三星TRM:微型递归模型
三星刚刚发布了一款仅有 700 万参数的全新 AI 模型,但它的表现却超越了市面上一些最大的模型。它比 DeepSeek 或 Gemini 2.5 Pro 小 1 万倍,但在 ARC-AGI 1 和 2 基准测试中仍然表现出更强大的推理能力。

三星刚刚发布了一款仅有 700 万参数的全新 AI 模型,但它的表现却超越了市面上一些最大的模型。它比 DeepSeek 或 Gemini 2.5 Pro 小 1 万倍,但在 ARC-AGI 1 和 2 基准测试中仍然表现出更强大的推理能力。
它被称为微型递归模型 (TRM),这可能是我几个月来在人工智能领域看到的最令人着迷的东西。
1、那么,它到底有什么诀窍呢?
最神奇的是:TRM 不像典型的 LLM 那样只是生成答案。它会思考,然后重新思考,最后自我修正。
它不是“预测下一个单词”,而是经历一种内部循环——先草拟答案,检查其逻辑,然后重写,最多重复 16 次。
这并非夸张。该模型本质上是循环推理,直到它感到自信为止。
步骤1:草稿
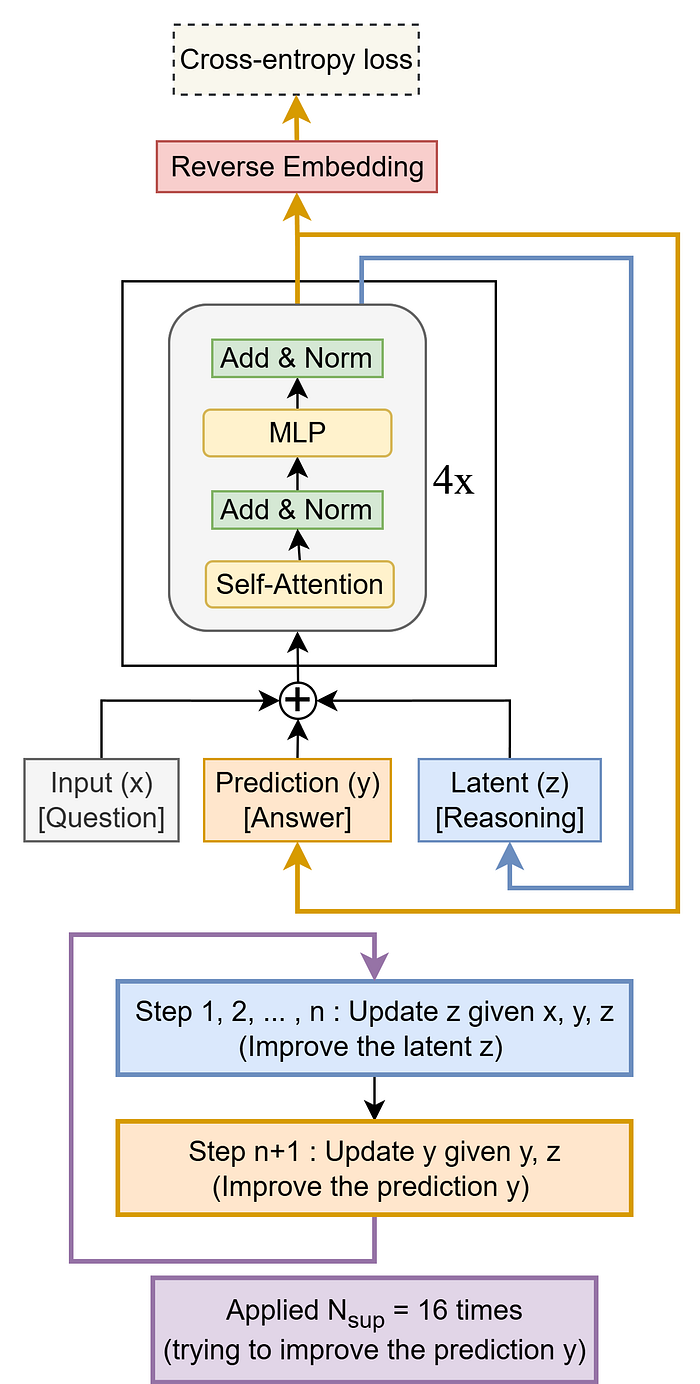
TRM 开始工作。它会检查你的问题,并快速提供一个初步答案——快速、粗略,而非精雕细琢。就像在绘画前快速勾勒轮廓一样。
步骤 2:草稿
现在变得更有趣了。模型揭示了一个隐藏的空间——一个微小的内部“便笺簿”,它开始在那里大声思考(比喻)。
就像这样:
draft = model.initial_answer(problem)
scratchpad = model.create_scratchpad()
for i in range(6):
feedback = model.check_reasoning(draft, problem)
scratchpad.update(feedback)
draft = model.revise(draft, scratchpad)这个便笺簿就是TRM与自己辩论的地方——检查它的推理是否站得住脚。
步骤3:思考、修正、重复
一旦完成分析,它就会使用所有内部逻辑更新答案。然后循环往复。
每一轮都会强化推理。到最后,模型已经经历了多次自己的思考过程——就像学生修改作业直到最终明白道理一样。
2、为什么每个人都在关注
从理论上讲,它听起来很小。但 TRM 的结果令人印象深刻:
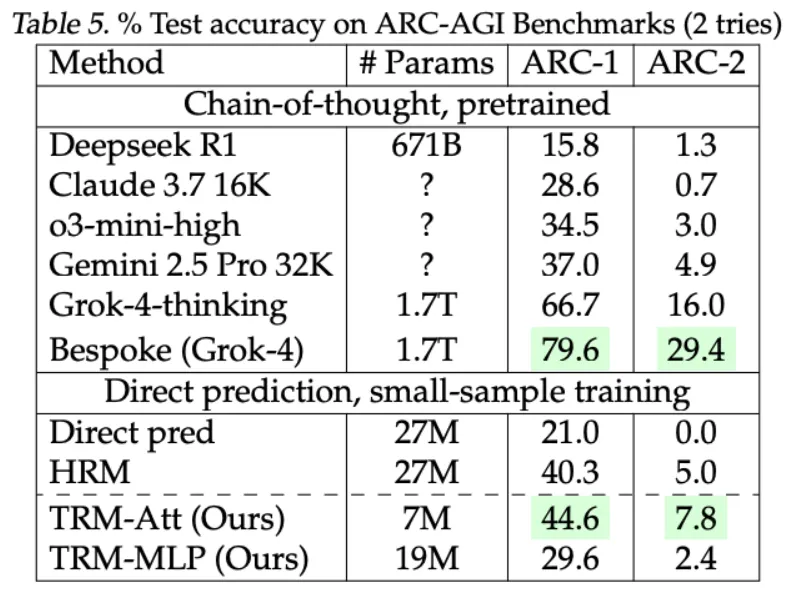
- ARC-AGI-1 准确率 45%
- ARC-AGI-2 准确率 8%
除非你明白 ARC-AGI 是一项极具挑战性的任务,否则这些数字可能看起来并不重要。大多数小型模型甚至无法与之匹敌。TRM 仅用 700 万个参数就实现了这一目标——而像 GPT-4 这样的巨头,拥有数万亿个参数,仍在努力追寻这一目标。
这不仅仅是规模缩小的问题,而是一种不同的思维方式。
- 如果你经营一家企业。这就是效率的体现。当其他人花费数百万美元建造大型推理模型时,你可以拥有一个小型、更具创新性的系统,推理能力更强——而且运行成本几乎为零。
