用强化学习训练AI代理
即使是非常强大的LLM也可能很难可靠地完成复杂的多轮代理任务。有趣的是,我们发现使用一种叫做GRPO(群体相对策略优化)的强化学习算法来训练代理可以使它们更加可靠!

学习如何使用强化学习(RL)训练AI代理以完成现实世界任务。
“代理”AI正变得越来越流行。在此背景下,“代理”是指一个被赋予高层次目标和一组工具来实现它的LLM。代理通常是“多轮”的——它们可以执行一个动作,看到它对环境的影响,然后重复执行另一个动作,直到达到目标或失败。
不幸的是,即使是非常强大的LLM也可能很难可靠地完成复杂的多轮代理任务。有趣的是,我们发现使用一种叫做GRPO(群体相对策略优化)的强化学习算法来训练代理可以使它们更加可靠!在这个指南中,你将学习如何使用开源工具构建可靠的AI代理。
1、使用ART训练RL代理
ART(代理强化训练器)基于Unsloth的GRPOTrainer,是一个使训练多轮代理成为可能且简单的工具。如果你已经在使用Unsloth进行GRPO,并且需要训练能够处理复杂多轮交互的代理,ART可以简化这个过程。
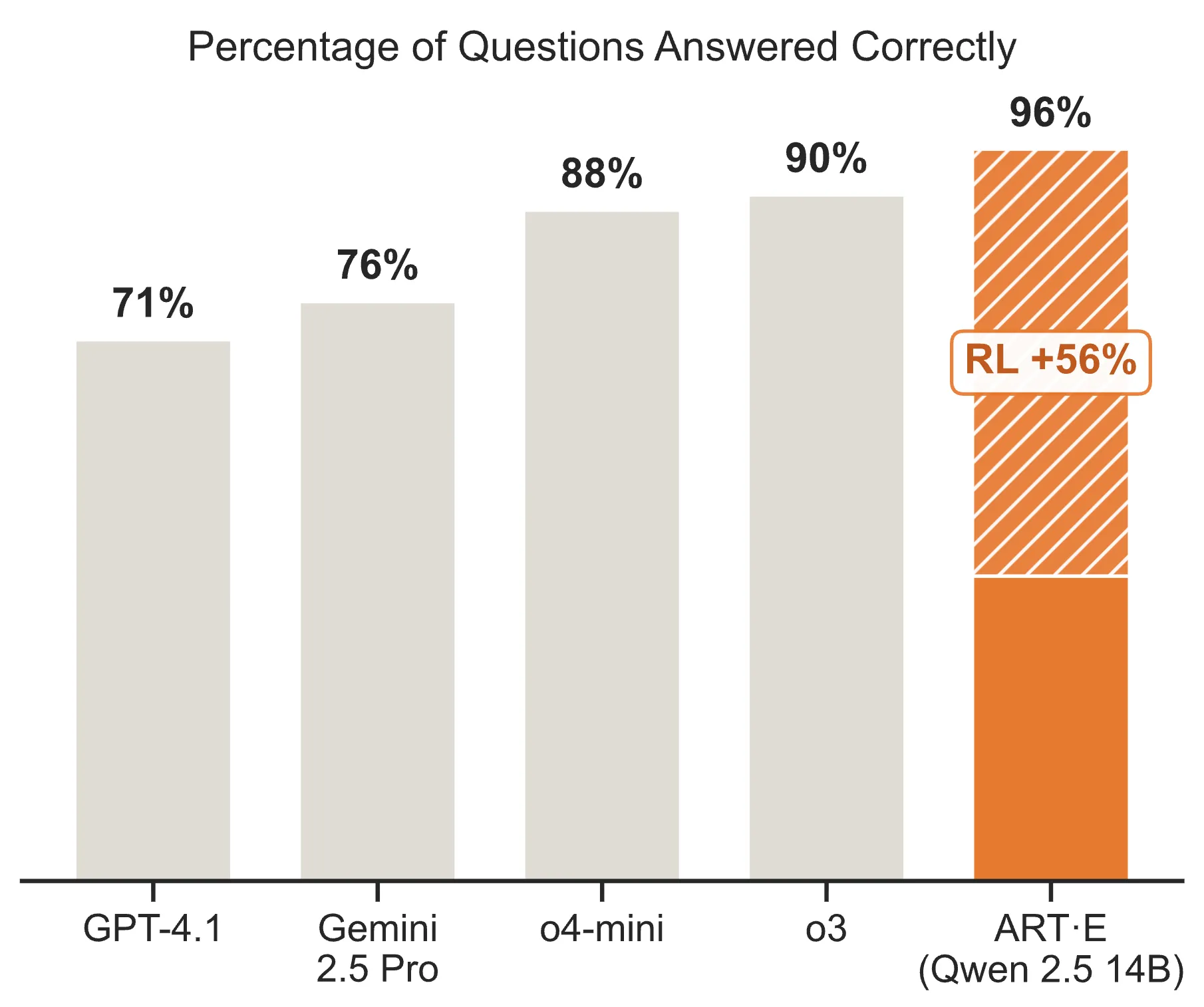
使用Unsloth+ART训练的代理模型通常能够在代理工作流中表现优于提示模型。
2、ART + Unsloth
ART建立在Unsloth的内存和计算高效的GRPO实现之上。此外,它还增加了以下功能:
2.1 多轮代理训练
ART引入了“轨迹”的概念,这是随着代理执行而逐步构建的。这些轨迹随后可以评分并用于GRPO。轨迹可以很复杂,甚至包括非线性历史记录、子代理调用等。它们还支持工具调用和响应。
2.2 灵活集成到现有代码库中
如果你已经有一个使用提示模型工作的代理,ART会尽量减少你需要做出的更改,以便包装你的现有代理循环并将其用于训练。
从架构上看,ART分为一个“前端”客户端,它存在于你的代码库中,并通过API与“后端”通信,实际训练发生在“后端”(如果愿意,这些也可以在同一台机器上共存,使用ART的LocalBackend)。这带来了一些关键优势:
