用Lag-Llama预测股价
为了解决时间序列泛化挑战,研究人员引入了Lag-Llama,这是一种专为单变量概率时间序列预测设计的基础模型。

近年来,基础模型彻底改变了机器学习领域,使零样本和少样本泛化成为可能。尽管它们在自然语言处理和计算机视觉方面取得了显著进展,但在时间序列预测中的应用仍然相对受限。
这种限制在金融数据预测中尤为明显,其中固有的噪声和非平稳性带来了重大挑战。
1、引入Lag-Llama
为了解决时间序列泛化挑战,研究人员引入了Lag-Llama,这是一种专为单变量概率时间序列预测设计的基础模型。Lag-Llama采用解码器-only的Transformer架构,通过将滞后值作为协变量来有效捕捉时间序列数据中的时间依赖性。
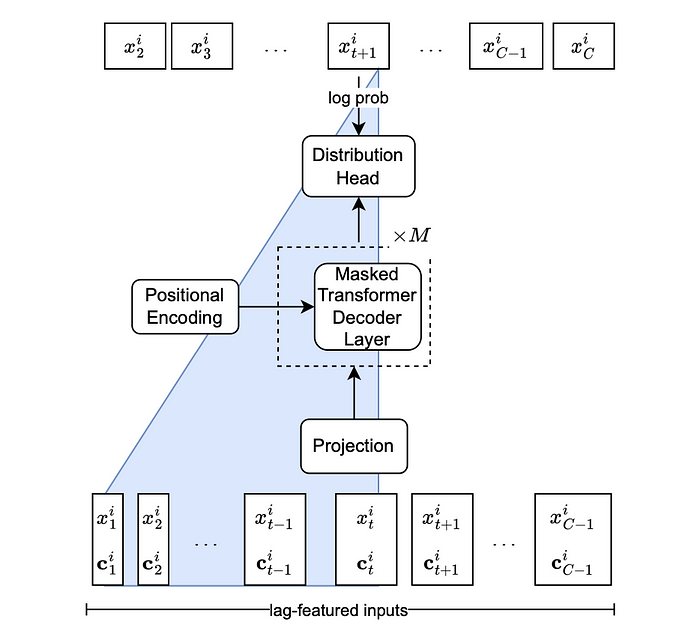
Lag-Llama学会根据滞后输入特征输出下一时间步值的分布。模型的输入是给定时间步单变量时间序列i的标记x。这里c指的是与时间步t的值一起使用的其他所有协变量,包括*|L|滞后、F日期时间特征和摘要统计量。输入通过M*掩码解码层投影。然后将特征传递到分布头并训练以预测下一时间步的预测分布参数。

Lag-Llama以其强大的预训练方法脱颖而出。利用来自各个领域的广泛时间序列数据集,Lag-Llama经过预训练以捕获复杂的时间模式。这种方法赋予Lag-Llama强大的零样本泛化能力。
现在,让我们看看Lag-Llama在基于历史数据预测科技巨头股价方面的表现如何。
2、预测
注意:所有命令都在Google Colab中测试过。将“/content”替换为您根目录。必要时在单元格中使用‘!’运行bash命令。
首先从包含Lag-Llama模型的GitHub存储库克隆并安装所需的包。
git clone https://github.com/time-series-foundation-models/lag-llama/
cd /content/lag-llama
pip install -r requirements.txt --quiet
然后从HuggingFace下载预训练模型权重 🤗。
huggingface-cli download time-series-foundation-models/Lag-Llama lag-llama.ckpt --local-dir /content/lag-llama
导入所需的包和可以用于预测的LagLlamaEstimator对象。
from itertools import islice
import matplotlib.dates as mdates
import pandas as pd
import torch
from gluonts.dataset.pandas import PandasDataset
from gluonts.dataset.repository.datasets import get_dataset
from gluonts.evaluation import Evaluator, make_evaluation_predictions
from lag_llama.gluon.estimator import LagLlamaEstimator
from matplotlib import pyplot as plt
创建一个Lag-Llama推理函数,可用于不同类型的数据集。该函数返回给定预测范围的预测。预测形状为(num_samples, prediction_length),其中num_samples是从每个时间步的预测概率分布中采样的样本数。
def _get_lag_llama_predictions(dataset, prediction_length, num_samples=100):
ckpt = torch.load("lag-llama.ckpt", map_location=torch.device("cuda:0"))
estimator_args = ckpt["hyper_parameters"]["model_kwargs"]
