8个构建语音AI代理的最佳平台
构建语音AI应用可能会令人望而生畏。多个方面包括后端基础设施、音频质量、延迟等。出于这些原因,您可以依赖框架、SDK和API来创建具有语音作为主要应用功能的AI解决方案。

像Siri和Alexa这样的语音助手对于非复杂的日常个人辅助任务非常有用。然而,它们在提供复杂问题的准确答案、实时信息、处理轮次和用户中断方面存在限制。
试着问Siri某个特定城市或地点最适合带孩子做的事情。它不会提供准确的答案,因为它无法访问网络搜索工具。在支持Apple Intelligence的设备上,提出同样的问题会转交给ChatGPT。
就像应用内的对话应用程序功能一样,语音代理旨在解决这些限制。
以下部分将帮助您发现如何构建AI语音代理以及最佳创建平台。虽然这篇文章不需要,但您可以设置一个本地 Node.js 服务器,并在 SwiftUI 中运行我们的 演示 iOS/iPadOS 语音代理。设置好本地 Node 服务器后,您还可以通过以下逐步教程测试其他平台的对话代理:
什么是AI语音代理?
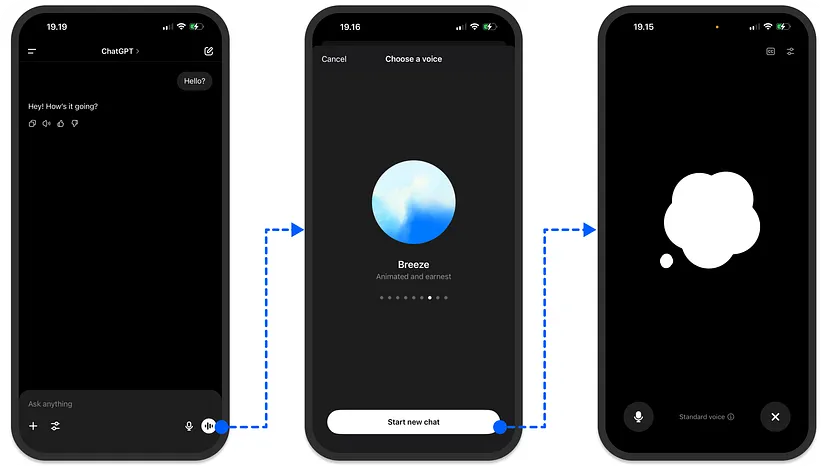
语音代理是一种能够使用本地或基于云的LLM实时接收用户指令并以人类声音做出响应的对话AI助手。
与文本生成代理类似,基于语音的代理使用LLM输出音频响应。最好的理解方式是考虑ChatGPT的语音模式,如上图所示。只需点击一个按钮并选择您偏好的语音,您就可以轻松地与ChatGPT进行实时对话。
在接下来的部分中,我们将探讨构建类似ChatGPT语音模式体验的顶级平台。
为什么构建语音代理?
