机器推理的圣杯=强化学习+提示
AI 的未来不是关于更大的模型,而是关于 更好的代理:能够推理、适应、规划 —— 使用提示进行交互,使用 RL 进行改进,并以数据为基础。

本文介绍如何将强化学习与高级提示工程结合,解锁下一代机器推理 ,以及你如何利用这一点来构建更智能的系统(是的,甚至在金融领域)使用数据 + 像EODHD这样的API。
1、为什么我们正进入机器推理的新时代
当今的AI模型擅长模式匹配和生成 —— 但它们并不总是能很好地进行 推理。它们可以复述事实,但在多步骤逻辑、动态适应或条件变化时会遇到困难。
这种情况正在迅速改变。最近的研究表明,当您将 强化学习 (RL) 与 提示工程 结合时,您会得到能够思考、计划和适应的机器。例如,一篇题为“强化学习中推理的目标是什么?”的论文展示了提示 + RL 如何将推理视为一种策略优化问题。 arXiv
同时,其他研究(如 PRL — 提示强化学习 研究)表明,提示本身可以通过 RL 进行优化,以推动 LLM 进入更深入、更结构化的推理。 arXiv
简而言之:
- 提示 定义了 模型被要求做什么。
- 强化信号 定义了 它做得有多好。
- 组合起来 = 机器能够推理,而不仅仅是反应。
2、提示 + RL 的逻辑:为什么有效
提示是人类意图和模型输出之间的软性接口。它们塑造了模型的执行方式、使用的上下文以及推理的结构。
例如,在“方向性刺激提示”论文中,他们展示了如何通过一个小的策略模型生成提示,引导更大的 LLM 向期望的行为发展。 arXiv
另一方面,强化学习封闭了反馈循环:根据其输出的推理质量,模型会获得奖励(或惩罚),并学习改进。这意味着模型不仅仅是在记忆 —— 它在优化策略。
当您将提示工程 + RL 结合时,您会得到一个代理:
- 选择如何措辞它的提示(通过提示策略)
- 执行链式思维,逐步推理
- 通过反馈改进其方法。
- 这些系统现在被研究人员称为 推理代理,并且正在迅速出现。 tribe.ai+1
3、构建你自己的推理代理
以下是您可以构建推理代理管道的方式:
- 步骤 1:定义任务和提示空间
决定您需要哪种推理:预测、解释、决策支持等。
创建一个带有占位符的提示模板:例如,
“分步骤解释你将如何评估 {asset} 给定 {market-data}。”
- 步骤 2:初始化提示策略模型
这个模型生成提示的不同变体(不同的措辞、结构)。
它通过 RL 训练以最大化下游性能。
- 步骤 3:链式思维执行
当模型回答时,您要求它 推理:
“让我们一步一步地思考…”
这会给出中间推理状态,而不仅仅是最终答案。
- 步骤 4:奖励与反馈
您评估推理:准确性、连贯性、新颖性、逻辑步骤。
将其反馈到 RL 中:
如果推理有效且有用,则奖励 = +1,如果错误或肤浅则奖励 = −1。
- 步骤 5:迭代和微调
随着时间的推移,提示策略和推理模型会适应。它们 改进 其思维方式 —— 而不仅仅是输出内容。
4、在金融中的应用:市场决策的推理代理
让我们具体化。假设您正在构建一个系统来 预测股票走势 或 决定交易入场点。您可以使用一个推理代理。
提示策略模型生成:
- “鉴于 {symbol} 的近期数据 + 宏观指标 + 情绪,你的预测和推理是什么?”
推理模型逐步执行:
- 分析近期趋势和波动性
- 解释基本面指标
- 评估风险/制度
- 提供决策和理由
您根据预测是否与实际结果一致、逻辑连贯性和风险调整价值来获得奖励。
对于数据可靠性?使用高质量的市场数据 API 如 EODHD 作为您的价格、基本面、情绪输入。干净、全球的数据 + 推理模型 = 优势。
5、为什么这是圣杯
因为它统一了三个重要的范式:
- 强化学习 用于策略优化。
- 提示工程 用于灵活的界面和推理框架。
- 数据驱动的洞察(通过 EODHD 等 API)作为事实基础。
它们共同创造出不仅输出 —— 而是推理、证明、适应的代理。这远不止于“预测价格” —— 这是 智能决策。
对于金融来说,这意味着从“一次性模型”到 持续推理循环,这些循环从市场中学习,适应策略,并证明行动 —— 就像一个人类量化团队,但可编程。
6、挑战与注意事项
- 奖励设计:定义一个真正捕捉推理质量的奖励函数,而不仅仅是表面准确性,是很困难的。
- 提示空间爆炸:存在许多变体;您的提示策略必须明智地探索。
- 数据质量和偏差:任何推理代理的质量都取决于其数据 —— 干净、无偏的数据输入至关重要。
- 可解释性:推理链有助于理解 —— 但您希望透明度以信任决策。
最近的研究表明,通过 RL 可以自然地产生推理,而不需要大量的人工标注。 Nature 这令人兴奋 —— 但也意味着设计安全、稳健的系统至关重要。
7、Python 实现:强化学习 + 提示优化
1️⃣ 设置:导入并初始化
import random
import numpy as np
from sklearn.metrics import mean_squared_error
from transformers import pipeline
# 推理模型(您可以替换为开放模型或 API)
reasoning_model = pipeline("text-generation", model="gpt2")# 模拟市场数据(实际上,通过 EODHD API 获取)
price_data = np.random.normal(100, 5, 50) # 占位符
2️⃣ 定义提示策略
提示策略 将随机探索提示变体并学习哪些表现最好。
# 初始提示变体(提示空间)
prompts = [
"使用基本面和技术分析来分析 {symbol} 股票。",
