视觉AI驱动的冶金管道计数器
在本文介绍作者开发移动应用PipesCounting的经验,该应用使用视觉AI模型自动计算一束管道的数量。

在本文中,来自Letovo学校的一群11年级学生想分享我们开发移动应用PipesCounting的经验,该应用用于自动计算一束管道的数量。在6个月的时间里,我们从想法到发布应用程序,包括收集和扩展数据集、训练模型以及构建应用程序。在这里,我们想分享我们的经验以及我们遇到的困难,以便为那些将要进行类似工作的人提供便利。
通过PipesCounting应用程序,我们在“冶金”类别中获得了国际AI初级竞赛的二等奖,并将其带到了AI Journey国际会议。
1、我们想要构建什么
我们决定开发一个带有模型的应用程序,用于计算一束管道的数量,适用于冶金生产。该模型必须在没有互联网连接的情况下运行,平衡识别质量和速度。同时,模型集成到应用程序中所需的资源也很少:该应用程序是为生产使用而设计的,在那里并非所有设备都有高性能计算能力。
鉴于这些要求,我们选择了YOLOv8:该模型非常适合识别不同对象,易于微调特定类别的模型,并且其速度允许在性能和质量之间取得良好的平衡。
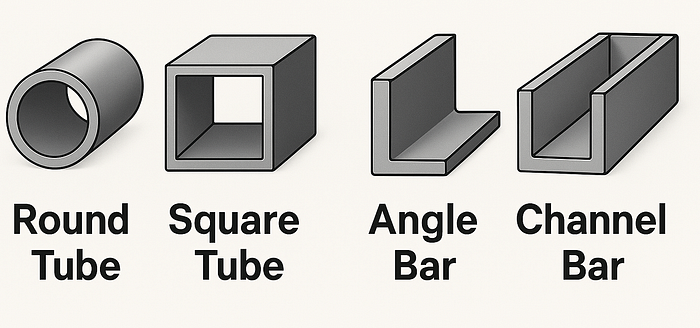
2、数据
我们开始构建一个可以识别四种最常用于生产的管道的应用程序:圆形、方形、角形和槽形(见图1)。对于圆形和方形管,我们找到了一些开源的标记数据集用于模型训练。然而,对于角钢和槽钢,根本没有可用的开源标记数据集。
解决方案很简单但劳动密集:五个人使用CVAT手动标记了大约12,000个角钢和槽钢。尽管如此,这仍然不足以进行完整的训练,所以我们求助于扩展数据集,使用以下方法:
2.1 增强
由于数据量有限,而且为了控制标记图像的数量,我们使用了增强——通过原始图像的简单变换来人工扩展数据集。
对于管道增强,我们选择了以下方法:
- 翻转 —— 在保留管道堆叠逻辑的同时使数据集翻倍。
- 旋转(±15°)—— 教授模型处理小的相机倾斜。
- 亮度/曝光度 —— 模拟车间的阴影和眩光。
- 模糊 —— 使模型对移动相机的模糊帧具有鲁棒性。
- 马赛克 —— 将4张图像组合成一张,创建复杂的场景。
2.2 合成数据
解决缺乏标记数据的另一种方法是用预定义标签生成合成图像。首先,对于每张合成图像,我们选择一个分辨率和一个生产背景,从预先选择的照片中选取。然后,我们根据三种模式之一放置真实管道的剪切端:
a) 无模式
管道随机旋转并散布在图像中。有助于识别单个管道或捆绑外的管道。

b) 有简单模式
管道按行堆叠,但不相互嵌套——有助于识别这样的捆绑。

c) 有复杂模式
管道相互嵌套,如大多数真实捆绑一样。

我们还对管道图像应用了CutOut和Blur,以减少过拟合到特定合成数据的风险。合成数据的一个巨大优势是即时注释(边界框),这消除了团队的手动注释。
3、我们得到了什么?
这是我们在收集和“膨胀”数据后获得的数据集大小。
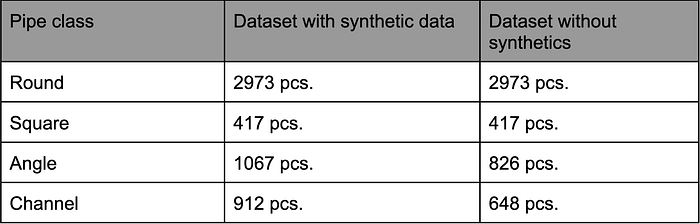
这是我们可以获得的数据集的一些图像示例。

这是我们自己标记并用于训练的最终数据集(经过增强,但没有合成)。目前,这是唯一包含角钢和槽钢的开源标记数据集。
3、YOLO训练
为了让应用程序在生产中有效,我们的团队尝试加快模型的推理速度。第一个想法是降低输入图像的分辨率。实验发现,当将分辨率从640×640降低到480×480时,推理时间大约减半(见图5)。同时,检测质量显然下降,因此在速度和准确性之间选择平衡很重要。

