AI上下文管理的六条军规
如何在保持跨多次对话和重启时回忆关键事实的同时,仅保留有用的上下文内容?本文介绍6个核心规则。

长时间聊天会变得臃肿,工具调用堆积,提示变得沉重。质量下降,延迟上升,成本飙升。
挑战:在保持跨多次对话和重启时回忆关键事实的同时,仅保留有用的上下文内容。
解决方案:六条规则协同工作:
- 三个缓冲区(最近的对话、运行摘要、实体清单)
- 可恢复状态的代理图
- 热内存与冷内存(交换进出)
- 自适应检索(门控 → 草稿 → 批评)
- HyDE查询扩展(对瘦查询更强的回忆)
- 压缩 + 重新排序(每token更多的信号)
展示这些模式的产品:
- Cursor —— 线程摘要和你最新编辑周围的快速上下文。
- Claude Code / Copilot Chat —— 限制到活动文件/差异并保持轻量级状态。
- Notion AI —— 按部分级别摘要,这样你可以只提取你需要的部分。
- Linear/Height AI助手 —— 实体式记忆(问题ID、负责人、日期),为回答提供信息。
将它们作为你自己的堆栈的思维模型。
所有LangGraph示例都避免命名冲突:状态键是名词,节点ID是动词。替换为你的模型/API密钥。
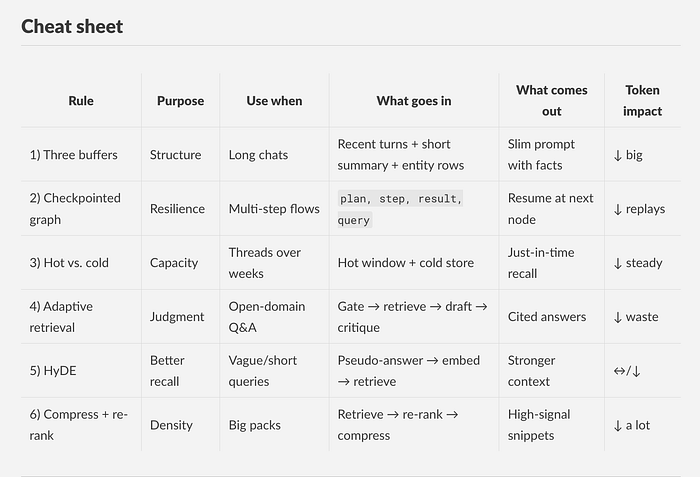
1、三个缓冲区(最近、摘要、实体)
巨大的历史记录会变成噪音。保持三个通道:一个小窗口的最近对话,一个简短的事实摘要,以及一个实体清单(人/组织/时间/ID)。只提供需要的内容。
示例(LangChain,最小且直接)
# pip install -U langchain langchain-openai
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
recent = [] # ["U: ...", "A: ..."]
summary = "" # <= 8 lines
entities = {} # {"person": ["Priya"], "org": ["Acme"], "when": ["Tue 3pm"]}
prompt = PromptTemplate.from_template("""Be concise and factual.
Entities: {entities}
Summary: {summary}
Recent:
{recent}
User: {q}
Assistant:""")
def ask(q: str):
global summary, recent
out = (prompt | llm).invoke({
"entities": entities,
"summary": summary,
"recent": "\n".join(recent[-8:]),
"q": q,
}).content
recent += [f"U: {q}", f"A: {out}"]
summary = llm.invoke(
f"Summarize key facts only (<=8 lines):\n{summary}\n\nLatest:\nU:{q}\nA:{out}\n---\nSummary:"
).content
return out
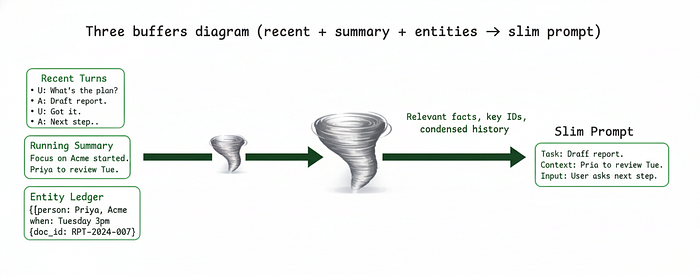
2、检查点计划,而不是闲聊
持久化计划/步骤/结果,这样崩溃或重试不会重新播放整个线程。
示例(LangGraph + 检查点器)
# pip install -U langgraph
from typing import TypedDict
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.memory import MemorySaver
class AState(TypedDict):
plan: str
step: int
result: str
query: str
def plan_step(s: AState): return {"plan": "1) search 2) answer", "step": 1}
def act_step(s: AState): return {"result": f"(search for '{s['query']}')", "step": 2}
def finalize_step(s: AState):return {"result": f"Answer based on {s['result']}"}
g = StateGraph(AState)
g.add_node("plan_step", plan_step)
g.add_node("act_step", act_step)
g.add_node("finalize_step", finalize_step)
g.set_entry_point("plan_step")
g.add_edge("plan_step", "act_step")
g.add_edge("act_step", "finalize_step")
g.add_edge("finalize_step", END)
app = g.compile(checkpointer=MemorySaver())
cfg = {"configurable": {"thread_id": "ctx-graph-1"}}
state = app.invoke({"query":"Acme India HQ","step":0,"plan":"","result":""}, config=cfg)
print(state["result"])
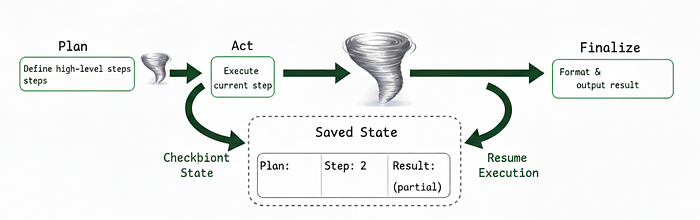
3、热内存与冷内存
热 = 小的原始窗口。冷 = 存储中的笔记/摘要/工具输出。切换以保持提示简洁。