estimator = LagLlamaEstimator(
ckpt_path="lag-llama.ckpt",
prediction_length=prediction_length,
# pretrained length
context_length=32,
# estimator arguments
input_size=estimator_args["input_size"],
n_layer=estimator_args["n_layer"],
n_embd_per_head=estimator_args["n_embd_per_head"],
n_head=estimator_args["n_head"],
scaling=estimator_args["scaling"],
time_feat=estimator_args["time_feat"],
batch_size=1,
num_parallel_samples=100,
)
lightning_module = estimator.create_lightning_module()
transformation = estimator.create_transformation()
predictor = estimator.create_predictor(transformation, lightning_module)
forecast_it, ts_it = make_evaluation_predictions(
dataset=dataset, predictor=predictor, num_samples=num_samples
)
forecasts = list(forecast_it)
tss = list(ts_it)
return forecasts, tss
现在安装Yahoo Finance以下载股票价格。
# 使用最新版本
pip install yfinance==0.2.37
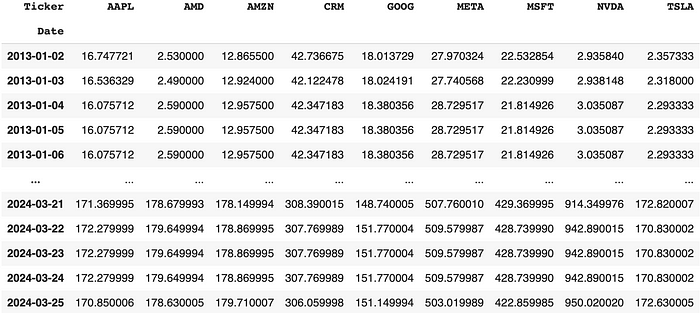
然后下载所列股票符号的收盘价。
import yfinance as yf
# 根据需要调整tickers、period和frequency
stock_prices = (
yf.Tickers("aapl amd amzn crm goog meta msft nvda tsla")
.history(period="max", start="2013-01-01")
.Close
.resample('1d')
.ffill()
)
stock_prices
像这样。
平滑价格并计算收益率。
# 根据需要调整平滑窗口
stock_returns = stock_prices.rolling(5).mean().pct_change().dropna()
创建数据集。
def _get_lag_llama_dataset(dataset):
# 避免突变
dataset = dataset.copy()
# 将数值列转换为`float32`
for col in dataset.columns:
if dataset[col].dtype != "object" and not pd.api.types.is_string_dtype(
dataset[col]
):
dataset[col] = dataset[col].astype("float32")
# 创建一个`PandasDataset`
backtest_dataset = PandasDataset(dict(dataset))
return backtest_dataset
backtest_dataset = _get_lag_llama_dataset(dataset=stock_returns)
prediction_length = 60 # 预测长度
num_samples = 1060 # 每个时间步从分布中采样的样本数
现在进行零样本推理。
forecasts, tss = _get_lag_llama_predictions(
