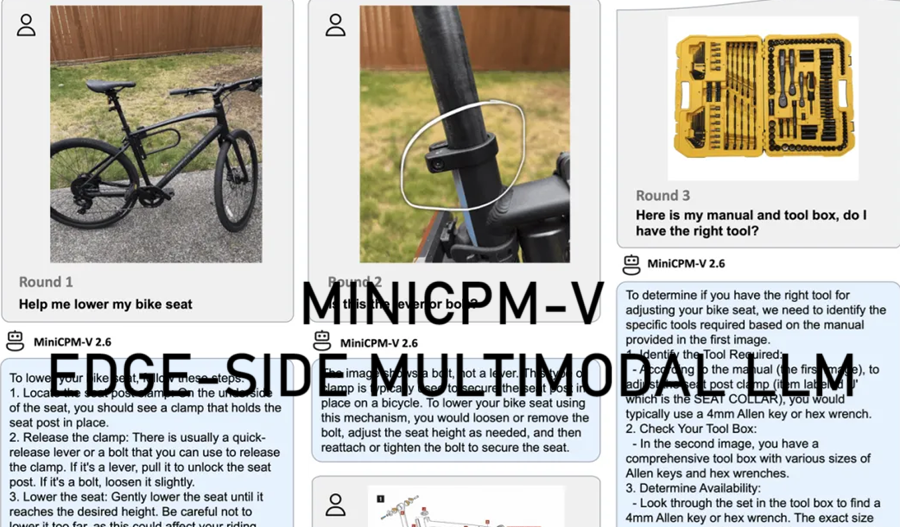
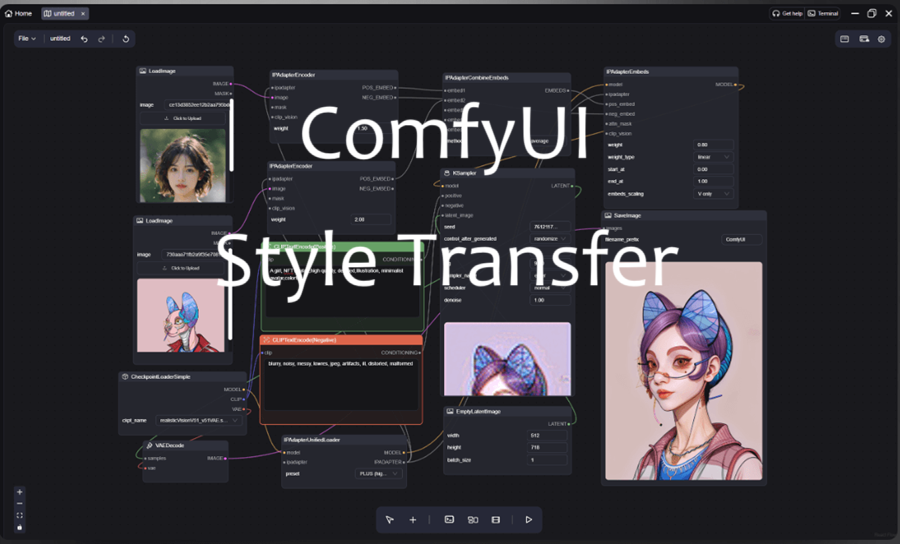
MODEL-ZOO OOTDiffusion虚拟试穿模型 虚拟试穿技术是电子商务和时尚领域的一项前沿创新,它允许客户在不实际穿着的情况下尝试虚拟服装、配饰、化妆品或其他时尚元素。OTDiffusion是一种基于 LDM 的新方法。
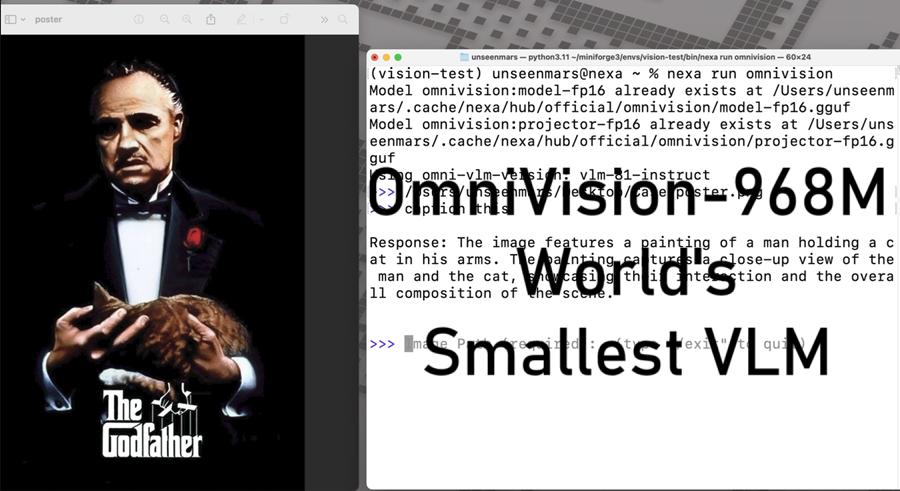
APPLICATION 打造自己的AI搜索引擎 你可能听说过 Perplexity,这是一个引起轰动的 AI 搜索引擎,但它是收费的。本文介绍使用开源 AI工具创建本地 Perplexity 的替代方案。
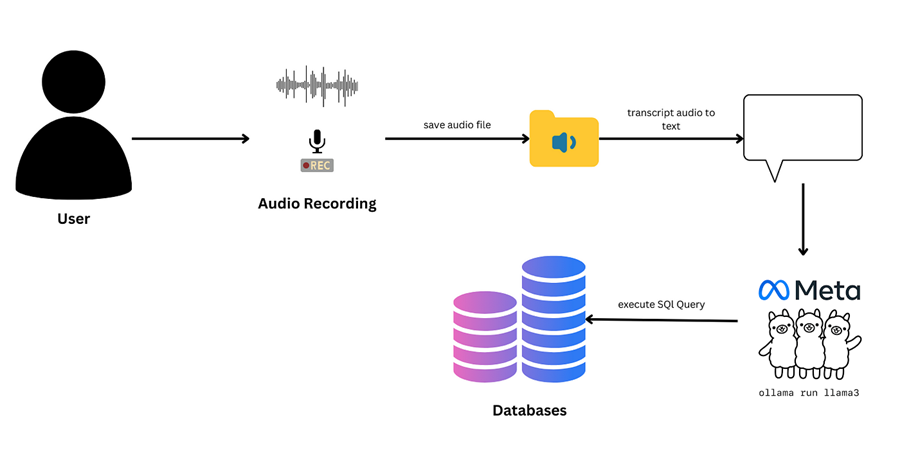
APPLICATION LlamaIndex构建AI实时交易系统 本教程演示了如何使用 Kafka 流式传输 EUR/USD 数据、使用 LlamaIndex 工作流进行无缝逻辑处理以及使用 GPT-4o 进行图像分析来构建实时交易机器人。