示例(小的交换器 + 回忆)
from collections import deque
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
HOT_MAX_CHARS = 1500
hot = deque([], maxlen=12) # raw turns
cold = [] # summarized notes
def spill():
global hot, cold
while sum(len(x) for x in hot) > HOT_MAX_CHARS and len(hot) > 6:
cold.append(" | ".join(list(hot)[:4]))
for _ in range(4): hot.popleft()
def recall(q: str):
return [n for n in cold if any(w in n.lower() for w in q.lower().split())][:2]
def answer(q: str):
ctx = "\n".join(recall(q))
hist = "\n".join(list(hot)[-6:])
out = llm.invoke(f"Notes:\n{ctx}\n\nRecent:\n{hist}\n\nUser:{q}\nAnswer:").content
hot.extend([f"U:{q}", f"A:{out}"])
spill()
return out
4、自适应检索(门控 → 草稿 → 批评)
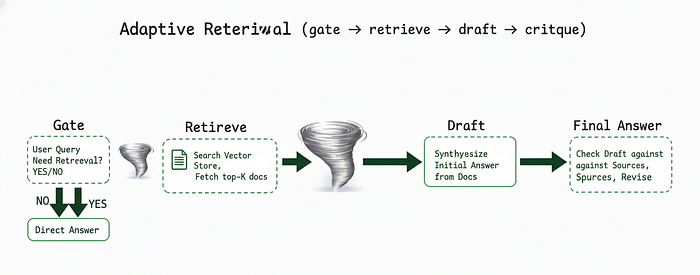
除非需要,否则不要获取文档。首先进行门控。如果需要,检索、草稿,然后根据来源进行批评。
示例(LangGraph)
# pip install -U langgraph langchain langchain-openai faiss-cpu
from typing import TypedDict, List
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.memory import MemorySaver
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
emb = OpenAIEmbeddings()
store = FAISS.from_texts([
"Acme policy on leave",
"Acme address Bangalore: MG Road, Bengaluru 560001",
"Client Priya notes"
], emb)
retriever = store.as_retriever(search_kwargs={"k": 4})
class RState(TypedDict):
q: str
ctx: List[str]
draft_text: str
final_answer: str
def gate_node(s: RState):
d = llm.invoke(f"Q: {s['q']}\nNeed external retrieval? YES or NO.").content.strip().upper()
ctx = [d.page_content for d in retriever.get_relevant_documents(s["q"])] if "YES" in d else []
return {"ctx": ctx}
def write_draft(s: RState):
draft = llm.invoke(f"Context:\n{s['ctx']}\n\nQ:{s['q']}\nDraft:").content
return {"draft_text": draft}
def critique(s: RState):
final = llm.invoke(f"Draft:\n{s['draft_text']}\nSources:\n{s['ctx']}\nRevise if needed; else return draft.").content
return {"final_answer": final}
g = StateGraph(RState)
g.add_node("gate_node", gate_node)
g.add_node("write_draft", write_draft)
g.add_node("critique", critique)
g.set_entry_point("gate_node")
g.add_edge("gate_node","write_draft")
g.add_edge("write_draft","critique")
g.add_edge("critique", END)
app = g.compile(checkpointer=MemorySaver())
cfg = {"configurable": {"thread_id": "selfrag-1"}}
out = app.invoke({"q":"Where is Acme's Bangalore office?","ctx":[],"draft_text":"","final_answer":""}, config=cfg)
print(out["final_answer"])
5、HyDE查询扩展
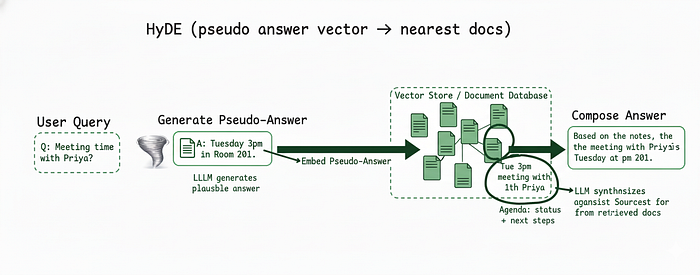
瘦查询表现不佳。生成一个简短的假设性答案,嵌入该答案,然后检索靠近它的实际文档。
示例(LangGraph)
from typing import TypedDict, List