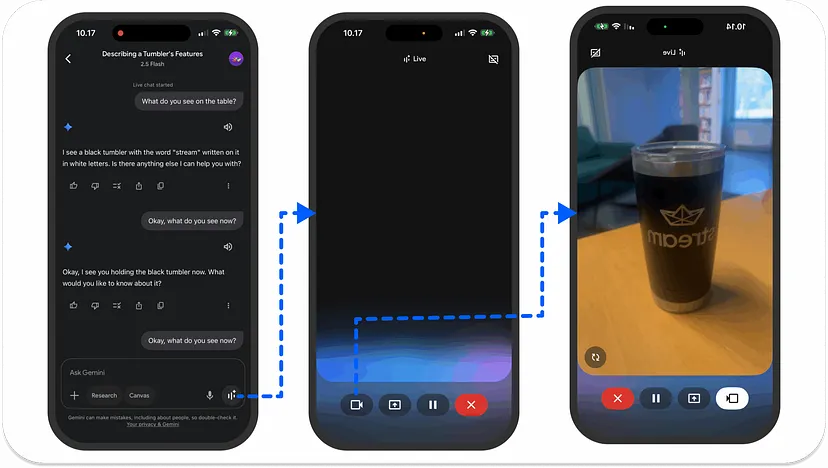
与基于文本的AI代理一样,MCP在语音应用中的支持有助于代理从Perplexity和Exa等服务中检索准确的实时信息。通过MCP,您可以构建一个代理,通过语音交互管理任务。您还可以将语音代理连接到MCP工具以进行自定义工作流程。
在创建您的语音AI应用时,可能需要支持多种口音。幸运的是,像OpenAI Agents SDK这样的主要平台提供了语音库供您选择。基于语音的代理可以应用于许多领域,包括销售、营销、客户服务、小企业和企业。
- 视频AI:语音代理在视频AI场景中的一个优秀用例是Gemini Live。它使用您的手机摄像头来观察和理解周围的物体,并通过语音交互提供答案。Gemini Live还允许用户共享其手机设备的屏幕,以询问所选屏幕上的内容的问题。
查看语音演示。
- 销售线索:使用语音代理来跟进和联系潜在客户,用于企业及小型企业的内部销售。
- 客户服务和呼叫中心:语音代理可以接收客户投诉并帮助解决问题。
- 个人助理:像Gemini Live一样,您可以创建一个语音系统来帮助您了解周围环境和您正在看的内容。另一个热门的应用领域是计算机和浏览器使用。您可以将语音系统与AI浏览器代理集成,以自动化在线预订和预约安排。
- 社交平台:构建语音代理以在社交社区中与人们互动,为用户的查询提供实时语音响应。
- 游戏:使用语音代理为在线游戏平台构建角色对话和互动叙述系统。
- 远程医疗:在远程医疗场景中,使用AI语音与患者互动并在线收集他们的信息。
构建语音启用应用的前8大平台
构建语音AI应用可能会令人望而生畏。多个方面包括后端基础设施、音频质量、延迟等。出于这些原因,您可以依赖框架、SDK和API来创建具有语音作为主要应用功能的AI解决方案。
这些语音代理构建平台中的大多数都采用Python优先的方法。基于TypeScript的选项现在正在赶上。
让我们看看领先的解决方案以及如何快速使用它们进行构建。
1、Stream Python AI SDK:集成应用内语音AI
Stream 允许开发人员使用 React、Swift、Android、Flutter、JavaScript 和 Python 构建实时 音频应用。通过最小的努力,最近发布的 Python AI SDK 帮助开发人员创建复杂的语音 AI 服务,例如会议助手和 视频会议 的机器人。
您可以使用 Python SDK 进行语音转录、语音活动检测 (VAD)、语音转文本以及反之亦然。除了这些功能外,您还可以将您的 Stream 驱动的语音 AI 应用程序与其他领先平台集成和扩展,例如:
该 SDK 的基础建立在 WebRTC 和 OpenAI 实时 API 上,以实现低延迟通信。
1.1 开始使用 Stream Python AI SDK
使用 Stream 的 Python AI SDK 创建第一个语音应用需要几个步骤:
a) 设置 Python 环境并安装必要的依赖项。您可以使用此命令配置 Python 虚拟环境。
python3 -m venv venv && source venv/bin/activate
您也可以使用 uv 设置它,并在项目的根目录中添加 .env 文件,并填写以下内容:
STREAM_API_KEY=your-stream-api-key
STREAM_API_SECRET=your-stream-api-secret
STREAM_BASE_URL=https://pronto.getstream.io/
OPENAI_API_KEY=sk-your-openai-api-key
在 Stream 仪表板 上注册帐户,创建一个应用,并获取其 API 密钥和密钥以替换上述占位符。使用 STREAM_BASE_URL,您可以在浏览器中创建和加入 Stream 视频通话。
接下来,运行以下命令来安装 Python AI SDK。
pip install --pre "getstream[plugins]"
# 或使用 uv
uv add "getstream[plugins]" --prerelease=allow
b) 初始化 Stream 客户端和用户,并创建通话。
from dotenv import load_dotenv
from getstream import Stream
from getstream.models import UserRequest
from uuid import uuid4
import webbrowser
from urllib.parse import urlencode
# 加载环境变量
load_dotenv()
# 从 ENV 初始化 Stream 客户端
client = Stream.from_env()
# 生成新的用户 ID 并创建新用户
user_id = f"user-{uuid4()}"
client.upsert_users(UserRequest(id=user_id, name="My User"))
# 我们稍后可以用它来加入通话
user_token = client.create_token(user_id, expiration=3600)
# 生成一个 OpenAI 机器人用户 ID,稍后添加
bot_user_id = f"openai-realtime-speech-to-speech-bot-{uuid4()}"
client.upsert_users(UserRequest(id=bot_user_id, name="OpenAI Realtime Speech to Speech Bot"))
# 创建带有新生成 ID 的通话
call_id = str(uuid4())
call = client.video.call("default", call_id)
call.get_or_create(data={"created_by_id": bot_user_id}Create an OpenAI speech-to-speech pipeline.