- 所需的设置最少:ART前端依赖项很少,可以轻松添加到现有的Python代码库中。
- 从任何地方训练:您可以在笔记本电脑上运行ART客户端,并让ART服务器启动一个临时的GPU启用环境,或者在本地GPU上运行。
- OpenAI兼容API:ART后端通过一个OpenAI兼容的API为您提供正在训练的模型,这与大多数现有代码库兼容。
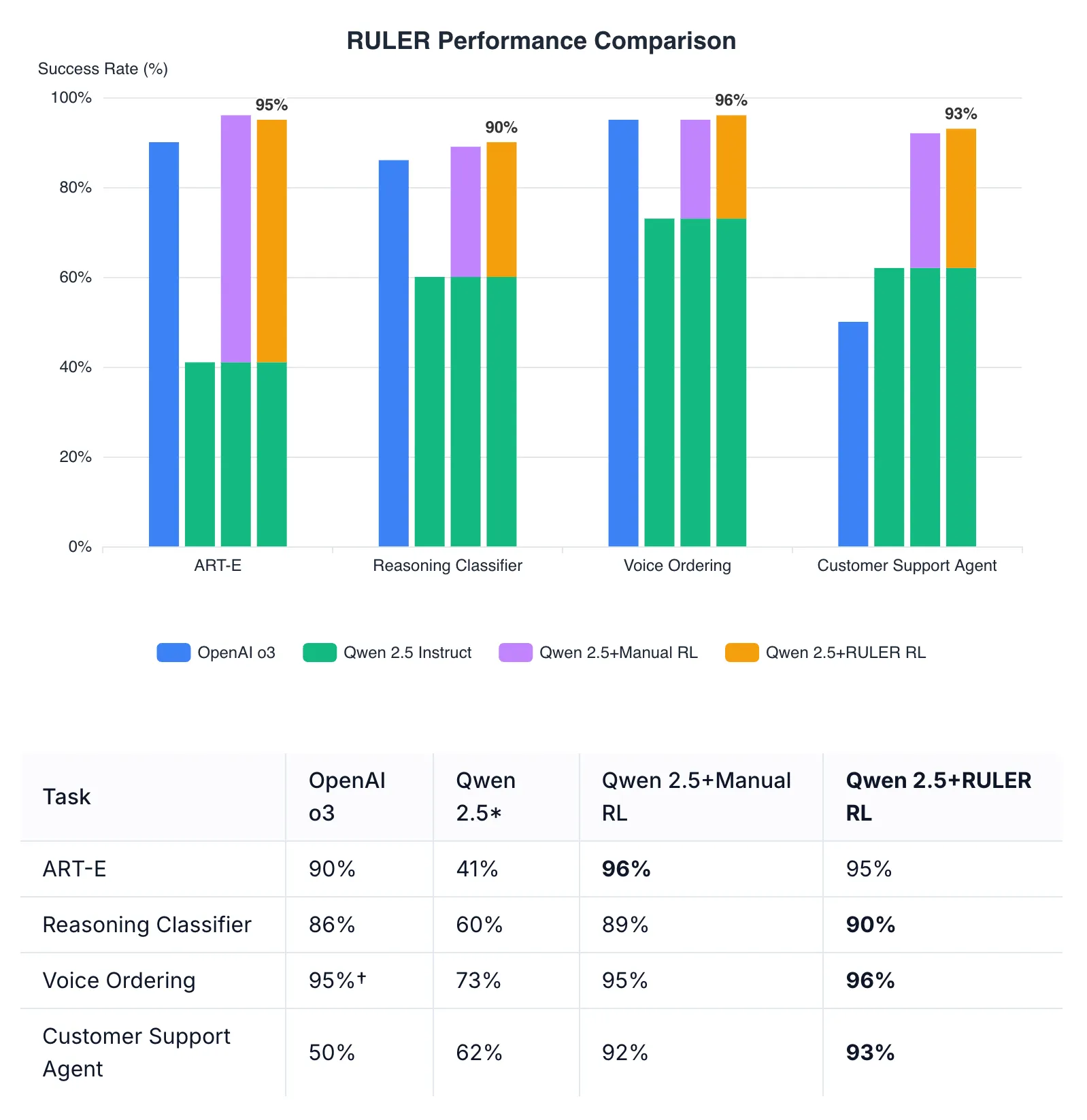
2.3 RULER:零样本代理奖励
ART还提供了一个内置的通用奖励函数,称为RULER(相对通用LLM诱发奖励),它可以消除对手动编写奖励函数的需求。令人惊讶的是,使用RULER自动奖励函数进行RL训练的代理通常能与使用手动编写奖励函数训练的代理相媲美或超越其性能。这使得开始RL更容易。
# 之前:数小时的奖励工程
def complex_reward_function(trajectory):
# 50多行精心评分逻辑...
pass
# 之后:一行使用RULER
judged_group = await ruler_score_group(group, "openai/o3")
2.4 何时选择ART
ART可能适合需要以下条件的项目:
- 多步骤代理功能:当你的用例涉及需要执行多个动作、使用工具或进行长时间对话的代理时
- 快速原型开发而无需奖励工程:RULER的自动奖励评分可以将项目的开发时间缩短2-3倍
- 与现有系统集成:当您需要向现有的代理代码库中添加RL功能,而只需最小的更改时
3、代码示例:ART实战
import art
from art.rewards import ruler_score_group
# 使用Unsloth支持的基础模型初始化模型
model = art.TrainableModel(
name="agent-001",
project="my-agentic-task",