backtest_dataset, prediction_length, num_samples
)
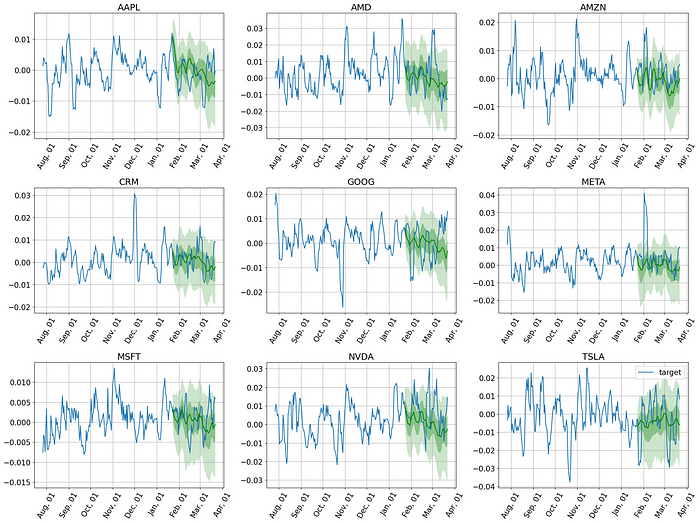
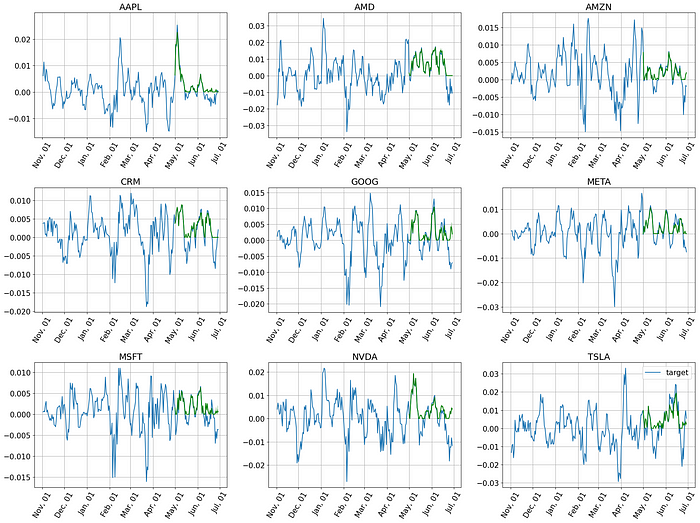
现在绘制模型在此数据集上的预测。
plt.figure(figsize=(20, 15))
date_formater = mdates.DateFormatter("%b, %d")
plt.rcParams.update({"font.size": 15})
# 遍历系列,绘制预测样本
for idx, (forecast, ts) in islice(enumerate(zip(forecasts, tss)), 9):
ax = plt.subplot(3, 3, idx + 1)
plt.plot(
ts[(-4 * prediction_length):].to_timestamp(),
label="target",
)
forecast.plot(color="g")
plt.xticks(rotation=60)
ax.xaxis.set_major_formatter(date_formater)
ax.set_title(forecast.item_id)
plt.gcf().tight_layout()
plt.legend()
plt.show()
期望得到这个。
或者,以累计收益或盈亏(pnl)的形式。
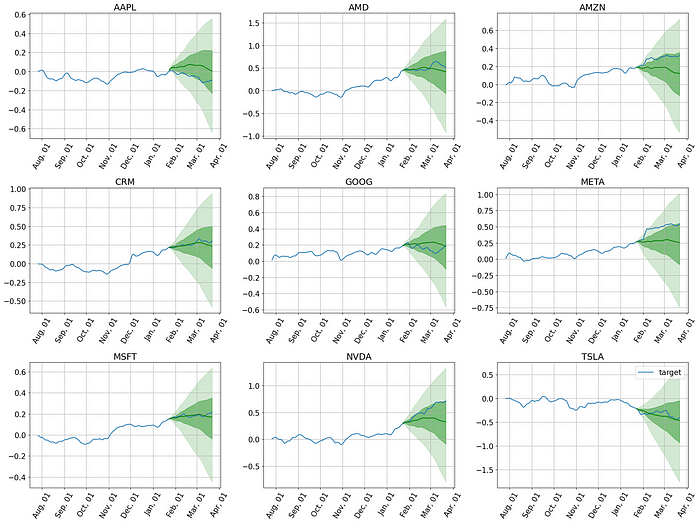
但等等,还有更多。
3、回测
预测很好,但如果我们将它们用于交易会怎样?让我们使用滚动窗口方法对模型进行回测,每季度重置投资组合权重。然后启动下一个季度回报的预测模型。如果预测的累计回报大于零,我们就买入资产;如果小于零,我们就卖出。最终权重按绝对值重新缩放至统一。佣金和做空费用也考虑在内。
结果表明,在交易中采用零样本预测意义不大。
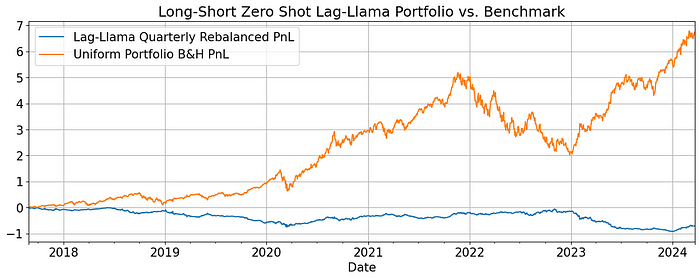
虽然模型可以帮助避免一些回撤,但在上升趋势期间仍会蒙受损失。
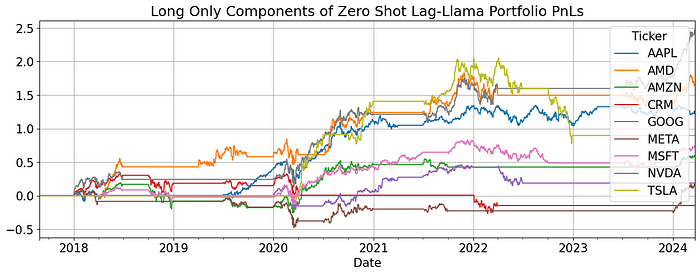
但这还不是全部。让我们尝试通过微调来增强模型。
4、微调
使用少量数据特定更改对Lag-Llama基础模型进行微调。
ckpt = torch.load("lag-llama.ckpt", map_location="cuda")
estimator_args = ckpt["hyper_parameters"]["model_kwargs"]
estimator = LagLlamaEstimator(
ckpt_path="lag-llama.ckpt",
prediction_length=prediction_length,
context_length=32,
# 根据需要调整
# distr_output="neg_bin",
# scaling="mean",
nonnegative_pred_samples=True,
aug_prob=0,
lr=5e-4,
# estimator args
input_size=estimator_args["input_size"],
n_layer=estimator_args["n_layer"],
n_embd_per_head=estimator_args["n_embd_per_head"],
n_head=estimator_args["n_head"],
time_feat=estimator_args["time_feat"],
# rope_scaling={
# "type": "linear",
# "factor": max(
# 1.0, (context_length + prediction_length) / estimator_args["context_length"]
# ),
# },
batch_size=64,
