VibeVoice:超长输出TTS
VibeVoice是一个免费的NotebookLM替代品,其模型形式覆盖了非常长的演讲和多轮对话。

我对2025年最感兴趣的一件事是音频AI的崛起。我们已经看到一系列TTS模型、对话AI、音乐生成模型相继发布,现在微软这个巨头也加入了竞争,并推出了VibeVoice,这是一个免费的NotebookLM替代品,其模型形式覆盖了非常长的演讲和多轮对话。
1、什么是VIBEVOICE?
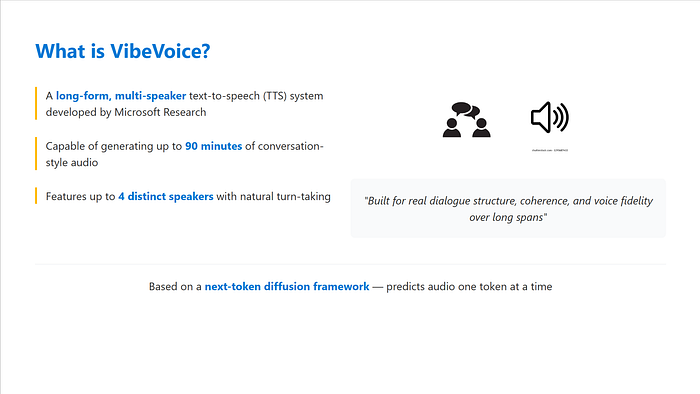
VIBEVOICE是由微软研究院开发的一种长篇、多说话人的文本到语音(TTS)系统。
它能够生成长达90分钟的对话式音频,包含多达4个不同的说话人,并且质量高,具有自然的轮流发言。
它基于一个下一个标记扩散框架,意味着它通过扩散过程逐个标记预测音频,而不是传统的采样方法。
这不是某种播客语音克隆的噱头,它是为长时间的真实对话结构、连贯性和语音保真度而构建的。
2、它的独特之处是什么?


- 超长上下文:处理64K上下文窗口,支持长达90分钟的音频。
- 多说话人支持:单次会话中最多支持4个不同的说话人,并具有真实的来回动态。
- 混合分词器系统:结合了**声学(基于VAE)和语义(基于ASR)**分词器。
- 压缩大师:仅需7.5个标记/秒即可实现3200倍压缩,意味着快速生成且计算资源消耗极低。
- 无需每个说话人单独的语音模型:它使用文本+语音提示+说话人ID,全部嵌入在一个流中。
- 下一个标记扩散:采用逐标记扩散头,使生成更平滑、高质量,并有更好的噪声建模。
- 简单的输入设计:您只需提供一个连接的输入,包括语音提示嵌入和由说话人标记的文本脚本。
3、它是如何工作的
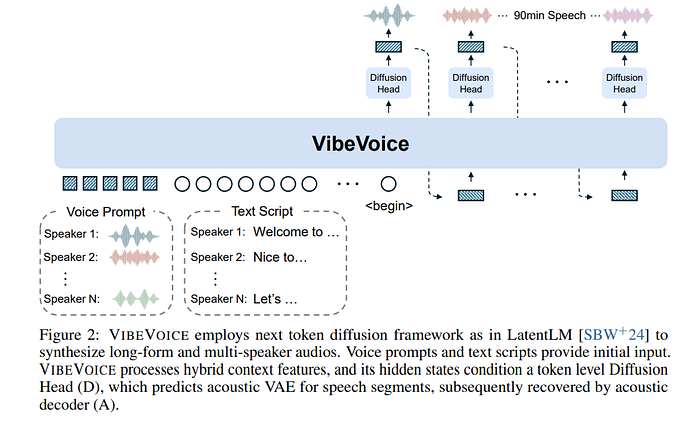
核心:
输入:您提供以下内容的组合:
- 每个说话人的简短语音提示(zN)
- 每个说话人的文本脚本(TN)
- 用角色ID如“说话人1”、“说话人2”等进行标记。
分词:
- 音频通过两个分词器进行处理:
- 声学分词器:一种VAE(实际上是σ-VAE变体),在保持质量的同时大幅压缩音频。
- 语义分词器:像ASR模型一样训练,捕捉“内容”(what),而不仅仅是“声音”(how)。
语言模型(LLM):
- 它使用Qwen2.5(1.5B或7B),经过训练以处理长的多模态序列。
- 输入通过这个LLM。
