Unsloth: 从LoRA到完整微调
过去几年,训练大型语言模型 (LLM) 就像一个封闭的社区——只有拥有庞大 GPU 集群和数百万美元预算的公司才能进入。

过去几年,训练大型语言模型 (LLM) 就像一个封闭的社区——只有拥有庞大 GPU 集群和数百万美元预算的公司才能进入。
但这堵墙终于开始瓦解了。
Unsloth AI 的最新更新使训练速度提升了三倍,并且在消费级 GPU 上节省了 30% 到 90% 的显存 (VRAM)——所有这些都没有损失精度。
这彻底改变了游戏规则。我们正在从“谁能负担得起训练费用?”转变为“谁能以最快的速度迭代?”
这一变化对 LLM 的未来发展有着重大影响。
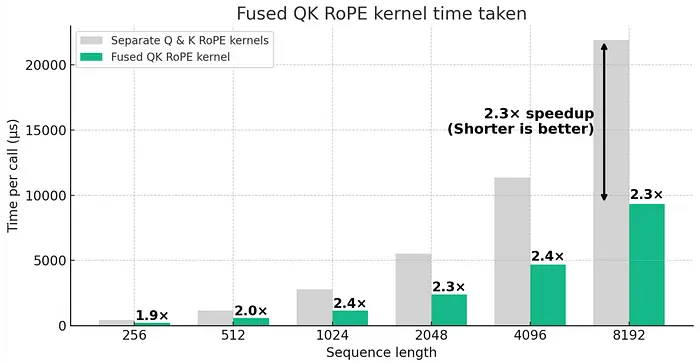
1、为什么这在当下如此重要
此前,大多数独立开发者依赖于 LoRa 微调,因为训练完整模型的成本太高。
但如果能够在 4GB GPU 上训练一个 40 亿模型——并且速度提升三倍——游戏规则将彻底改变。
突然之间:
- 更多人可以尝试架构变更
- 完整的微调变得触手可及
- 迭代周期大幅缩短
- 创新变得更加分散
这不仅使训练更加民主化——它还加速了整个竞赛。
历史告诉我们接下来会发生什么:
当训练成本降低 3 倍时,实验数量会增加 3 倍……但模型规模却会增长 10 倍。
这两种趋势同时发生。
这就引出了下一个问题……
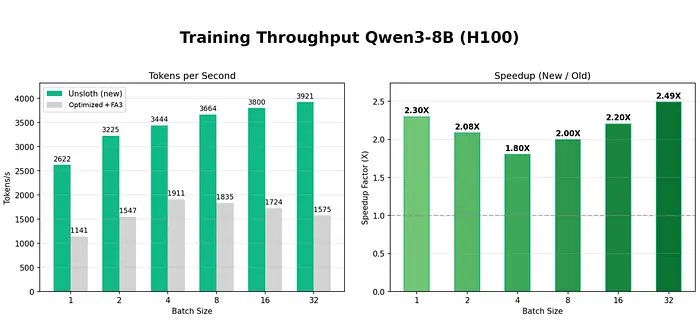
2、新的瓶颈:数据与评估
快速训练固然好。快速但糟糕的训练呢?那就未必了。
随着训练速度的提升,根本瓶颈转移到了:
- 数据质量
- 数据集管理
- 评估速度
- 人工验证
如果没有有效的评估流程,训练速度提升 3 倍只会导致生成平庸模型的速度也提升 3 倍。
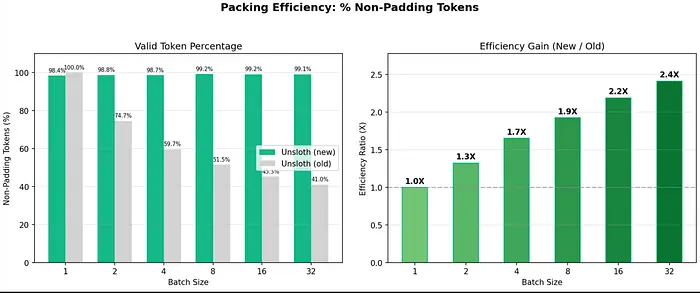
3、Unsloth 最新发布
Unsloth 为 RoPE 和 MLP 引入了新的 Triton 内核,以及一项名为智能自动打包的重大突破。
对实际用户而言,这意味着:
- LLM 训练速度提升 3 倍
- 节省 30% 至 90% 的显存 (VRAM)
- 仅需 3.9GB 显存即可训练 Qwen3-4B 数据集
- 兼容旧款 GPU(T4、2080)和新款 GPU(H100、B200)
- 精度无损失
这是大家期待已久的升级。
4、打包为何是真正的杀手级功能
传统上,当数据集包含不同长度的序列时,批处理会降低训练速度。
原因是:
长样本需要所有批次项长度相同——这会导致不必要的填充——从而降低训练速度并消耗更多显存。
Unsloth 的全新打包系统解决了这个问题。
与其这样低效:
[Short] [Padding...]