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.memory import MemorySaver
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
emb = OpenAIEmbeddings()
store = FAISS.from_texts(["Tue 3pm meeting with Priya", "Room 201", "Agenda: status + next steps"], emb)
class HState(TypedDict):
q: str
pseudo_text: str
ctx: List[str]
answer_text: str
def make_pseudo(s: HState):
p = llm.invoke(f"Write a concise hypothetical answer (<=2 lines) to:\n{s['q']}").content
return {"pseudo_text": p}
def retrieve_ctx(s: HState):
vec = emb.embed_query(s["pseudo_text"])
docs = store.similarity_search_by_vector(vec, k=3)
return {"ctx": [d.page_content for d in docs]}
def compose_answer(s: HState):
a = llm.invoke(f"Context:\n{s['ctx']}\n\nQ:{s['q']}\nA:").content
return {"answer_text": a}
g = StateGraph(HState)
g.add_node("make_pseudo", make_pseudo)
g.add_node("retrieve_ctx", retrieve_ctx)
g.add_node("compose_answer", compose_answer)
g.set_entry_point("make_pseudo")
g.add_edge("make_pseudo","retrieve_ctx")
g.add_edge("retrieve_ctx","compose_answer")
g.add_edge("compose_answer", END)
app = g.compile(checkpointer=MemorySaver())
cfg = {"configurable": {"thread_id": "hyde-1"}}
print(app.invoke({"q":"Meeting time with Priya?","pseudo_text":"","ctx":[],"answer_text":""}, config=cfg)["answer_text"])
6、压缩 + 重新排序
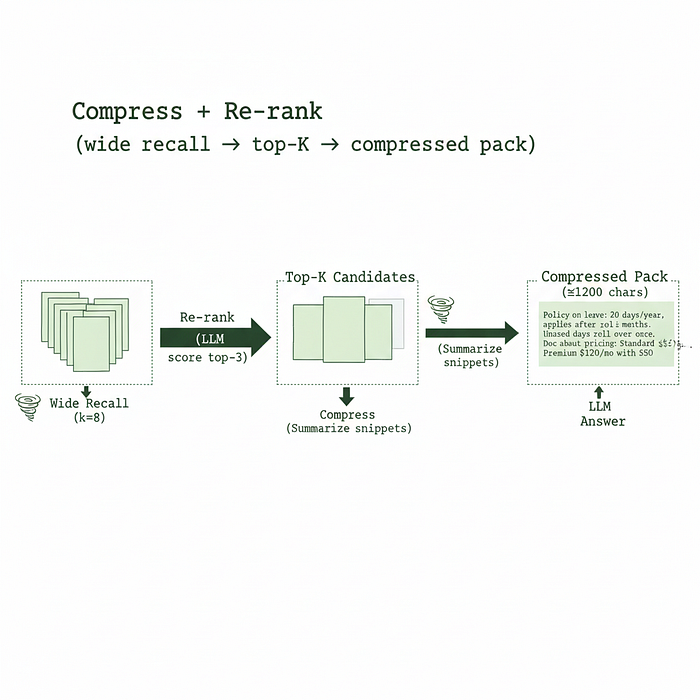
不要把所有东西都塞进提示中。广泛检索,用模型重新排序,然后压缩最终内容。
示例(LangChain)
# pip install -U langchain langchain-openai faiss-cpu
from typing import List
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
store = FAISS.from_texts(
["Doc about pricing", "Doc about schedules", "Doc about addresses", "Doc about leave policy"],
OpenAIEmbeddings()
)
def rerank(q: str, cands: List[str]) -> List[str]:
scored = []
for c in cands:
s = llm.invoke(f"Query:{q}\nCandidate:{c}\nRelevance 0-1 (float only):").content.strip()
try: scored.append((float(s), c))
except: pass
scored.sort(reverse=True)
return [c for _, c in scored[:3]]
def compress(texts: List[str], max_chars=1200) -> str:
out, total = [], 0
for t in texts:
chunk = t.split("\n")[0][:400]
if total + len(chunk) > max_chars: break
out.append(chunk); total += len(chunk)
return "\n".join(out)
def answer(q: str):
raw = [d.page_content for d in store.similarity_search(q, k=8)]
top = rerank(q, raw)
ctx = compress(top)
return llm.invoke(f"Context:\n{ctx}\n\nQ:{q}\nA:").content
print(answer("What is the leave policy?"))
仓库: akhil-reni/context-management
7、结束语
保持上下文紧凑,状态明确,并选择性地检索。你可以得到更清晰的答案,更低的成本,更高的吞吐量——而无需将你的提示变成垃圾场。
原文链接:Context Management — a practical guide for agentic AI
汇智网翻译整理,转载请标明出处