扩散解码器:
- 不是直接输出音频,而是一个小的扩散头接收每个标记的隐藏状态并逐步去噪。
- 最终音频通过将VAE标记转换回波形的解码器重建。
输出:您得到干净、自然的语音,跨说话人的流畅性良好,时间真实。
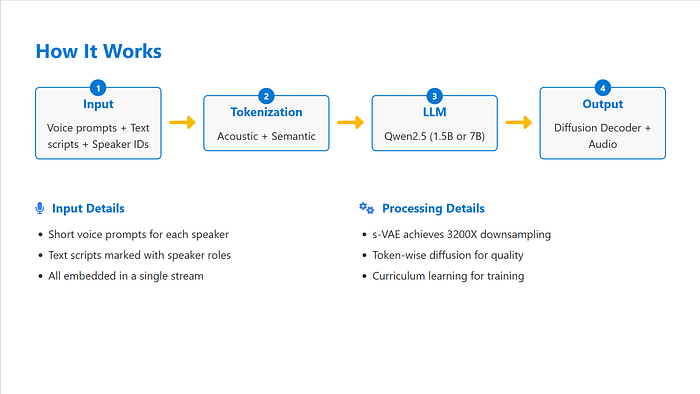
架构总结
分词器:
- 声学:σ-VAE,基于Transformer,3200倍下采样。
- 语义:基于Transformer的编码器 + ASR风格解码器(训练后丢弃)。
- 核心模型:预训练的Qwen2.5 LLM(1.5B或7B参数)
- 解码器:轻量级的4层扩散头 + VAE解码器。
训练:
- 分词器被冻结。
- 仅训练LLM和扩散头。
- 使用课程学习(从较短的序列开始,逐渐增长到64K个标记)。
- 无分类器引导在推理期间提高质量。
4、基准测试
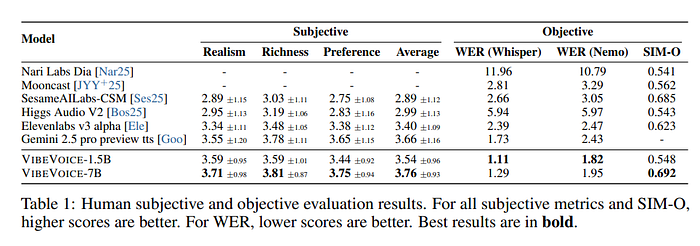
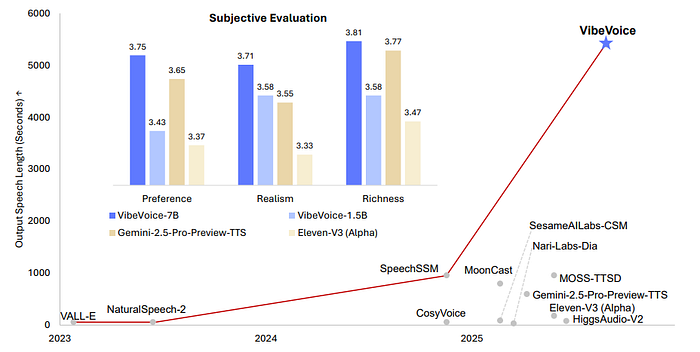
VIBEVOICE 7B在所有3个人类评判类别中都超过了Gemini和ElevenLabs等专有和开源系统。
分词器质量(LibriTTS测试集):
- PESQ(感知质量):3.068(干净),2.848(其他)
- UTMOS(主观自然度):4.181(干净),3.724(其他)
- 分词率:仅7.5个分词/秒
它们在压缩音频到极端程度的同时,远远超越了大多数现有的分词器。
主要限制:
- 语言:仅支持英语和中文。
- 无背景音:只有纯语音,没有音乐或音效。
- 无重叠语音:说话人不会互相打断。
- 安全性:可能被滥用为深度伪造或冒充。
微软明确反对在没有进一步防护措施的情况下进行商业部署。
5、如何免费使用Vibe Voice?
该模型有两种版本,1.5B和7B,权重是开源的。
VIBEVOICE不仅仅是一个TTS模型。它正在推动长篇对话合成的边界,通过一个干净、模块化的架构,融合了音频压缩、语言建模和扩散生成。而且由于7.5Hz的分词,它在资源使用上并不臃肿。
就扩展性和对话质量而言,这可能是目前最适合播客、有声书或合成对话的最佳公开系统。
原文链接:Microsoft VibeVoice : Best Free TTS for long speech, multi speaker conversations
汇智网翻译整理,转载请标明出处