[Short] [Padding...]
[Long sentence...........]
[Short] [Padding...]不如这样:
[Short][Short][Long sentence][Short]所有内容都紧密排列,避免了分散注意力。
仅此一项即可带来:
- 典型数据集速度提升 2 倍
- 当数据集包含大量短序列时,速度提升高达 5 倍
5、速度提升背后的数学原理
假设您的数据集中 50% 为短序列,50% 为长序列:
不使用打包:
Tokens per batch = batch_size × longest_length
使用打包:
Tokens per batch = 0.5 × batch_size × L + 0.5 × batch_size × S
当短序列长度 S 较小时:速度提升 — 约 2 倍
当大多数序列为短序列时:速度提升 — 高达 5 倍
基准测试也证实了这些提升。
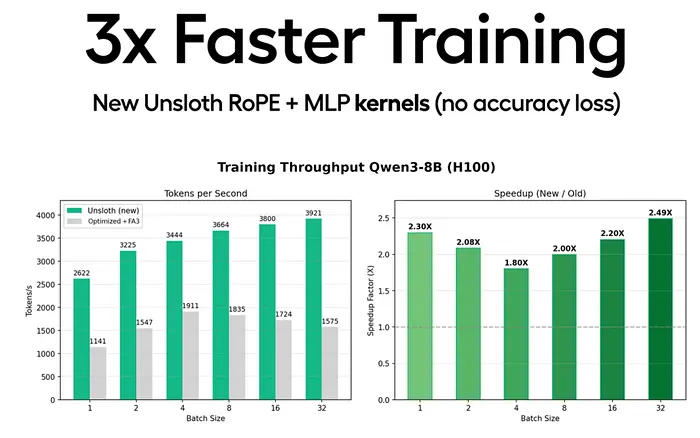
6、基准测试:有哪些变化?
Unsloth 使用 Qwen3-32B、Qwen3-8B 和 Llama 3 8B 等模型观察到:
- 训练速度提升 1.7 倍至 3 倍(有时甚至高达 5 倍)
- 训练损失不变
- 梯度更加稳定
- 填充标记更少
- 显存占用降低 30% 至 60%
举例来说:
使用填充技术训练 40% 的训练时间与不使用填充技术训练 5% 的训练时间相同。
这种效率提升立竿见影。
7、如何启用打包功能
首先,更新 Unsloth:
pip install --upgrade --force-reinstall --no-cache-dir --no-deps unsloth
pip install --upgrade --force-reinstall --no-cache-dir --no-deps unsloth_zoo然后启用打包功能:
from unsloth import FastLanguageModel
from trl import SFTTrainer, SFTConfig
model, tokenizer = FastLanguageModel.from_pretrained(
"unsloth/Qwen3-14B",
)
trainer = SFTTrainer(
model = model,
processing_class = tokenizer,
train_dataset = dataset,
args = SFTConfig(
per_device_train_batch_size = 1,
max_length = 4096,
packing = True, # 🪄 The magic switch
),
)
trainer.train()完成!打包功能现已全面启用。
8、这对未来意味着什么
我们正进入LLM时代的新阶段:
- 第一阶段:提示工程
成本低、即时、无需投入。
- 第二阶段:LoRa微调
价格实惠但功能有限。
- 第三阶段:在消费级GPU上进行全模型训练
我们已迈入这一阶段。
一旦训练速度提升至3倍,成本降低50-90%,对4GB以下显存友好,我们将从使用提示工程转向构建模型。
技能门槛降低。实验理论上限提升,创新速度加快。
现在唯一的问题是:
这会促进模型开发的民主化,还是会加速军备竞赛?
或许两者兼而有之。
但有一点可以肯定:
“小团队训练大模型”的时代已经正式开启。
原文连接:The Consumer GPU Fine-Tuning Boom Just Arrived — And It's About to Change Everything
汇智网翻译整理,转载请标明出处
