vLLM快速入门
vLLM 是一个用于快速高效部署大型语言模型(LLMs)的开源库。它特别优化了高吞吐量推理,使其在生产环境中部署语言模型时非常受欢迎。

vLLM 是一个用于快速高效部署大型语言模型(LLMs)的开源库。它特别优化了高吞吐量推理,使其在生产环境中部署语言模型时非常受欢迎。
vLLM解决的关键问题是,LLMs通常需要大量的计算和内存资源,尤其是在同时处理大量用户请求时。传统方法可能较慢,并导致硬件利用率低下。
分页注意力机制 是vLLM的核心创新。受操作系统中虚拟内存和分页概念的启发,分页注意力机制能够更有效地管理LLMs中注意力机制使用的内存(即KV缓存)。
与传统的将每个提示的KV缓存强制存储在一个长而连续的缓冲区不同,分页注意力机制将缓存分成固定大小的页面(GPU块),并维护一个轻量级的页面表,告诉注意力内核每个令牌的KV向量存储在哪里。因此,内核可以在运行时跳转到正确的页面,就像操作系统通过虚拟内存解析地址一样。
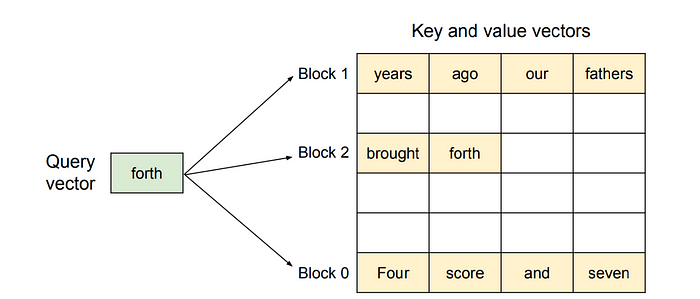
页面池 — KV张量存储在GPU内存中的块中(例如,16个令牌×隐藏维度)。
页面表 — 每个序列保持一个小列表,将其逻辑令牌索引映射到物理页面。
注意力内核 — 当新的查询向量到达(绿色框)时,内核:
- 查找包含相关键值的页面(橙色块)。
- 将这些页面流式传输到片上寄存器/共享内存中。
- 正如标准注意力机制一样,计算softmax加权和。
由于页面不需要相邻(见图中的块0/2/1跳跃),即使它们以不同的速度解码,运行时也可以密集地打包数千个请求。
有几种安装方法,具体取决于设备(请参阅文档)。在这里,我正在我的带有M1芯片的MacBook Air上安装它。
我正在创建一个新的文件夹,在其中设置一个新的Python环境,并激活该环境。
mkdir vllm_trials
cd vllm_trails
python3 -m venv venv
source venv/bin/activate
要安装vllm包:
pip install vllm
vLLM目前支持的模型列表可以查看这里。
要服务任何模型(在我们的例子中是Microsoft的Phi-1.5),我们可以使用以下命令:
vllm serve microsoft/phi-1_5 --trust-remote-code
此命令会在http://0.0.0.0:8000/上启动一个本地OpenAI兼容API服务器,从Hugging Face Hub加载microsoft/phi-1_5模型。
--trust-remote-code标志允许vLLM执行模型存储库提供的自定义模型代码,这对于实现自己架构或分词器的模型是必要的。
我们可以使用OpenAI兼容的Python SDK连接到本地vLLM服务器。
from openai import OpenAI
# 修改OpenAI的API密钥和API基础URL以使用vLLM的API服务器。
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
completion = client.completions.create(model="microsoft/phi-1_5",
prompt="San Francisco is a")
print("Completion result:", completion)
Completion result: Completion(id='cmpl-1654077731064a7a8a259d89b8d28566',
choices=[CompletionChoice(finish_reason='length', index=0, logprobs=None,
text=" city that's been around for hundreds of years, and it's still growing and",
stop_reason=None, prompt_logprobs=None)], created=1748883580,
model='microsoft/phi-1_5', object='text_completion',
system_fingerprint=None, usage=CompletionUsage(completion_tokens=16,
prompt_tokens=4, total_tokens=20, completion_tokens_details=None,
prompt_tokens_details=None), kv_transfer_params=None)
我们还可以使用原生的vllm Python API。
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="microsoft/phi-1_5")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
...
Prompt: 'Hello, my name is', Generated text: ' Sarah and I am a hairdresser! Today, I am going to'
Prompt: 'The president of the United States is', Generated text: ' the most powerful position in the country. However, there are other positions that hold'
Prompt: 'The capital of France is', Generated text: ' Paris, because it is the most famous city in the world."\n\nAn'
Prompt: 'The future of AI is', Generated text: ' bright and promising, as it has the potential to revolutionize many industries and improve'
要将vllm后端集成到LangChain中,我们可以使用langchain_community.llms模块中的VLLM类。这使我们能够在运行高性能本地LLM(如microsoft/phi-1_5)的同时利用LangChain的工具——如链、代理和文档加载器。
from langchain_community.llms import VLLM
llm = VLLM(
model="microsoft/phi-1_5",
trust_remote_code=True, # 对于hf模型是必需的
max_new_tokens=128,
top_k=10,
top_p=0.95,
temperature=0.8,
)
print(llm.invoke("What is the capital of France ?"))
...
法国的首都是巴黎。
当需要高效地服务大型模型时,vLLM尤其有价值,因为它可以显著提高吞吐量,相比标准推理方法。
它已成为许多组织大规模部署LLMs的首选解决方案,提供了性能、灵活性和易用性之间的良好平衡。
原文链接:vLLM: A Quick Start
汇智网翻译整理,转载请标明出处