Anthropic:MCP 的新定位
MCP 在演示中运行得非常完美,但一旦你尝试扩展它,就会出现问题。Anthropic没有否认这一点。

让我们诚实一点。
MCP 在演示中运行得非常完美,但一旦你尝试扩展它,就会出现问题。
一个 GitHub 上的 MCP 服务器可以暴露九十多工具。这比五万个 tokens 的 JSON 模式和描述加载到模型的工作内存中,甚至在它开始思考你的提示之前。
因此,当 Anthropic 引入 Skills 时,我没有看到一个新功能。
我看到了一次方向调整。
一种安静的调整。
但无论如何,它仍然是一个方向调整。
1、MCP 真正的问题不是工具本身
从内部来看,MCP 的概念其实很简单。
你运行一个或多个 MCP 服务器。
每个服务器暴露一组工具,每个工具都有一个模式,客户端将这些定义加载到模型的上下文中,以便它可以决定调用哪些工具以及如何调用它们。理论上,这给了模型一个干净、类型化的与外部世界交互的接口。
但实际上,“干净的接口”变成了一个喷泉。
每个工具模式都被塞进上下文窗口中。不管你是让模型读取文件、查询数据库还是只是总结一段文字,模型仍然需要在完整的工具列表、参数和描述中穿行,以确定什么可能是相关的。
现在再加上工具调用准确率是累积的。如果单个工具调用的准确率是 90%,那么串联五个工具会将准确率降到 0.⁹⁵,也就是不到 60%。无尽的 Reddit 帖子明确指出:随着调用次数的增加,工具调用的准确性会呈指数级下降。
结果是一组糟糕的组合:
- 大量的上下文窗口被用于可能永远不会使用的模式。
- 对话历史加上全局工具定义和任务特定上下文都在争夺空间。
- 多步骤工作流程一开始表现良好,但随后由于模型失去对早期约束的记忆而逐渐失败。
我亲眼目睹过这种情况在真实系统中发生。任务很简单。工具是正确的。失败来自于认知过载。模型被要求推理、规划并选择工具,同时将其整个工具宇宙记在脑海中。
今天大多数人实施的 MCP 不只是暴露工具。
它暴露的是 太多 工具。
2、Anthropic 的答案并不是修补 MCP
他们针对的是实际破裂的模式:静态的、提前暴露的模式。
Skills 改变了流程。
一个 Skill 是一个文件夹。在这个文件夹中,你会得到一个 SKILL.md 文件,其中包含 YAML 前置信息(名称、描述、元数据),然后是详细的说明、参考资料,以及可选地链接到同一目录中的其他文件。
启动时,代理不会完整地阅读每个技能。它只获取每个技能的最小元数据,并将其放入系统提示中。这使 Claude 只能获得足够的信息来知道 何时 一个技能可能相关,而不必承担加载所有内容的成本。
当用户提出请求时,Claude 会进行逐步披露过程:
- 查看已安装技能的名称和描述。
- 如果某个技能似乎相关,使用文件系统工具打开 SKILL.md。
- 如果该文件引用了其他文档(如 forms.md 或 reference.md),则仅在需要时读取那些文档。
- 如果技能包含脚本,则通过代码执行环境运行它们,而不是试图通过 token 生成“模拟”它们。
关键是上下文是分层的,而不是一次性全部加载。
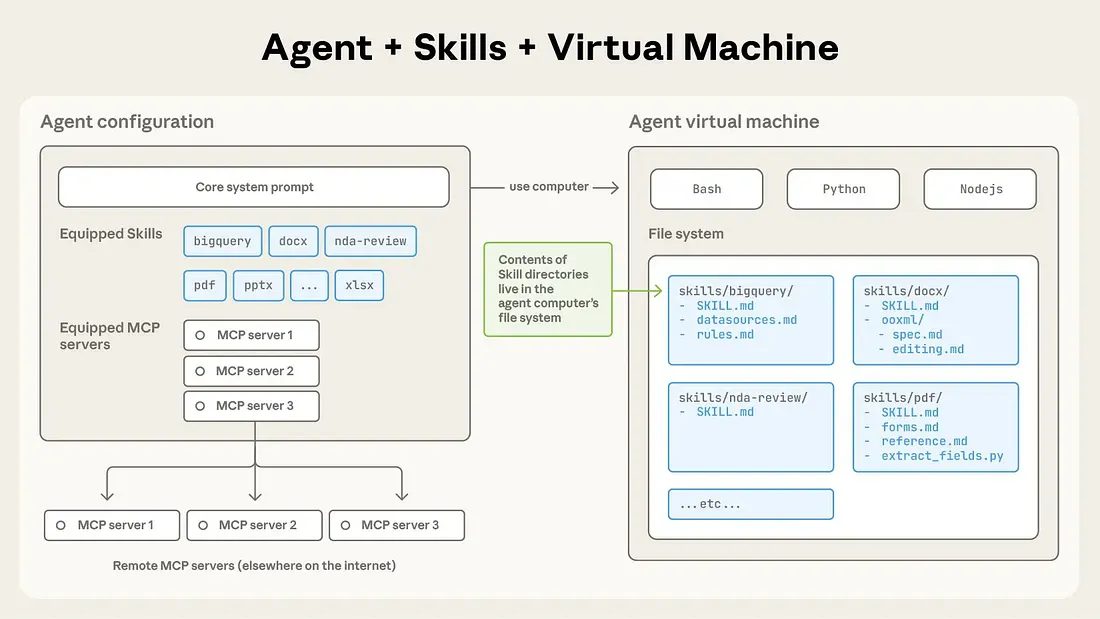
你可以将大量知识打包成一个技能。多个 markdown 文件。示例。指标定义。甚至是完整的 Python 脚本,它们在代理环境中像确定性的微服务一样运行。但直到 Claude 认为对于当前任务相关时,这些内容才进入上下文窗口。
这就是大多数 MCP 设置行为的反面。
而且 Skills 不仅仅是一个 Claude UI 技巧。它们在 Claude 应用程序、Claude Code、API 和 Agent SDK 中都受到支持,所有这些都连接到同一个代码执行工具,为代理提供了一个安全的环境来运行脚本。
因此,与其说“MCP 是坏的”,Anthropic 做了更有趣的事情:他们改变了模型 如何 与 MCP 相遇。