num_parallel_samples=num_samples,
trainer_kwargs={
"max_epochs": 50,
}, # <- lightning trainer arguments
)
训练预测器。
# 例如,使用前5年的数据
# 然后在其余数据集上进行测试
train_dataset = _get_lag_llama_dataset(stock_returns.iloc[:252*5])
predictor = estimator.train(
train_dataset,
cache_data=True,
shuffle_buffer_length=1000,
)
更新带有微调预测器的预测函数。
def _get_lag_llama_predictions(
dataset, prediction_length, num_samples=100, predictor=None,
):
ckpt = torch.load(
"lag-llama.ckpt", map_location=torch.device("cuda:0")
)
estimator_args = ckpt["hyper_parameters"]["model_kwargs"]
estimator = LagLlamaEstimator(
ckpt_path="lag-llama.ckpt",
prediction_length=prediction_length,
# pretrained length
context_length=32,
# estimator args
input_size=estimator_args["input_size"],
n_layer=estimator_args["n_layer"],
n_embd_per_head=estimator_args["n_embd_per_head"],
n_head=estimator_args["n_head"],
scaling=estimator_args["scaling"],
time_feat=estimator_args["time_feat"],
batch_size=1,
num_parallel_samples=100,
)
lightning_module = estimator.create_lightning_module()
transformation = estimator.create_transformation()
predictor = (
predictor
if predictor is not None
else estimator.create_predictor(transformation, lightning_module)
)
forecast_it, ts_it = make_evaluation_predictions(
dataset=dataset, predictor=predictor, num_samples=num_samples
)
forecasts = list(forecast_it)
tss = list(ts_it)
return forecasts, tss
现在,绘制微调模型在测试数据集上的预测,例如在初始5年数据上训练后:stock_returns.iloc[252*5:]。
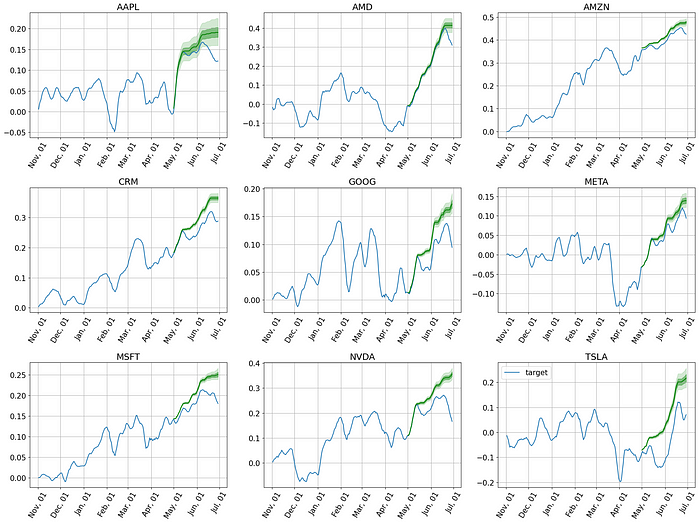
看起来好多了。让我们让回测再次变得伟大。
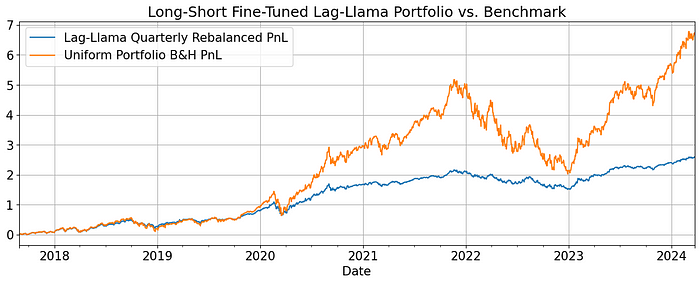
事实证明,通过简单的测试发现,Lag-Lama模型在股票价格预测的零样本方法中表现不佳。然而,即使对模型进行轻微微调也能改善收益结构并帮助平滑PnL。
这仅仅是开始;还有无数优化和迭代在前方。这包括寻找最佳参数、考虑各种波动率结构周期、数据清理和去噪、微调交易策略本身、计算交叉验证等。
原文链接:Stock Price Forecasting with Lag-Llama Transformers
汇智网翻译整理,转载请标明出处