"逐步推理 {symbol} 价格变动。",
"鉴于市场数据,解释 {symbol} 的可能趋势及其原因。",
"预测 {symbol} 的下一步走势并逻辑上说明您的推理。"
]
def generate_prompt(symbol):
"""选择一个随机的提示结构进行探索。"""
return random.choice(prompts).format(symbol=symbol)
3️⃣ 模拟奖励函数
奖励 = 推理输出的 有用性 和 准确性。
我们将用一个基本逻辑模拟:推理质量越高 → 奖励越高。
def evaluate_reasoning_output(output, actual_price_change):
"""
模拟奖励:
- 惩罚不连贯或浅显的推理。
- 奖励逻辑性强、数据驱动的解释(此处为模拟)。
"""
keywords = ["趋势", "动量", "支撑", "风险", "波动率"]
score = sum(k in output.lower() for k in keywords) / len(keywords)
# 奖励与推理深度和预测准确性对齐
forecasted_change = random.uniform(-2, 2) # 占位符
accuracy_penalty = mean_squared_error([actual_price_change], [forecasted_change])
reward = score - 0.1 * accuracy_penalty
return reward
4️⃣ 强化学习循环
在这里,提示策略学习哪些提示会产生更高的推理奖励。
symbol = "AAPL"
rewards = []
for episode in range(10):
prompt = generate_prompt(symbol)
response = reasoning_model(prompt, max_length=100, num_return_sequences=1)[0]['generated_text']
actual_price_change = random.uniform(-1, 1) # 模拟每日变动
reward = evaluate_reasoning_output(response, actual_price_change)
rewards.append((prompt, reward))
print(f"第 {episode+1} 轮 | 奖励: {reward:.3f}\n提示: {prompt}\n")
5️⃣ 优化提示策略
经过探索后,系统会识别出高奖励提示(即最佳推理形式)。
# 按平均奖励对提示进行排序
prompt_scores = {}
for p, r in rewards:
prompt_scores.setdefault(p, []).append(r)
avg_rewards = {p: np.mean(rs) for p, rs in prompt_scores.items()}
best_prompt = max(avg_rewards, key=avg_rewards.get)print("\n🏆 最佳表现提示结构:")
print(best_prompt)
8、它如何工作(概念上)
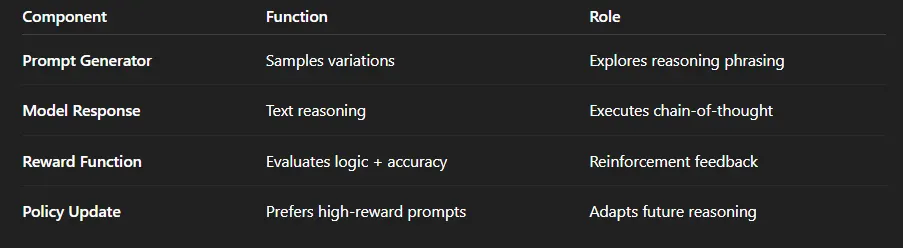
借助 EODHD 的 实时和历史数据,这种结构可以演变为一个完全自适应的 交易或预测推理代理,学习哪些提示策略能产生最准确、可解释和盈利的见解。
升级路径:
- 将随机数据替换为 EODHD 股票/基本面 API。
- 实现轻量级 RL 策略(例如 Q-learning 或 PPO)。
- 添加推理验证层(连贯性、事实正确性)。
- 动态存储最佳提示模板到您的管道中。
示例 EODHD 数据集成
import requests
symbol = "AAPL"
api_token = "YOUR_EODHD_API_KEY"url = f"https://eodhd.com/api/eod/{symbol}.US?api_token={api_token}&fmt=json"
data = requests.get(url).json()# 使用此干净的价格数据作为推理输入
latest_close = data[-1]['close']
print(f"{symbol} 最新收盘价: ${latest_close}")
这确保了您的推理代理基于 真实、高质量的数据 来自可信来源 —— 这在训练金融逻辑的推理反馈循环时至关重要。
最后一点。
这就是您 弥合 LLM 与 AI 系统之间差距 的方式 —— LLM 会说话,而 AI 系统会思考。
奖励循环将提示转化为 学习 —— 当您用可靠的 EODHD 市场数据喂养它时,您正在构建金融领域的下一代 自主推理代理。
9、结束语:从反应到推理
AI 的未来不是关于更大的模型。
而是关于 更好的代理:能够推理、适应、规划 —— 使用提示进行交互,使用 RL 进行改进,并以数据为基础。
如果您将这与像 EODHD API 这样的优质数据源结合,您可以构建系统,它们不只是跟随市场 —— 而是思考市场。
真正的优势? 当您的算法不仅仅是 预测 价格 —— 而是 推理 价格。
原文链接:Decoding the AI Future: Reinforcement Learning + Prompts = The Holy Grail of Machine Reasoning
汇智网翻译整理,转载请标明出处