base_model="Qwen/Qwen2.5-14B-Instruct", # 任何Unsloth支持的模型
)
# 定义您的rollout函数
async def rollout(model: art.Model, scenario: Scenario) -> art.Trajectory:
openai_client = model.openai_client()
trajectory = art.Trajectory(
messages_and_choices=[
{"role": "system", "content": "..."},
{"role": "user", "content": "..."}
]
)
# 您的代理逻辑在这里...
return trajectory
# 使用RULER进行自动奖励训练
groups = await art.gather_trajectory_groups(
(
art.TrajectoryGroup(rollout(model, scenario) for _ in range(8))
for scenario in scenarios
),
after_each=lambda group: ruler_score_group(
group,
"openai/o3",
swallow_exceptions=True
)
)
await model.train(groups)
4、开始使用ART
要将ART添加到你的Unsloth项目中:
pip install openpipe-art # 或 `uv add openpipe-art`
然后查看示例笔记本,了解ART在诸如以下任务中的实际应用:
- 超过o3的电子邮件检索代理
- 游戏-playing代理(2048、井字棋、连环杀手)
- 复杂推理任务(时间线索) 上一强化学习 - DPO, ORPO & KTO下一文本到语音(TTS)微调
原文链接:Training AI Agents with RL
汇智网翻译整理,转载请标明出处
