SongBloom:歌曲生成模型
SongBloom不仅输出音频片段,还能生成连贯的完整歌曲,包括歌词、人声、乐器、前奏和副歌,听起来像真正的音乐。

人工智能已经尝试了几年来创作音乐,但如果你听了大多数这些尝试,你会发现两个问题:

小部分(比如吉他riff或一段歌声)单独听起来可能不错,但它们无法组合成一首完整的歌曲。 或者大结构(如主歌、副歌、桥段)大致存在,但音频本身听起来平淡或人工。
SongBloom 是由来自香港中文大学、腾讯和南京大学的研究人员开发的新系统。他们的目标是让AI不仅输出音频片段,还能生成连贯的完整歌曲,包括歌词、人声、乐器、前奏和副歌,听起来像真正的音乐。

1、SongBloom的工作原理
可以把它想象成艺术家作画的过程:
- 他们首先从一个草图开始:勾勒出形状的大致线条。
- 然后他们用颜色和细节对它进行细化。
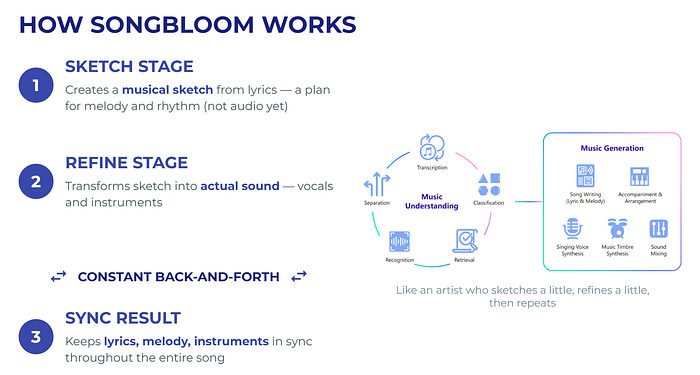
SongBloom也以同样的方式处理音乐:
- 草图阶段:该模型查看歌词并创建一个粗糙的“音乐草图”。这还不是音频,而更像是旋律和节奏的计划。
- 细化阶段:模型的另一部分将这个草图转化为实际的声音:人声和乐器。
这里有一个巧妙的变化:SongBloom不是先完成整个草图,然后再进行细化,而是来回切换。它先草拟一点,再细化一点,然后再次草拟,如此反复。这种持续的来回操作在整个过程中保持歌词、旋律和乐器的一致性。
2、输入和输出的内容
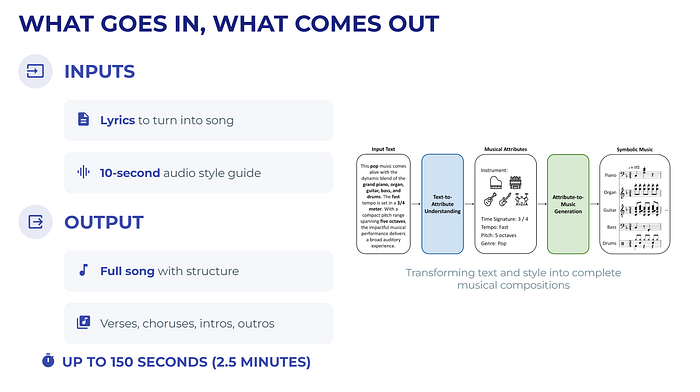
输入:
- 你想转换成歌曲的歌词。
- 一个简短的10秒音频片段作为风格指南(告诉模型使用什么样的氛围)。
输出:
- 一首完整的歌曲,最长可达150秒(约2.5分钟)。包括主歌、副歌,甚至非人声部分如前奏和尾声。
3、为什么SongBloom与众不同