- 如果你是一名研究人员。这是对神经符号和递归推理思想的重要认可。它表明,智能可能更多地源于架构而非原始规模。
- 如果你是一名实践者。你实际上可以在标准硬件上训练和测试 TRM。本文提供了全面的说明。以下是快速预览。
3、设置指南
环境:
python3.10 -m venv trm_env
source trm_env/bin/activate
pip install --upgrade pip wheel setuptools
pip install --pre --upgrade torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu126
pip install -r requirements.txt
pip install --no-cache-dir --no-build-isolation adam-atan2可选:
wandb login YOUR-LOGIN数据集示例(ARC-AGI-1):
python -m dataset.build_arc_dataset \
--input-file-prefix kaggle/combined/arc-agi \
--output-dir data/arc1concept-aug-1000 \
--subsets training evaluation concept \
--test-set-name evaluation您也可以尝试数独或迷宫数据集,丰富多样。
训练(数独示例):
python pretrain.py \
arch=trm \
data_paths="[data/sudoku-extreme-1k-aug-1000]" \
epochs=50000 eval_interval=5000 \
lr=1e-4 puzzle_emb_lr=1e-4 weight_decay=1.0 \
arch.L_layers=2 arch.H_cycles=3 arch.L_cycles=6 \
+run_name="pretrain_att_sudoku" ema=True就是这样。它在单个 L40S GPU 上运行不到两天。
对于一个使用递归推理的模型来说,这相当令人印象深刻。
3、那么,这意味着什么?
TRM 证明了“少即是多”不仅仅是一句朗朗上口的话。你并不总是需要大模型(LLM) 才能实现可靠的推理。
一个经过训练的小型模型——先思考后说话——可以表现得比预期更好。
这也是一种微妙的思维转变:三星不是试图通过规模来模仿智能,而是通过流程来开发智能。
这一点非常重要。
4、结束语

TRM 的目标并非成为房间里最聪明的人。它的目标是学习如何更好地思考。
如果这有效——如果递归真的可以取代扩展——那么我们可能正在进入一个小型 AI 开始超越大型 AI 的新时代。
这难道不是一件了不起的事吗?
原文链接:Samsung's Tiny Recursive Model — The 7M-Parameter AI That Outsmarted DeepSeek-R1, Gemini 2.5
汇智网翻译整理,转载请标明出处