c) 创建 OpenAI 语音到语音管道。
以下代码片段允许您通过初始化 SDK 的 OpenAIRealtime 类并使用 Web 浏览器启动通话来创建语音到语音管道:
sts_bot = OpenAIRealtime(
model="gpt-4o-realtime-preview",
instructions="You are a friendly assistant; reply in a concise manner.",
voice="alloy",
)
try:
# 连接 OpenAI 机器人
async with await sts_bot.connect(call, agent_user_id=bot_user_id) as connection:
# 从用户侧发送消息到 OpenAI
await sts_bot.send_user_message("Give a very short greeting to the user.")
except Exception as e:
# 处理异常
finally:
# 完成后删除用户
client.delete_users([user_id, bot_user_id])
base_url = f"{os.getenv('EXAMPLE_BASE_URL')}/join/"
# 令牌是我们之前从客户端生成的用户令牌。
params = {"api_key": client.api_key, "token": user_token, "skip_lobby": "true"}
url = f"{base_url}{call_id}?{urlencode(params)}"
try:
webbrowser.open(url)
except Exception as e:
print(f"Failed to open browser: {e}")
print(f"Please manually open this URL: {url}")
当您将上述步骤中的代码片段组合在一起并测试组合后的代码时,您应该看到如下输出:
查看语音演示。
2、OpenAI:创建语音应用
OpenAI 允许开发人员通过两种方式将其语音服务集成到他们的应用中。使用其 Python Agents SDK 和 TypeScript SDK,您可以轻松地将语音代理添加到任何 AI 应用中。
该 SDK 支持男性和女性的 TTSVoices,如 Alloy、Ash、Coral、Echo、Fable、Onyx、Nova、Sage 和 Shimmer。通过其语音代理管道,您可以将音频输入转换为文本,运行顺序文本响应的工作流程,并将文本输出转换为流式音频。
使用 OpenAI 构建音频/语音体验的另一种方法是使用其 Realtime API。使用其 WebRTC 或 WebSockets 后端,开发人员可以构建支持实时文本和语音生成、转录、函数调用等的多模态体验。
使用 OpenAI 构建语音代理的一些独特功能包括以下内容:
- 工具:给予您的语音应用程序访问外部 服务 来执行操作。
- 代理监控:为语音代理提供 护栏 和规则。
- 代理交接:创建多个代理,他们可以相互分配任务。
- 音频处理:默认使用 WebRTC 处理音频输入/输出。
- 会话管理:允许配置和自定义实时会话。
2.1 使用 OpenAI JS SDK 开始
以下示例代码可以帮助您开始使用 OpenAI JS SDK 构建语音应用。查看 语音代理快速入门 以了解更多信息。
import { RealtimeAgent, RealtimeSession } from '@openai/agents/realtime';
const agent = new RealtimeAgent({
name: 'Assistant',
instructions: 'You are a helpful assistant.',
});
const session = new RealtimeSession(agent);
// 自动通过 WebRTC 在浏览器中连接您的麦克风和音频输出
// in the browser via WebRTC.