许多AI歌曲生成模型来了又走了,但SongBloom不同
- 它保持结构。许多模型在歌曲中途会失去方向(例如,无休止地重复副歌)。SongBloom尊重歌词中的主歌-副歌布局。
- 它听起来干净。与使用高度压缩的“音频标记”(其他AI系统中常见)不同,SongBloom直接使用连续的音频信号。这有助于保留高频细节,使歌声不会听起来模糊。
- 它效率高。通过以小块(每次约0.6秒)生成音乐,它可以避免在大型序列上浪费计算资源,同时保持连贯性。
- 它融合了两个世界。语言模型风格的“草图”+基于扩散的“音频细化”,而不是分开进行。
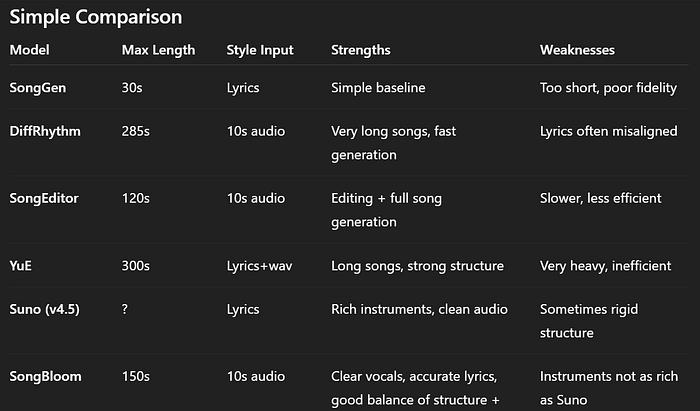
研究人员将SongBloom与开源模型(SongGen、SongEditor、DiffRhythm、YuE)和商业工具(Suno、Udio)进行了比较。
在自动测试(客观指标)中:
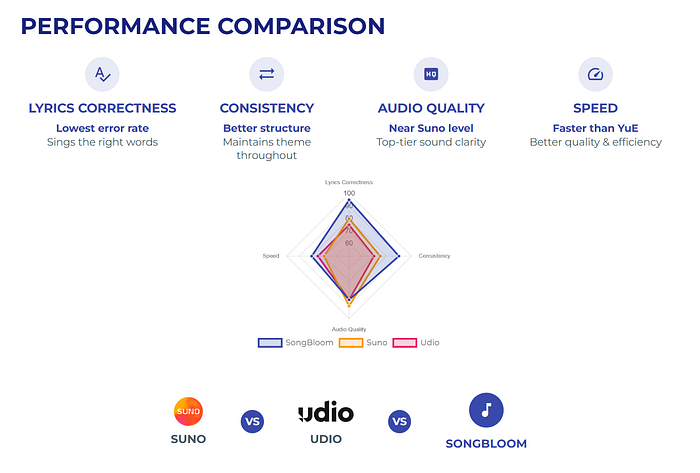
- 歌词准确性:SongBloom的错误率最低(意味着AI唱的是正确的词)。
- 一致性:它比其他模型更好地保持主题和结构。
- 音频质量:几乎和Suno一样好,而Suno目前被认为是顶级的。
- 速度:比一些大型开源模型(如YuE)更快,同时产出更好的质量。
在人类听觉测试(主观指标)中:
- 听众表示SongBloom的人声更清晰,歌词匹配度更好。
- 商业工具如Suno在乐器丰富性方面仍略占优势,但SongBloom并不落后太多。
- 在对具有清晰主歌-副歌模式的歌曲进行微调后,SongBloom甚至在某些指标上超过了Suno。
4、为什么这是件大事

大多数开源研究音乐模型相比商业系统感觉像是玩具。SongBloom改变了这一点:它是第一个在质量和连贯性上接近Suno或Udio的开源系统。
设计思路是草拟一点,细化一点,重复——虽然简单但很强大。它使得AI不太可能在歌曲中途迷失方向。
5、接下来是什么

SongBloom并不是完美的。目前它的“草图”是数学信号,而不是乐谱。这意味着你不能像乐谱那样轻松地编辑它们。添加更多可读的人类控制(例如,“让副歌更大声”或“改变调性”)仍然是一个开放的挑战。
但作为一项研究步骤,它意义重大。第一次,一个开源系统表明AI可以生成带有歌词和结构的完整歌曲,而不显得像拼接起来的乱七八糟的东西。
原文链接:SongBloom : AI model to Generate Songs, Free Suno
汇智网翻译整理,转载请标明出处