Skills 在前面。MCP 在后面。
3、RAG-MCP = Skills + MCP
Skills = 检索。MCP = 工具。加起来 = RAG-MCP。
如果你曾经构建过检索增强生成(RAG),这个模式应该很熟悉。
在 RAG 中,你不把整个知识库塞进上下文窗口。你将其单独存储,使用索引检索只有相关的内容,然后让模型在工作时阅读该部分。
Skills 对工具和程序性知识做了同样的事情。
- “索引”是技能元数据:名称、描述、标签。
- “文档”是 SKILL.md 正文以及任何链接的文件。
- “回答步骤”是指令、代码的组合,以及(必要时)封装在该技能中的 MCP 调用。
而不是将每个 MCP 工具模式都塞进上下文,你可以将它们绑定到特定的工作流中:
- “PDF 表单填写”技能,知道要使用哪个 MCP 服务器和脚本。
- “营销分析洞察”技能,使用 Python 来处理 CSV 文件,并在需要时调用工具。
- “将推文转为新闻通讯”技能,基于你自己的写作风格示例和辅助代码构建。
模型不再需要了解系统中的所有工具。
它只需要知道哪个技能是相关的,而技能知道如何协调其余部分。
这就是实践中的 RAG-MCP:
- 检索正确的技能。
- 仅加载与之相关的说明和参考。
- 执行代码以完成确定性步骤。
- 当工作流需要时,作为最后一步集成 MCP 工具。
Skills 不与 MCP 竞争。
它们驯服了 MCP。
4、这对真正构建代理的人意味着什么
如果你只是连接玩具项目,你可以强行实现很多东西。上下文窗口很大,演示时间短,工具很少。MCP 感觉还行。
一旦你进入:
- 多租户系统,
- 长期对话,
- 高风险工作流(合规、金融、安全),
- 或者多代理网络,其中工具调用工具,
裂缝就显现出来了。
你会开始看到:
- 模型觉得合理但对你来说不合理的工具选择,
- 技术上符合模式但违反业务逻辑的幻觉参数,
- 工作流在第一天有效,但在第七天因为对话历史现在与工具定义争夺上下文空间而偏离轨道。
你可以绕过这些问题。我也做过。
- 你可以修剪模式,拆分服务器,重写描述使其更简短。
- 你可以创建监督代理,试图引导主代理回到轨道上。
- 但你仍然在与底层模式作斗争:模型在触及任务之前就已经被工具压垮了。
Skills 改变了问题的态势。
你从“模型必须理解系统中的每个工具”转变为“模型必须为工作选择正确的技能,而技能将只带来它需要的东西”。
这是一个更理智的心理模型。
这也符合我们培训人类的方式。
我们不会在新同事的第一天就给他们完整的维基百科,期望他们记住它。我们会给他们一个入门指南,然后在他们遇到实际任务时指向特定的文档和脚本。
Skills 将这一模式正式化为代理。
5、更好的前进路径
我对 Anthropic 如何处理这个问题感到敬佩。
- 他们没有发表一篇“MCP 的现状”文章。
- 他们没有宣布协议已经死亡。
- 他们没有试图假装上下文膨胀只是用户的错误。
他们默默地发布了一种机制,接受大型工具生态系统的现实,并为代理提供了一种与之互动的方式,而不会因重量而崩溃。
- Skills 是可组合的。
- 可在产品间移植。
- 高效,因为它们只加载所需的内容。
- 并且强大,因为它们可以在可靠性比纯生成更重要的时候引入代码执行。
最重要的是,他们承认了我们很多人在开放环境中构建时所感受到的事情:
- 代理的未来不是更多工具的堆叠。
- 而是与工具更好的关系。
- 一个以检索和编排优先的关系。
- 一个将上下文视为稀缺资源而非无限倾倒场的关系。
MCP 仍然存在,但它不再压在模型的胸口上。
Anthropic 没有放弃 MCP。他们让它变得可生存。
而对于那些试图构建能做实际工作的代理的人来说,这种安静的转变比任何协议公告都更有意义。
原文连接:MCP Is Broken and Anthropic Just Admitted It
汇智网翻译整理,转载请标明出处