await session.connect({
apiKey: '<client-api-key>',
});
3、ElevenLabs:构建对话式语音代理
ElevenLabs 是构建对话式 AI 应用的领先平台之一。它为开发人员和企业提供所有构建低延迟语音代理的构建模块,以便与任何服务集成。
下面的例子展示了真实的文本到语音交互。
查看语音演示。
通过这个平台,您可以访问语音克隆、隔离、交换、语音设计和制作音效的 AI 模型类别。这些模型的组合可用于创建和部署交互式音频服务。
例如,截至本文撰写时,其最新模型(Eleven V3)是实现真实且富有表现力的内置文本到语音的绝佳选择。凭借其对不同类别语音模型的支持,您有多种选项适用于视频、音频、游戏、远程医疗和市场应用。
3.1 开始使用 ElevenLabs
快速集成 LLM! 我们的 UI 组件非常适合任何 AI 聊天机器人界面,开箱即用。今天就尝试一下,明天就推出!
ElevenLabs 为 Python 和 TypeScript 开发人员提供了易于使用的 SDK。下面的示例代码是您需要做的全部工作,以使用 Python 语音 AI SDK 进行第一次 API 调用,创建您的文本到语音应用。
from dotenv import load_dotenv
from elevenlabs.client import ElevenLabs
from elevenlabs import play
import os
load_dotenv()
elevenlabs = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY"),
)
audio = elevenlabs.text_to_speech.convert(
text="The first move is what sets everything in motion.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
play(audio)
查看 开发者快速入门 以了解 SDK 的 TypeScript 版本的更多信息。
4、Deepgram:构建语音 AI 解决方案
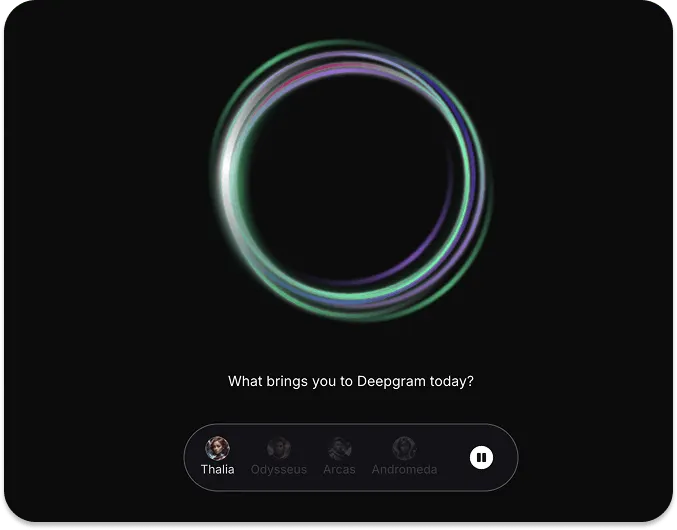
Deepgram 是一个语音 AI 应用创建平台。开发人员可以使用其 API 构建具有文本到语音、语音到语音和语音到文本模型的音频应用。要体验和看到 Deepgram 如何工作,请访问上面的 URL 并尝试主页上的交互式实时语音演示。
使用 Deepgram,您可以尝试不同的模型和 API 来构建针对客户服务、远程医疗、销售、服务订购等用例的智能音频应用。使用 Deepgram 最快的方式是尝试其 API 游乐场。
4.1 开始使用 Deepgram
使用 Deepgram 的一个优势是其 API 可用于 Python、JavaScript、C# 和 Go。要使用任何 Deepgram SDK 构建您的第一个语音代理,请配置您的环境并安装平台特定的 SDK。下面的示例命令适用于 Python。
要开始使用您首选的平台来实现语音代理,请前往 入门 指南。
mkdir deepgram-agent-demo
cd deepgram-agent-demo
touch index.py
export DEEPGRAM_API_KEY="your_Deepgram_API_key_here"
@TODO other Python commands
# 安装 SDK
pip install deepgram-sdk
查看语音演示。
5、Vapi:为开发人员构建语音 AI 代理

Vapi 平台帮助开发人员用 Python、React 和 TypeScript 构建和部署语音代理和 AI 产品。它提供了两种方式来创建智能语音应用。它的助手选项允许您创建简单的对话服务,这可能需要一个单一的系统提示来操作底层模型。
Vapi 助手的示例用例包括简单的问答系统和聊天机器人。如果一个代理系统有复杂的逻辑或涉及多步骤过程,您可以使用 Vapi 的工作流功能来构建您的代理。此类应用适合预约安排和服务订购。
Vapi 是开发人员和企业开发涉及实际电话号码的语音 AI 产品的绝佳选择。您可以将其与多个应用程序和模型提供商集成,例如 Salesforce、Notion、Google Calendar、Slack、OpenAI、Anthropic、Gemini 等。
- 多语言支持:API 支持多语言操作。这意味着您的应用程序的用户可以用英语、西班牙语和其他 100 多种支持的语言与代理交谈。
- 外部工具:轻松添加外部工具,让您的语音代理执行准确的操作。
