用 Docker 运行本地 LLM 模型
Docker 已经解决了应用程序“在我的机器上运行正常”的问题。现在,它正在解决模型运行的同样问题。

几个月来,我一直在断断续续地尝试在本地运行 LLM 模型。每次快要成功的时候,总会遇到一些莫名其妙的问题——Python 版本、CUDA 问题,或者一些一小时前还不存在的随机构建错误。你懂的。
但最近我尝试使用 Docker + Unsloth 运行模型,说实话,这是我第一次感觉整个过程不像是在做科学实验。基本上就是:安装 Docker → 运行命令 → 搞定,你就能和一个 20B 的模型聊天了。
所以我决定用简单的语言解释一下它的工作原理,这样你就不用像我一样费劲地摆弄电脑了。
1、Docker + Unsloth :完美地协同
Docker 已经解决了应用程序“在我的机器上运行正常”的问题。现在,它正在解决模型运行的同样问题。Unsloth 构建的动态 GGUF 模型体积小、速度快。Docker 会打包它们的运行时环境,所以你无需手动安装 llama.cpp 之类的东西。
没有复杂的设置。无需处理依赖项。模型……运行。
这就是它真正的魔力所在。
2、你的设备需要什么(无需特殊配置)
快速指南:
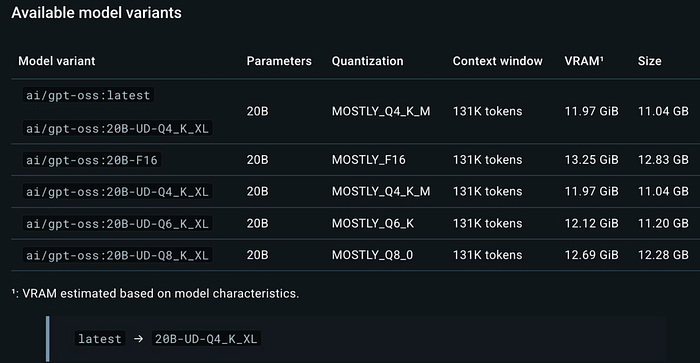
RAM + VRAM 的大小至少应与你拉取的模型大小相同。
所以,如果您要下载一个 13.8GB 的模型,那么您的总内存至少应该有 14GB。如果少于 14GB,模型仍然可以运行,但您会遇到卡顿。
一些简单的提示:
- 更大的显存 (VRAM) 会有很大帮助
- 300 亿以下的模型 → Q4量化 (Q4 quant) 即可
- 大型模型(700 亿左右)→A2量化 (Q2 quant) 或类似规模
您只需要知道这些就够了——无需图表或数学计算。
3、终端方法
确保 Docker 正常运行。输入:
docker如果它输出一些内容,那就没问题了。
现在,运行一个模型。以下是我使用的一个示例:
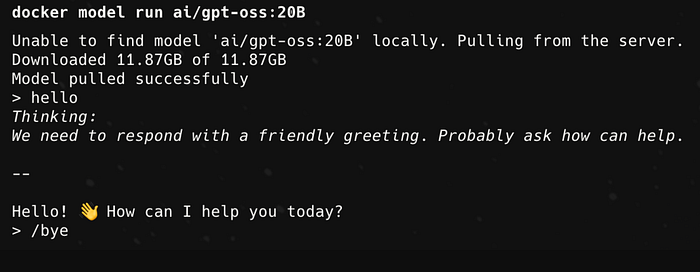
docker model run ai/gpt-oss:20B它会加载模型。稍等片刻。然后您就可以开始输入提示信息了。
另一个例子:
docker model run ai/Qwen3-Coder-30B-A3B-Instruct-GGUF如果您想要 Hugging Face 的特定引用:
docker model run hf.co/unsloth/gpt-oss-20b-GGUF:F16就是这样。无需设置,无需调整。
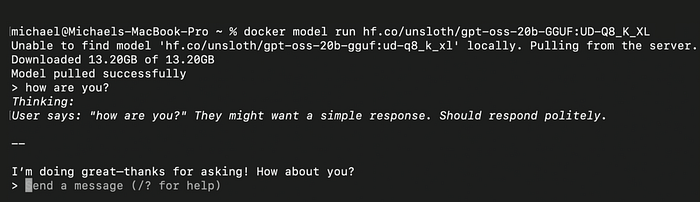
如果您想要不同的数量级别,只需添加:
docker model run hf.co/unsloth/gpt-oss-20b-GGUF:UD-Q8_K_XL或者更小的级别:
docker model run hf.co/unsloth/gpt-oss-20b-GGUF:Q2_K_L没什么好说的了。它就是好用。
4、无代码方式(Docker Desktop)
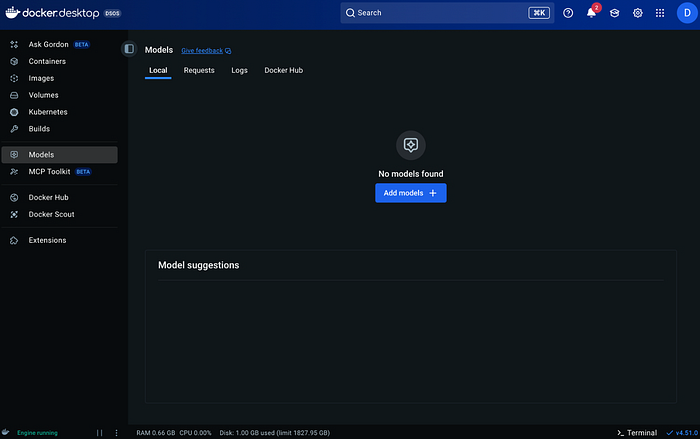
如果您更喜欢点击按钮而不是输入命令,Docker Desktop 现在有一个“模型”选项卡。
打开它,点击“添加模型”,输入模型名称,选择数量,等待下载完成,然后点击“运行”。
之后会显示一个小窗口,您可以在其中输入提示信息。感觉就像一个迷你版的离线 ChatGPT 窗口。
如果您不想使用终端,这非常方便。
5、运行新模型
任何受 llama.cpp 支持的模型通常也能在这里运行。因此,如果发布了新的 Gemma、Qwen、Llama 或任何其他模型,它通常会很快出现,并且使用相同的命令模式运行。
6、模型运行器概览
Docker 模型运行器 (DMR) 为模型提供了一个简单、可预测的环境。Docker 会为您处理所有组件,而无需您自行安装。
您将获得:
- 每次都一致的设置
- 没有依赖关系问题
- 轻松共享模型
- 可预测的性能
如果您曾经搞砸过 Python 环境,您就会明白这一点,相信我。
7、一个简单的示例提示
模型运行后,您可以尝试以下测试:
Write a small Python script that prints how many times each word appears in a file.或者:
Explain how to run a Q4 quant 13B model on Docker.它能很好地处理这些任务。
8、结束语
如果您一直因为本地 LLM 过于繁琐或技术性太强而避免使用,Docker 让一切变得简单得多。现在只需一行简单的命令即可。您甚至无需担心 CUDA、驱动程序或其他任何内容。
只需选择一个与您的内存容量相匹配的模型即可。
原文链接:How to Run Local LLMs with Docker
汇智网翻译整理,转载请标明出处