此外,即使人工增加了数据集,也并没有很多独特的图像,因此为了降低过拟合的风险,我们限制在一个数据集上进行50个周期的训练。
结果,我们得到了以下训练结果:
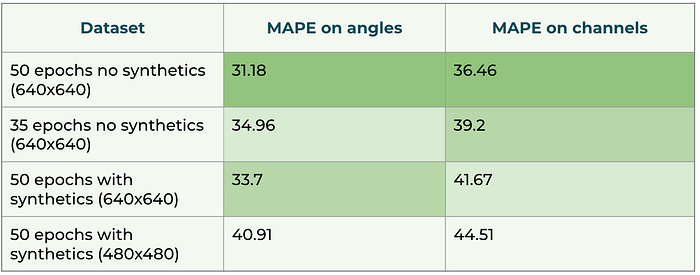
正如预期的那样,高分辨率图像提供了更好的质量。令人意外的是,合成数据并没有带来增益,甚至在某些地方比“有机”数据更差。这可以解释为图像的现实感较弱,以及可能的均匀性(背景图像和管道末端有限)。
4、将图像分成四部分并进行后处理:
在分析结果时,我们注意到一个有趣的模式:模型能够自信地处理一定数量的管道的捆绑,但当超过这个阈值时,质量急剧下降——有些物体根本无法被检测到。

为了解决这个问题,我们提出了一个想法,将图像分成四个部分,稍有重叠,并在每个部分上单独运行YOLO(见图7)。之后,我们通过确定一个管道中心到另一个管道边缘的距离来找到所有重叠的管道;在重叠的管道中,只保留较大的那个。

此外,照片中的一束管道应该大致相同大小。因此,为了过滤掉异常值,我们删除了那些明显大于或小于照片中所有管道平均大小的管道。为此,我们找到了所有管道的中位面积,并删除了与中位面积差异很大的管道。这有助于在密集堆栈上稳定计数,并减少大型捆绑的遗漏。


5、应用程序开发
下一步是开发一个Android移动应用程序,允许应用训练好的模型。该应用程序应让用户提供快照或从图库中选择照片,将其传递给模型,并在几秒钟内得到管道计数。
我们的团队决定使应用程序完全离线,因为生产中可能没有互联网。这个决定是一个严重的限制:你不能将模型上传到Hugging Face Spaces并通过API调用它;相反,模型必须直接嵌入到应用程序中。
由于我们使用的模型是一个经过微调的YOLO,并带有Python中的后处理,我们决定使用Kivy框架进行应用程序开发。它不是移动开发的典型框架,但它简化了我们产品的ML部分的集成。为了构建应用程序本身,我们选择了捆绑的Buildozer实用程序。
在第一个月里,所选策略似乎很成功:Kivy标记语言与其他标记语言差别不大(它类似于HTML和CSS的混合),功能足够——访问相机、图库、捕获帧并随后进行处理都实现了没有特别的问题。因此,整个应用程序功能逐步成功实现(布局和界面如下所示)。

最后一步是为Android构建应用程序。首先,我们遇到了指定较少流行库的构建要求的困难,例如Ultralytics(YOLO库),Buildozer中没有现成的安装“配方”。
为了保持应用程序大小在100 MB以内,我们迅速放弃了将PyTorch打包到应用程序中(这会使大小增加到约1.5 GB)。相反,我们使用了TensorFlow Lite(LiteRT),专门用于部署;幸运的是,YOLO权重可以导入此格式。有了它,APK大小又回到了70 MB。但是,一个新的任务出现了:在Ultralytics之外使用YOLO权重需要手动实现预处理/后处理(包括非最大抑制)。我们使用了OpenCV:通过Buildozer构建另一个库需要大量时间和故障排除,因此我们更喜欢使用已安装的库。幸运的是,必要的OpenCV代码位于Ultralytics存储库中的教程中。
当然,从完成的Python项目到准备好的APK和上传到Google Play的AAB文件,还有许多困难:Android NDK版本的问题、需要“签名”最终文件以及不同Android版本对图库访问权限的不同列表。尽管如此,最终还是得到了一个可工作的APK。
6、结束语
最终,我们得到了一个完全自主的移动应用程序,内置YOLO模型,能够在生产现场离线检测四种类型的管道。
在几个月的应用程序开发过程中,我们手动标记了数据,应用了增强和合成数据生成来扩展数据集,训练了YOLO模型,开发了后处理,并将其打包成离线应用程序。
在这个过程中,我们遇到了无数的技术挑战——从数据集不平衡到在有限硬件上的部署——但每一个挑战都让我们学到了关于完整AI开发周期的新东西。
如今,Pipes Counting作为一个紧凑的离线AI工具,准备好用于实际工业用途。我们的下一步计划是改进合成数据生成,扩大识别的轮廓范围,并将应用程序适配到iOS。
原文链接:Developing Pipes Counting: How to Build an Offline AI Tool for Metalurgy
汇智网翻译整理,转载请标明出处