- 自动化测试:使用模拟的 AI 语音创建生产就绪代理的测试套件。
- 插件任何模型:您可以带来您最喜欢的文本到语音、语音到文本和语音到语音模型,来自任何主要的 AI 服务提供商。
5.1 开始使用 Vapi
使用 Vapi 制作您的第一个语音 AI 应用或将其集成到现有应用中都很简单。下面的 React 示例代码可以帮您开始。
import Vapi from "@vapi-ai/web";
import { useState, useEffect } from "react";
export const vapi = new Vapi("YOUR_PUBLIC_API_KEY"); // 从仪表板获取您的公共 API 密钥
function VapiAssistant() {
const [callStatus, setCallStatus] = useState("inactive");
const start = async () => {
setCallStatus("loading");
const response = vapi.start("YOUR_ASSISTANT_ID"); // 从仪表板获取您的助手 ID
};
const stop = () => {
setCallStatus("loading");
vapi.stop();
};
useEffect(() => {
vapi.on("call-start", () => setCallStatus("active"));
vapi.on("call-end", () => setCallStatus('inactive'));
return () => vapi.removeAllListeners();
}, [])
return (
<div>
{callStatus === "inactive" ? (<button onClick={start}>Start</button>) : null}
{callStatus === "loading" ? <i>Loading...</i> : null}
{callStatus === "active" ? (<button onClick={stop}>Stop</button>) : null}
</div>
);
}
访问 vapi.ai 以尝试为其他平台制作语音代理。
6、Play.ai:构建实时智能语音应用
PlayAI 是一个为网页和移动设备制作智能语音应用的平台。该平台允许工程师为医疗保健、房地产、游戏、食品配送、EdTech 等创建语音代理。
要查看服务如何工作,请查看上面 URL 的交互式语音聊天演示或尝试 PlayNote 网络应用,它可以将 JPEG、PDF、EPUB、CSV 和其他几种文件转换为类似人声的音频格式。像其他平台一样,PlayAI 有一个 语音库 供您在应用程序中进行实验。
PlayAI 的 游乐场/沙盒 提供了实验、测试语音生成和构建音频体验的起点。
6.1 开始使用 PlayAI
您可以使用 PlayAI 的文本到语音 API 在 Bash、Python、JavaScript、Go、Dart 和 Swift 中。首先,在您的机器上设置 API 凭据。
# macOS (zsh)
echo 'export PLAYAI_KEY="your_api_key_here"' >> ~/.zshrc
echo 'export PLAYAI_USER_ID="your_user_id_here"' >> ~/.zshrc
source ~/.zshrc
# Windows
setx PLAYAI_KEY "your_api_key_here"
setx PLAYAI_USER_ID "your_user_id_here"
然后,使用此 Curl 脚本进行第一次 API 调用,以从文本提示创建音频:
curl -X POST 'https://api.play.ai/api/v1/tts/stream' \
-H "Authorization: Bearer $PLAYAI_KEY" \
-H "Content-Type: application/json" \
-H "X-USER-ID: $PLAYAI_USER_ID" \
-d '{
"model": "PlayDialog",
"text": "Hello! This is my first text-to-speech audio using PlayAI!",
"voice": "s3://voice-cloning-zero-shot/baf1ef41-36b6-428c-9bdf-50ba54682bd8/original/manifest.json",
"outputFormat": "wav"
}' \
在您的终端中运行上述内容应输出一个名为 hello.wav 的音频文件。
7、Pipecat:构建语音 AI 应用

Pipecat 是构建对话式 AI 应用最广泛使用的 开源 框架之一。该框架允许开发人员创建复杂的对话系统、企业级客户支持代理、多模态交互(视频、语音和图像)以及视频会议助手。
查看此 X 帖子 以查看 Pipecat 的实际演示。
Web、iOS、Android 和 C++ 的客户端 SDK 允许您使用多个 AI 服务、工具和底层后端技术(如 WebRTC 和 WebSockets)构建低延迟的对话应用。
7.1 开始使用 Pipecat
您可以通过配置环境、安装模块并在语音应用准备好投入生产时切换到云端来在本地运行 Pipecat。
# 安装模块
pip install pipecat-ai
# 设置您的环境
cp dot-env.template .env
有关更多代码示例和使用框架构建对话代理的详细说明,请参考 Pipecat 的 GitHub 仓库。
8、Cartesia:创建逼真的 AI 语音
Cartesia 是一个以开发人员为中心的语音 AI 平台。Cartesia API 使将高质量语音集成到任何产品中变得更加容易。它还提供无缝支持,将语音代理与其他平台(如 LiveKit、Vapi 和 Pipecat)扩展。您可以在 15 种以上的语言中构建语音应用,并在任何设备上部署它们。
要了解更多关于 Cartesia 如何工作的信息,您可以查看其 Sonic 文本到语音和 Ink-Whisper 语音到文本模型。
8.1 开始使用 Cartesia
根据您的机器,使用 Cartesia API 有一些安装要求。
# macOS
brew install ffmpeg
# Debian/Ubuntu
sudo apt install ffmpeg
# Fedora
dnf install ffmpeg
# Arch Linux
sudo pacman -S ffmpeg
在您的计算机上安装上述任意一项后,现在可以使用 cURL、Python 或 JavaScript/TypeScript 发起 API 调用,以从文本生成语音。
curl -N -X POST "https://api.cartesia.ai/tts/bytes" \
-H "Cartesia-Version: 2024-11-13" \
-H "X-API-Key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{"transcript": "Welcome to Cartesia Sonic!", "model_id": "sonic-2", "voice": {"mode":"id", "id": "694f9389-aac1-45b6-b726-9d9369183238"}, "output_format":{"container":"wav", "encoding":"pcm_f32le", "sample_rate":44100}}' > sonic-2.wav
要进一步探索,您可以尝试 Cartesia 的 Python 和 TypeScript SDK。
9、语音代理、框架、平台和未来
目前,有许多框架、平台和工具可用于在消费者应用中添加对话式语音 AI 代理。本文涵盖了八个平台,您可以立即使用它们来制作语音 AI 产品。
还有其他出色的的服务,如 LiveKit、Kokoro TTS 和 Moonshine,用于创建语音应用。您还可以使用 Unmute.sh 和 OpenAI.fm 平台来试验和测试自然且逼真的 AI 语音库。
为了为特定用例(如电话操作)制作语音应用,您可以使用 Bland AI、Retell AI 和 Synthflow AI 等服务。如果您想尝试开源 TTS 模型,请查看 Chatterbox TTS 和 Hugging Face Spaces 上的 语音合成 类别。
尽管本文涵盖的所有平台都提供了听起来自然的人类语音,但许多平台在与代理交互时存在高延迟。一些平台不能正确处理中断和嘈杂条件。例如,许多平台在理解用户的声音时会有困难,尤其是在婴儿或孩子在背景中玩耍和说话时。
随着这个 AI 领域的不断改进,未来的语音模型、API 和 SDK 将增强它们的中断能力、噪声检测,并确保低延迟的语音到语音、语音到文本和文本到语音交互。这些语音/音频服务平台的大部分都是闭源的。随着语音 AI 领域的迅速变化,将出现越来越多的开源替代品来与闭源平台竞争。
原文链接:The 8 Best Platforms To Build Voice AI Agents
汇智网翻译整理,转载请标明出处
